 融合3D场景几何信息的视觉定位算法
融合3D场景几何信息的视觉定位算法
视觉定位是自动驾驶和移动机器人领域的核心技术之一,旨在估计移动平台当前的全局位姿,为环境感知和路径规划等其他环节提供参考和指导。国内知名互联网公司-美团无人配送团队长期在该方面进行深入探索,积累了大量创新性工作。不久前,视觉定位组提出的融合3D场景几何信息的视觉定位算法被ICRA2020收录,本文将对该方法进行介绍。
背景
1. 视觉定位算法介绍1.1 传统视觉定位算法 传统的视觉定位方法通常需要预先构建视觉地图,然后在定位阶段,根据当前图像和地图的匹配关系来估计相机的位姿(位置和方向)。在这种定位框架中,视觉地图通常用带有三维信息和特征描述子的稀疏关键点表示。然后,通过当前图像与地图之间的关键点匹配获取2D-3D对应关系,利用PnP结合RANSAC的策略来估计相机位姿。其中,获得准确的2D-3D对应关系对定位结果至关重要。近年来,许多工作为提高2D-3D的匹配精度进行了各方面的探索,但大多传统方法[1,3,4]还是基于SIFT、SURF、ORB等底层特征,很难处理具有挑战性(光照改变或季节改变)的情况。
1.2 深度学习视觉定位算法 最近几年,融合神经网络的视觉定位算法被广泛研究,大家希望用神经网络取代传统方法中的部分模块(例如关键点和描述子生成)或者直接端到端的估计相机位姿。本论文研究内容属于对后面这种类型算法的优化。端到端视觉定位算法用神经网络的权值来表征场景信息,网络的训练过程实现建图,定位由网络的推理过程实现。PoseNet[2]是第一个基于神经网络的端到端视觉定位算法,它利用GoogLeNet的基础架构直接对输入的RGB图像进行6DoF相机位姿回归。在该思路的基础上,后续的改进包括加深网络结构、增加约束关系、融合时序信息和多任务联合建模等,例如,[5]加入贝叶斯CNN来建模精度不确定性;[6]将网络改为encoder-decoder结构;[7]和[8]引入了LSTM,利用视频流的时间和运动平滑性约束网络学习;[9]和[10]提出了多任务学习框架,联合建模视觉定位、里程计估计和语义分割三个任务,以上的工作都取得了定位精度的提升。
1.3 研究目的及意义 在上述提到的优化方法中,虽然[9]和[10]在定位精度上表现的更有优势,但是往往需要语义分割等大量的标注信息,在大规模的场景下代价太大。对于加深网络结构的优化方法,又可能带来训练的难度,因此,我们认为合理利用容易获取的信息来优化约束关系,具有更好的普适性和灵活性,这也是本研究的动机之一。一些其他研究者也在这方面开展了工作,例如受传统方法的启发,几何一致性误差、重投影误差、相对变换误差等被构建为正则化项加入损失函数中。这些改进比仅公式化预测位姿和真值位姿之间欧式距离的效果更好,并且不受网络结构的约束,可以灵活的适用于各种网络做进一步的性能提升。
