 如何帮助改善美国在人口水平上的健康的事业呢?
如何帮助改善美国在人口水平上的健康的事业呢?
当临床医生将AI应用于女性患者时,主要接受男性X射线训练的AI将表现不佳。如果患者皮肤黝黑并且大多数训练图像来自皮肤白皙的患者,则用于皮肤病学照片诊断皮肤癌的算法将使这项工作陷入困境。等等。这种偏见的例子在医疗保健AI的装甲中积蓄了不可忽视的缺点。
当然,即使可行,也很难从各种各样的患者群体中收集适合AI的培训数据。但是,如果医疗保健中的AI无法帮助某些最脆弱的患者人群,那么它如何帮助改善美国在人口水平上的健康的事业呢?
11月17日发表在《科学美国人》上的一篇观点文章中,三位斯坦福大学的医学博士/博士对该主题提出了最好的想法。
“人工智能的偏见是一个复杂的问题;仅提供各种培训数据并不能保证消除偏见。” Kaushal,Altman和Langlotz写道。“还提出了其他一些问题,例如,人工智能工具的开发商和出资者之间缺乏多样性;从多数群体的角度看待问题的框架;关于数据的隐含偏见假设;以及使用AI工具的输出来无意或无意地使偏差永久化。”
他们指出,研究人员正在尝试通过构建可从有限输入中推断出广泛输出的算法来解决数据不一致的问题。
作者写道:“通过这些创新,可能会出现减少AI对海量数据集需求的新方法。”“但是目前,确保用于训练算法的数据的多样性对于我们理解和缓解AI偏差的能力至关重要。”
为此,他们呼吁建立所需的技术,法规,经济和隐私基础架构,以收集不仅大而且足够多样化的数据,以培训医学AI,使世界各地的所有患者受益。
责任编辑:lq
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
医疗保健
+关注
关注
4文章
314浏览量
30699 -
AI
+关注
关注
87文章
30315浏览量
268570 -
人工智能
+关注
关注
1791文章
46927浏览量
237783
发布评论请先 登录
相关推荐
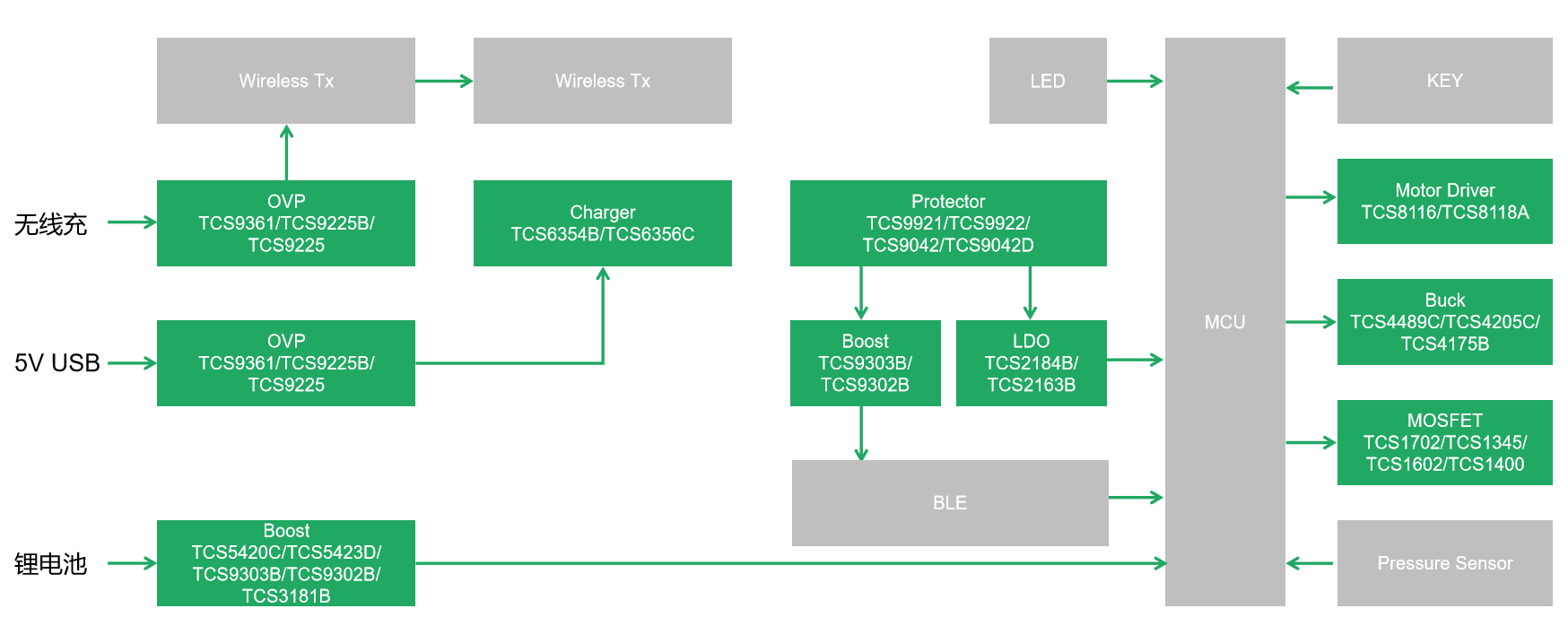
汤诚科技电动牙刷芯片解决方案,口腔健康新选择
在现代生活节奏加速的今天,口腔健康问题愈发凸显,促使人们日益关注个人口腔卫生。传统刷牙方法因个体差异和执行方式的不同,往往无法彻底清除牙菌斑,甚至可能对牙龈造成伤害。电动牙刷的出现,凭借其程序化
健康小屋无线智能化解决方案
随着人们生活水平的提高和健康意识的增强,越来越多的人开始关注自身健康状况,并积极寻求健康管理和咨询服务,社区健康小屋作为一种
TAS6424的开关频率2.MHz 在EMC CE电压法测试中出现超标情况,请问如何改善?
TAS6424 的开关频率2.MHz 在EMC CE 电压法测试中出现超标情况。请问从哪个方面可以改善呢
发表于 10-09 06:01
怎么样提高verilog代码编写水平?
怎样?
A:信号的上升沿和下降沿包含丰富的频率成分,这是由于信号的突变本质所导致的。
从数学角度来看,一个突变的信号(如阶跃信号)在时域上的急剧变化,其傅里叶变换在频域上会对应一个宽的频谱。
量化这种
发表于 09-25 20:05
LMH7322怎样去改善输出波形呢 ?
图一
我按照LMH7322资料中,按照上图一 画的 PCB图 (见图二)
图二
测试时输出的波形为:
请问工程师 怎样去改善输出波形呢 ?
发表于 09-02 06:57
振弦采集仪:帮助工程师准确评估结构健康状况的利器
振弦采集仪:帮助工程师准确评估结构健康状况的利器 振弦采集仪是一种用于评估结构健康状况的重要工具。它能够准确地测量结构的振动特性,并通过数据分析和处理,提供有关结构健康状况的可靠信息。

