 NLP:谷歌Transformer再升级
NLP:谷歌Transformer再升级
当我们在翻译软件上输入 “Transformer is a novel neural network architecture based on a self-attention mechanism” 后,计算机就可以迅速将它翻译为 “Transformer 是一种基于自注意力机制的新型神经网络架构”,神奇的机器翻译使得多语种互译成为可能。
近年来,得益于机器学习的快速发展,自然语言处理(NLP)技术不断突破,在人机交互、在线翻译工具等领域的应用层出不穷,不同语种的人与人、人与机器之间的无障碍自由交流得以实现。
当前的主流机器翻译主要是基于神经网络机器翻译,这类方法是一个 “编码器-解码器”(encoder-decoder)架构的系统,编码器对源语言序列进行编码,并提取信息,然后通过解码器把信息转换为目标语言,完成语言翻译过程。
自 2017 年问世以来,基于“编码器-解码器”架构设计的 Transformer 模型凭借其优越的性能,已然成为机器翻译领域的主流模型,在深度学习领域产生了巨大影响。
然而,Transformer 模型并非完美,模型引入self-attention机制虽实现了快速并行的训练,但在长序列文本的处理问题上,却需要占据大量计算资源,导致模型训练成本提高。
近日,由 Google、剑桥大学、DeepMind 和艾伦·图灵研究院(Alan Turing Institute)的研究人员组成的团队基于正交随机特征的快速注意力(Fast Attention Via Positive Orthogonal Random Features,FAVOR+)机制,提出了一种新的 Transformer 模型——Performer。相比于 Transformer 模型,新模型无需做出过度调整就可以变得更加高效和节能。
Performer 模型的技术突破
2017 年,谷歌大脑(Google Brain)的 Ashish Vaswani 等人发表了一篇题为 “Attention Is All You Need” 的论文,首次提出一种基于自注意力机制的 Transformer 模型。
Transformer 模型颠覆了传统神经网络的架构,弥补了卷积神经网络(CNN)和递归神经网络(RNN)存在的不足,在语义特征提取、长距离特征捕获、任务综合特征抽取等自然语言处理方面表现出了更优的性能,在自然语言处理、人机对话、图像处理等许多领域都达到了当时最好的水平(SOTA)。
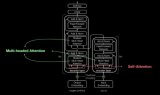
Transformer 架构的核心模块是自注意力模块,模型在处理每个单词(输入序列中的每个位置)时,自注意力模块通过计算输入序列中所有位置对的相似度分数,来寻找能够帮助更好地编码该单词的线索。
然而,随着输入序列长度的增加,模型需要二次方的计算时间来产生所有相似度分数,所需计算内存也随之增加,注意力机制面临的效率问题也越来越突出。
针对那些需要长距离关注的应用,在 Transformer 基础上已经有一些研究者提出了几种快速的、空间利用率高的改进方法,但是大部分常见方法都依赖于稀疏注意力机制。
然而,稀疏注意力机制仍存在一定的局限性。
(1)它们需要高效的稀疏矩阵乘法运算,而这些运算并不是在所有加速器上都能实现的;(2)它们通常不能为其表示能力提供严格的理论保证;(3)它们主要针对 Transformer 模型和生成式预训练进行优化;(4)它们通常会叠加更多的注意力层来补偿稀疏表示,这使得它们很难与其他预训练模型一起使用,因此需要重新训练并消耗大量能量。
此外,稀疏注意机制通常仍然不足以解决常规注意方法应用的全部问题,如指针网络。还有一些运算不能被稀疏化,如在工业级推荐系统中被大量应用的 softmax 运算。
Performer 使用了一个高效的(线性)广义注意力框架,能够对常规(softmax)全阶注意力进行可证明的、准确的、实用的估计,不依赖于任何稀疏性或低阶等先验条件,从而实现更快的训练速度,同时允许模型处理更长的序列,这一特性恰恰满足了 ImageNet64 图像数据集和PG-19文本数据集的要求。
Performer 模型通过正交随机特征(FAVOR+)算法实现快速注意力机制,并改用 Positive Orthogonal Random Features 估计 softmax 和高斯核函数,以实现在 FAVOR+ 机制中对常规 softmax 注意力进行鲁棒且无偏的估计。