在此基础上,我们进一步探索以更好的方式用几何信息来约束网络权重的更新。在SLAM应用和无人车平台中,深度信息是不可或缺的。例如,室内情况,利用现有的深度估计算法,可以直接从结构光相机、ToF相机或立体相机中获取深度信息;室外环境,通常采用三维激光雷达来获取深度/距离信息。因此,我们的改进也对深度信息加以利用。此外,我们使用了光度一致性的假设,也就是说,根据三维几何知识,当在多个图像中观察三维场景中的同一个点时,我们认为其对应的像素强度应该是相同的,这也被用于许多视觉里程计或光流算法。受此启发,我们构建了光度差损失项,并自然而然地搭配结构相似性(SSIM)损失项。前者为像素级约束,后者为图像级约束,和常用的欧式距离一起作为网络的损失函数,训练过程中约束网络权重的更新。我们优化后的损失函数融合了运动信息、3D场景几何信息和图像内容,帮助训练过程更高效、定位效果更准确。
2. 相关工作介绍2.1 几何一致性约束 几何一致性约束最近被用来帮助提高位姿回归的准确性,并被证明比单独使用欧氏距离约束更有效。[9]和[10]通过惩罚与相对运动相矛盾的位姿预测,将几何一致性引入到损失函数中。[11]利用图像对之间的相对运动一致性来约束绝对位姿的预测。[12]引入了重投影误差,使用真值和预测位姿分别将3D点投影到2D图像平面上,将像素点位置的偏差作为约束项。这些方法都被认为是当时使用几何一致性损失的最先进方法。在本研究中,我们探索了一个3D场景几何约束即光度差约束,通过聚合三维场景几何结构信息,使得网络不仅能将预测的位姿与相机运动对齐,还能利用图像内容的光度一致性。
2.2 光度差约束 光度差约束通常用于处理带监督或无监督学习的相对位姿回归、光流估计和深度预测。例如,[13]研究了视频序列的时间关系,为深度补全网络提供额外的监督。[14]利用无监督学习的稠密深度和带有光度差损失的相机位姿构建了神经网络,以学习场景级一致性运动。[15]提出了一种多任务无监督学习稠密深度、光流和ego-motion的方法,其中光度差约束对不同任务之间的一致性起着重要作用。由于光度差约束在相对位姿回归和深度预测中被证明是有效的,我们引入并验证了它在绝对位姿预测中的有效性。 与上述工作相比,我们的研究扩展了以下几点工作:
搭建了一个深度神经网络模型,可以直接从输入图像估计相应的相机绝对位姿。
利用深度传感器信息,构建了 3D 场景几何约束来提高位姿预测精度。并且,稀疏深度信息足以获得显著的定位精度提升,这意味着我们的方法可以适用于任何类型的深度传感器(稀疏或稠密)。
在室内和室外数据集上进行了广泛的实验评估,证明了加入 3D 场景几何约束后,可以提高网络的定位精度,并且这一约束可以灵活地加入到其他网络中,帮助进一步提高算法性能。
算法介绍
1. 算法框架
本研究提出的算法框架和数据流如图a所示,蓝色部分是算法中的神经网络部分(图b),绿色部分是warping计算过程,黄色部分是网络的损失函数项,只有蓝色部分包含可训练的权重。 蓝色部分的网络模型采用主流的ResNet-50网络,保留原来的block设置,并在最后一个block后加入3个全连接层,分别预测3维的translation(x)和3维的rotation(q)。网络的训练过程需要输入两张连续的有共视的图像以及其中一张图像的深度图,建立真值位姿和预测位姿之间的欧式距离约束作为损失项。大部分先前文献中的工作仅以这个损失项作为损失函数,我们的工作则进一步融入了3D场景几何信息,通过利用比较容易获取的深度信息将这个约束公式化为光度差和SSIM。相比之下,3D场景几何约束是像素级的,可以利用更多的信息包括相机运动,场景的三维结构信息和图像内容相关的光度信息,从而使网络的学习更加高效,更好地朝着全局极小值的方向收敛。

