 机器学习并行化的自适应、可组合与自动化问题
机器学习并行化的自适应、可组合与自动化问题
CMU 机器人研究所张昊(Hao Zhang)博士论文新鲜出炉,主要围绕着机器学习并行化的自适应、可组合与自动化问题展开。
随着近年来,机器学习领域的创新不断加速,SysML 的研究者已经创建了在多个设备或计算节点上并行机器学习训练的算法和系统。机器学习模型在结构上变得越来越复杂,许多系统都试图提供全面的性能。尤其是,机器学习扩展通常会低估从一个适当的分布策略映射到模型所需要的知识与时间。此外,将并行训练系统应用于复杂模型更是增加了非常规的开发成本,且性能通常低于预期。 近日,CMU 机器人研究所博士张昊公布了自己的博士学位论文《机器学习并行化的自适应、可组合与自动化》,旨在找出并解决并行 ML 技术和系统实现在可用性和性能方面的研究挑战。 具体而言,该论文从可编程性、并行化表示、性能优化、系统架构和自动并行化技术等几方面对分布式并行 ML 展开了研究,并认为分布式并行机器学习可以同时实现简洁性和高效性。此外,该论文表明,并行 ML 的性能可以通过生成自适应 ML 模型结构和集群资源范式的策略实现大幅度提升,同时通过将「如何并行化」这一核心问题形式化为端到端优化目标以及构建可组合分布式 ML 系统来自动优化这类自适应、自定义策略,进而可以解决可用性挑战。
论文链接:https://www.cs.cmu.edu/~hzhang2/files/hao_zhang_doctoral_dissertation.pdf 机器之心对该论文的核心内容进行了简要介绍,感兴趣的读者可以阅读原论文。 论文内容介绍 这篇论文主要由三部分组成,如下图所示,第 1 部分(第三章 - 第五章):在单个机器学习并行化层面,使用自适应并行化理解和优化并行机器学习性能;第 2 部分(第六章 - 第七章):为机器学习并行开发统一的表示和可组合系统;第 3 部分(第八章):机器学习并行化的自动化。
论文结构概览 论文第一部分提出了一个简单的设计原则自适应并行(adaptive parallelism),根据模型构建要素(比如层)的特定 ML 属性,将合适的并行化技术应用于模型组成要素中。作者以 BERT 为例,总结出了实现这种自适应的基本原理和三个核心概念,分别是子模型策略组合、多个并行化方面的系统优化和资源感知。此外,作者推导出了一系列优化和实现方法,从不同层面去提升 ML 并行化。研究结果表明其显著提高了 ML 训练在集群上的效率和可扩展性。 第二部分对这种方法进行了概述,并且面向机器学习并行化任务的两个常见范式:单节点动态批处理和分布式机器学习并行,作者将机器学习的并行化表述为端到端的优化问题,并寻找其自动化的解决方法。作者提出了原则表征来表示两类机器学习并行,以及可组合的系统架构 Cavs 与 AutoDist。它们能够快速组合不可见模型的并行化策略,提升并行化表现,并简化并行机器学习程序。
Facebook AI 提出的 DETR 的架构图 在此基础上,论文第三部分提出一个自动并行化框架 AutoSync,用于自动优化数据并行分布训练中的同步策略。它实现了「开箱即用」的高性能,可以通过提出的表征进行空间导航,并自动识别同步策略,这些策略比现有的手工优化系统的速度提高了 1.2-1.6 倍,降低了分布式 ML 的技术障碍,并帮助更大范围的用户访问它。总结来说,这篇论文提出的相关技术和系统验证了分布式环境下面向大规模机器学习训练的端到端编译系统的概念与原型实现。

AutoSync 策略的自动优化流程算法
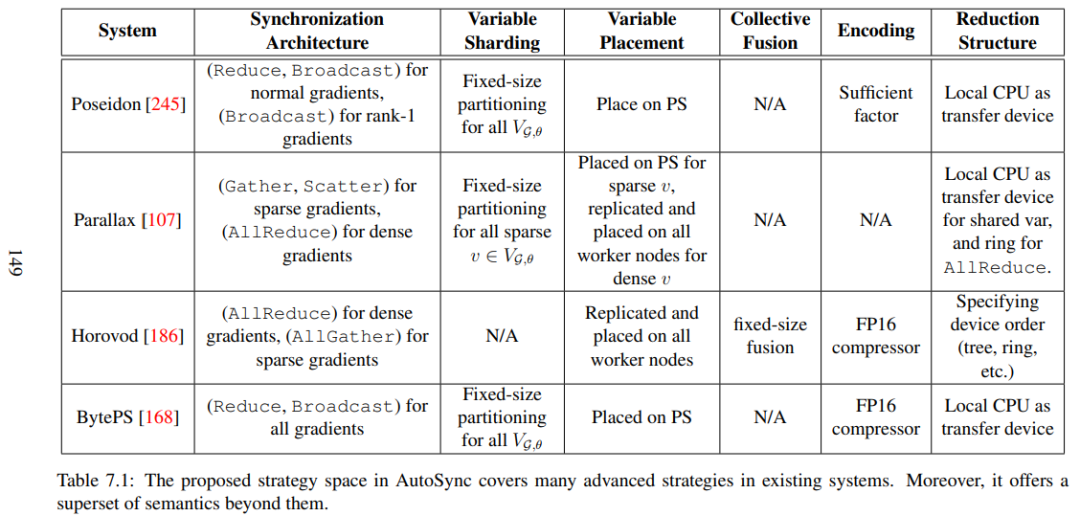