研究人员表示:“Performer 是第一个通过微调可以与常规 Transformers 进行完全兼容的线性架构”。
左图 | 原点对称的通用函数 r(定义为建立在:三角随机特征和正随机特征上的估计器的均方误差(MSEs)的比值)是输入特征向量与其长度l之间的角度 φ(以弧度为单位)的函数, 函数的数值越大表示正随机特征性能越好的(φ,l)空间区域;
右图 | 当l为定值 1 时,与变化的角度 φ 构成的函数 r 为正切函数;右上角 | 比较低 softmax 内核值区域中两个估算器的 MSE。
作者通过比较发现,对于 φ 足够大的临界区域,该方法所使用的正交随机特征比任意的三角随机特征更精确。
图| 我们将原始的经过预训练的 Transformer 的权重转移到 Performer 中,Performer 产的精度达到 0.07 (橙色虚线),但在原来的梯度步数的一小部分中,很快就恢复了精度。然而在 PG-19 上,三角法(TRIG) softmax 逼近变得非常不稳定,而正特征(POS)(不重绘)和 Linformer (也是逼近 softmax)即使在重绘投影的情况下,也会在同样的复杂度中趋于平稳。具有特征重绘的正 softmax 是匹配 Transformer 的必要条件,SMREG 可实现更快的收敛。
这篇论文利用详细的数学定理,证明了与其单纯依靠计算资源来提升性能,还不如开发出改进的、高效的 Transformer 架构,来显著降低能耗。同时,由于 Performers 使用了与 Transformer 相同的训练超参数,也可以有效训练基于 softmax 的线性 Transformer。因此 FAVOR+ 机制可以作为一个简单的插件,而无需进行过多的调整。
Performer 模型应用前景广泛
研究人员表示,Performer 模型的提出,显著降低了常规 Transformer 的空间和时间复杂度,并在 Transformer 的研究以及非稀疏注意机制的作用方面开辟了新的途径。
该论文利用详细的数学定理,证明了与其单纯依靠计算资源来提升性能,还不如开发出改进的、高效的 Transformer 架构,来显著降低能耗。同时,由于 Performers 使用了与 Transformer 相同的训练超参数,因此 FAVOR+ 机制可以作为一个简单的插件,而无需进行过多的调整。
该团队在一系列丰富的场景下测试了 Performers 的性能,执行的任务包括像素预测、蛋白质序列建模。在实验设置中,一个 Performer 只用 FAVOR+ 机制取代了常规 Transformer 的注意力组件。
在使用蛋白质序列训练一个 36 层模型的挑战性任务上,基于 Performer 的模型(Performer-RELU)的性能优于基线 Transformer 模型:Reformer 和 Linformer,后者的准确率显著下降。
在标准的 ImageNet64 基准上,具有 6 层的 Performer 与具有 12 层的 Reformer 的准确性相当。优化后,Performer 的速度达到了 Reformer 的两倍。
研究人员表示,由于基于 Performer 的可扩展 Transformer 架构可以处理更长的序列,而不受注意力机制结构的限制,同时保持准确和鲁棒性,相信它们可以在生物信息学领域带来新的突破,如蛋白质的语言建模等技术已经显示出强大的潜力。
责任编辑:xj
-
谷歌
+关注
关注
27文章
6171浏览量
105469 -
Transformer
+关注
关注
0文章
143浏览量
6014 -
自然语言
+关注
关注
1文章
288浏览量
13355 -
nlp
+关注
关注
1文章
489浏览量
22049
发布评论请先 登录
相关推荐

Snapchat聊天机器人集成谷歌Gemini技术

Transformer能代替图神经网络吗
Transformer语言模型简介与实现过程
Transformer架构在自然语言处理中的应用
nlp逻辑层次模型的特点
nlp神经语言和NLP自然语言的区别和联系
nlp自然语言处理框架有哪些
NLP模型中RNN与CNN的选择
什么是自然语言处理 (NLP)
使用PyTorch搭建Transformer模型
谷歌大型模型终于开放源代码,迟到但重要的开源战略

基于Transformer模型的压缩方法






 工商网监
工商网监
评论