在美国VPS上设置开发和测试环境的基本步骤和技巧
在美国vps上搭建开发环境和测试环境是很多开发者和企业追求高效研发与测试流程的重要一步。本文介绍了在美国VPS

蓝牙模块在健康医疗领域的创新应用
随着科技的飞速发展,蓝牙模块在健康医疗领域的应用日益广泛,不仅提升了医疗服务的效率和质量,也为患者带来了更为便捷、安全的就医体验。本文将探讨蓝牙模块在健康医疗领域的创新应用,并展望其未
微软与可汗学院携手,提供人工智能工具免费课程给美国教师
5 月 22 日讯,在微软Build会议上,微软与可汗学院宣布建立深度合作关系,推出面向非营利组织的AI教学工具Khanmigo for Teachers。此举旨在推动美国数百万教育事业
在选择美国硅谷站群服务器时需要特别注意什么?
美国硅谷的站群服务器是专为满足多网站管理需求而设计的服务器,具备高性能和网络稳定性。那么在选择美国硅谷站群服务器时需要特别注意什么呢?RAK部落小编为您整理发布相关内容,希望对您选择
辐射RE整改:科学应对辐射环境,建设健康未来?|深圳比创达电子EMC a
刻不容缓的问题。通过科学的手段,我们有信心迎接这一挑战,建设一个更加健康、安全的未来。在整改的过程中,社会各界的共同努力将成为推动辐射环境改善的强大力量。综上所述,相信通过本文的描述,各位对辐射RE
发表于 02-23 09:48
简述MinewSemi的GNSS模块引领体育与健康科技革新
体育与健康科技领域的创新一直在推动人们更健康、更活跃的生活方式。创新微公司的GNSS模块正成为这一变革的关键推动力。本文将深入研究MinewSemi的GNSS模块在体育和
振弦采集仪在桥梁健康监测中的应用与分析
桥梁结构上安放振弦传感器,采集桥梁的振动信号。传感器可以记录桥梁的振动频率、振动幅度、振动波形等信息,并将这些数据发送到监测系统进行分析和处理。 振弦采集仪 在桥梁健康监测中,振弦采集仪可以发挥以下作用: 1. 确定

Kohler在CES 2024上展示行业领先的设计和智能家居健康体验
Kohler Co. 宣布将在 CES 2024 上展出其尖端设计、新款创新产品和智能家居健康体验。Kohler 的产品系列彰显了其经久不变的承诺:将住宅转变为舒适、自我呵护且紧跟时代的个人家园。
基于蜂窝物联网的健康监测可穿戴设备日渐普及
随着世界人口老龄化,健康和辅助生活设施为老年人提供充分护理的压力越来越大,此时,基于蜂窝物联网的远程监控解决方案正在填补这一空白,提供老年人便利、精准,可进行远程监控的设备,改善老年人的医疗照护质量。本文将为您探讨目前老年人医疗





 工商网监
工商网监
评论