AutoSync 中的策略空间包含了现有系统中的很多高级策略 语言模型的分布式预训练示例 预训练语言表征已成为 NLP 系统中最普遍、最关键的部分。使用与任务无关的语言模型框架,可以对从 web 抓取的未标记文本进行无监督的训练,只需预测下一个单词或句子。预训练表征可以灵活地应用于下游任务,针对特定任务的损失和数据集进行微调,或是通过少量上下文学习。 近年来,人们在开发更强大的任务无关 LM 架构方面取得了巨大进展,从单层词向量表征到递归神经网络的多层表征和上下文状态,以及最新的基于递归 transformer 的架构。 下图展示了一个著名的例子——双深度 Transformer(BERT)——属于第三类。不管网络架构如何,语言模型通常包含许多参数,而这些参数是在大规模文本语料库上训练出来的,这是因为它们的建模能力随其大小以及文本扫描量成正比。
假设我们对训练 BERT 感兴趣,在基于 AWS 的 GPU 集群上使用 TensorFlow 等框架实现。我们可以使用最先进的开源训练系统——Horovod,开始数据并行训练。 应用 Horovod 转换单机 BERT 训练代码,涉及将原始的框架内置优化器与 Horovod 修补的优化器包装在一起。然后 Horovod 会在集群节点上使用 collective allreduce 或 allgather 来平均和应用梯度。
这些 TensorFlow+Horovod 代码片段展示了 Horovod 如何给优化器打补丁,以及如何为分布式训练进行非常小的代码改变。 虽然可能会在目标集群上部署训练,但获得的扩展不太可能随着添加更多资源而成比例增长(理想情况下,线性扩展与加速器的数量成比例增长):所有的语言模型都有嵌入层,这些层拥有很多模型参数,但在每个设备上的每次训练迭代中访问很少,减少或聚集其梯度都会导致不必要的网络运作;BERT 中的 transformer 是矩阵参数化、计算密集型的,与 Horovod 中的常规做法一样,将梯度分组在一个缩减环(reduction ring)中,很容易使以太网带宽或异构集群 (如 AWS) 的设备 Flops 饱和。 在这两种情况下,设置都容易出现通信或计算混乱的情况,即训练时间的缩短无法令人满意,花费在训练上的计算资源成本在经济上也不能接受。这表明,并行化的常规目标并没有实现。 所以,本文提出的这种自适应并行策略,能够为并行化性能进行适当的优化。 作者介绍 张昊在今年 9 月 2 日完成了博士学位的论文答辩,导师为 CMU 教授、Petuum 创始人邢波(Eric Xing)。获得 CMU 机器人研究所的博士学位后,他将以博士后身份进入 UC 伯克利的 RISE 实验室,与计算机科学系教授 Ion Stoica 共同工作。
他的研究兴趣包括可扩展的机器学习、深度学习以及计算机视觉和自然语言处理领域的大规模机器学习应用。他还协同设计了一系列模型、算法和系统,在更大规模数据、问题、应用中进行机器学习扩展,以简化复杂机器学习模型和算法的原型开发,使机器学习程序分布自动化。
责任编辑:lq
-
计算机视觉
+关注
关注
8文章
1701浏览量
46175 -
机器学习
+关注
关注
66文章
8454浏览量
133170 -
自然语言处理
+关注
关注
1文章
620浏览量
13665
原文标题:229页,CMU博士张昊毕业论文公布,探索机器学习并行化的奥秘
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
罗克韦尔自动化推出DataReady智能机器
下一代机器人技术:工业自动化的五大趋势
步进电机如何自适应控制?步进电机如何细分驱动控制?
移动电源组合套机的创新|引领者比斯特自动化







 工商网监
工商网监
评论