2.Warping计算 绿色部分的warping计算利用连续两张图像之间的相对位姿变换和其中一张图像的深度图,将本张图像上的像素投影到另一张图像的视角上,生成视warping后的图像,计算公式如下所示。

在warping计算中,从二维图像像素重建三维结构需要深度信息,实际应用中我们可以从深度传感器(结构光相机、ToF相机和三维激光雷达)获取深度信息或通过相关算法回归深度,例如从两个重叠的图像中提取匹配点的三角测量方法。为了不引入误差,我们更倾向于选择来自深度传感器的比较鲁棒的深度信息。为了方便反向传播的梯度计算,我们采用双线性插值作为采样机制,生成与当前图像格式相同的合成图像。此外,这部分计算不含可训练的参数,并且inference过程不需要进行这部分的计算,因此不会带来额外的时间或者资源开销。 3. 损失函数 在训练过程中,应用了三个约束条件来帮助训练收敛:一个经典的欧式距离损失项来约束预测位姿和真值位姿的距离,欧式距离损失项此处不再赘述,直接给出公式如下:
 当视角变化较小且环境光不变时,同一个三维点在不同图像中的光强应该相同。这种光度一致性用于解决许多问题,如光流估计、深度估计、视觉里程计等。在这里,我们使用它来进行绝对位姿估计,并光度差损失项公式化为warping计算后的图像与原始图像对应像素点的光度差值:
当视角变化较小且环境光不变时,同一个三维点在不同图像中的光强应该相同。这种光度一致性用于解决许多问题,如光流估计、深度估计、视觉里程计等。在这里,我们使用它来进行绝对位姿估计,并光度差损失项公式化为warping计算后的图像与原始图像对应像素点的光度差值:
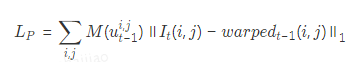
其中,M是用来过滤没有深度信息或者不服从光度一致性的像素。在我们的实验中,主要用它来屏蔽两种类型的像素:移动目标对应的像素和带有无效深度信息的像素。光度差损失项会约束预测的位姿离真值位姿不远,以保证在相邻图像间进行warping计算后重建的图像与原始图像对应像素的光度值一致。考虑到warping计算后,获得了视角重建后的图像,自然而然的引入结构相似性约束作为损失项。这个约束反映了场景结构的一致性,计算公式如下所示:
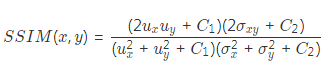

网络的损失函数定义为三个损失项的加权和,用三个加权系数进行尺度均衡。 
实验结果
为了验证我们提出的算法的性能,进行了以下实验: 1. 与其他算法定位结果对比 在7Scene数据集中,除了MapNet[11]在chess场景中的表现稍好之外,我们的方法在其他场景都取得了最优的结果(见table 1)。在所需的训练时间上,MapNet 需要300个epochs和PoseNet[2]需要多于120个epochs,我们的方法只需要50个epochs。同时,在室外的Oxford robotcar数据集上,我们的方法也取得了较大的定位精度提升。Figure2显示了在7Scene中随机挑选的场景的测试结果。很明显,PoseNet的预测位姿噪声较大,MapNet表现的更稳定,但预测精度欠佳,我们的定位结果更为精确。
2. 损失项的消融实验 为了充分验证我们提出的光度差损失和SSIM损失对视觉定位算法性能提升的贡献,分别进行两个训练:在PoseNet网络的损失函数中加入光度差损失和SSIM损失后训练网络。在我们的算法中去掉这两项损失项,只在欧式距离的约束下训练网络。结果表明加入光度差和SSIM损失项总是能提高网络的定位性能(详细结果见论文)。同时,也表明新的损失项可以灵活的加入其他网络,用于进一步提高定位精度。
3. 深度稀疏实验 实际视觉定位应用中,并不总是有可靠的稠密深度可用,如果我们的算法在稀疏深度上依然可以表现的很好,则可以证明我们的方法具有较广泛的适用性。我们把可用的深度随机稀疏至原来的20%和60%后,重新训练网络,最终的结果如Table3所示,定位精度并没有被严重恶化。
4. 自监督方法的实验 在进行warping计算时,我们用了输入两帧图像的位姿预测结果来计算相对位姿变换,进而做warping计算,单就光度差和SSIM损失项来说,这是一种自监督的学习方法,那么,也可以一帧图像用预测结果,另一帧用真值来计算相对位姿变换。通过实验对比这两种方法,实验结果(详细结果见论文)表明,自监督策略的结果更优。除了网络被训练的次数更多这一原因外,它有助于网络以一种更自然的方式学习相机位姿的连续性和一致性,因为对于共视的图像,其相应的位姿应该是高度相关的。


结论与展望
本文提出了一种新的视觉定位算法,搭建一个新的网络框架端到端的估计相机位姿,在对网络约束关系的优化中,通过融合3D场景几何结构、相机运动和图像信息,引入了3D场景几何约束,帮助监督网络训练,提高网络的定位精度。实验结果表明,我们的方法优于以往的同类型工作。并且,在不同的网络中加入新的约束关系后可以进一步提高定位精度。
基于深度学习的视觉定位算法正在被广泛而又深入的研究,无论是提升算法的精度还是增强实际场景的适用性,各方面的尝试和努力都是迫切需要的。希望在未来的工作中,能够通过融入语义信息或者采用从粗到精多阶段级连的方法,在室内外场景上实现更高精度更加鲁棒的位姿估计,更多细节见论文.
论文原文:3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning 链接:https://arxiv.org/abs/2005.06147 参考文献 [1] Ke, Yan and R. Sukthankar. “PCA-SIFT: a more distinctive representation for local image descriptors.” Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2004. [2] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in ICCV, 2015. [3] Bay, Herbert, et al. “Speeded-up robust features (SURF).” Computer vision and image understanding 110.3 (2008): 346-359.
[4] Rublee, Ethan, et al. “ORB:An efficient alternative to SIFT or SURF.” ICCV. Vol. 11. No. 1. 2011. [5] A. Kendall and R. Cipolla,“Modelling uncertainty in deep learning for camera relocalization,” ICRA, 2016. [6] I. Melekhov, J. Ylioinas, J. Kannala, and E. Rahtu, “Image-based localization using hourglass networks,” arXiv:1703.07971, 2017. [7] F. Walch, C. Hazirbas, et al.,“Image-based localization using lstms for structured feature correlation,” in ICCV, 2017. [8] Xue, Fei, et al. “Beyond Tracking: Selecting Memory and RefiningPoses for Deep Visual Odometry.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019
[9] A. Valada, N. Radwan, and W. Burgard, “Deep auxiliary learning for visual localization and odometry,” in ICRA, 2018. [10] N. Radwan, A. Valada, W. Burgard, “VLocNet++: Deep MultitaskLearning for Semantic Visual Localization and Odometry”, IEEE Robotics and Automation Letters (RA-L), 3(4): 4407-4414, 2018. [11] Brahmbhatt, Samarth, et al. “Geometry-aware learning of maps for camera localization.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. [12] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” CVPR, 2017. [13] Ma, Fang chang, Guilherme Venturelli Cavalheiro, and Sertac Karaman.“Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera.” 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019. [14] Zhou, Tinghui, et al. “Unsupervised Learning of Depth and Ego-Motion from Video.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. [15] Yin, Zhichao, and Jianping Shi. “Geonet: Unsupervised learning of dense depth, optical flow and camera pose.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
责任编辑:xj
原文标题:机器视觉干货 | 场景几何约束在视觉定位中的探索
文章出处:【微信公众号:机器人创新生态】欢迎添加关注!文章转载请注明出处。
-
机器人
+关注
关注
211文章
28779浏览量
209028 -
机器视觉
+关注
关注
162文章
4421浏览量
120899 -
视觉定位
+关注
关注
5文章
54浏览量
12448
原文标题:机器视觉干货 | 场景几何约束在视觉定位中的探索
文章出处:【微信号:robotplaces,微信公众号:机器人创新生态】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伦科技裸眼3D便携屏有哪些特点?

从2D走向3D的视觉传感器

3D 视觉定位技术:汽车零部件制造的智能变革引擎
一种全新开源SfM框架MASt3R

3D可视化赋能智慧园区安防管理,开启园区管理新篇章!
紫光展锐助力全球首款AI裸眼3D手机发布

3d场景建模可视化,场景1:1还原
苏州吴中区多色PCB板元器件3D视觉检测技术

3D视觉引导方案解决工厂产线上下料难题
机器人3D视觉引导系统框架介绍
解决方案|基于3D视觉技术的铝合金板件刷油烘干自动化上下料
包含具有多种类型信息的3D模型
工业自动化,3D视觉在五金件上下料中的应用






 工商网监
工商网监
评论