 如何去掉batch normalization层来加速神经网络
如何去掉batch normalization层来加速神经网络
导读
如何去掉batch normalization层来加速神经网络。
介绍
Batch Normalization是将各层的输入进行归一化,使训练过程更快、更稳定的一种技术。在实践中,它是一个额外的层,我们通常添加在计算层之后,在非线性之前。它包括两个步骤:
首先减去其平均值,然后除以其标准差
进一步通过γ缩放,通过β偏移,这些是batch normalization层的参数,当网络不需要数据的时候,均值为0、标准差为1。
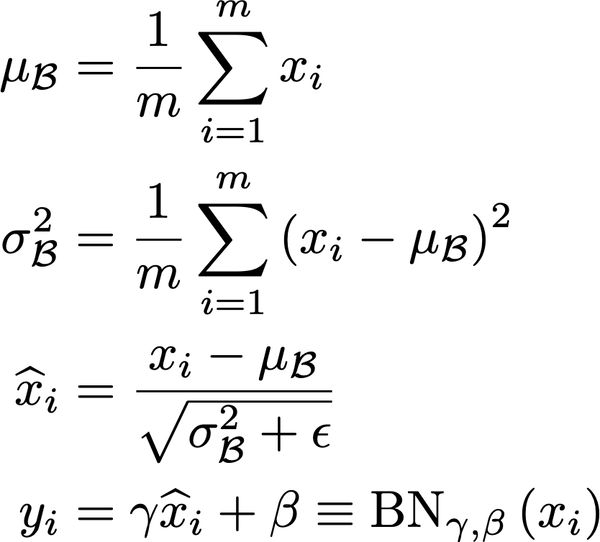
Batch normalization在神经网络的训练中具有较高的效率,因此得到了广泛的应用。但它在推理的时候有多少用处呢?
一旦训练结束,每个Batch normalization层都拥有一组特定的γ和β,还有μ和σ,后者在训练过程中使用指数加权平均值进行计算。这意味着在推理过程中,Batch normalization就像是对上一层(通常是卷积)的结果进行简单的线性转换。
由于卷积也是一个线性变换,这也意味着这两个操作可以合并成一个单一的线性变换!这将删除一些不必要的参数,但也会减少推理时要执行的操作数量。
在实践中怎么做?
用一点数学知识,我们可以很容易地重新对卷积进行排列来处理batch normalization。提醒一下,对一个输入x进行卷积之后再进行batch normalization的运算可以表示为:
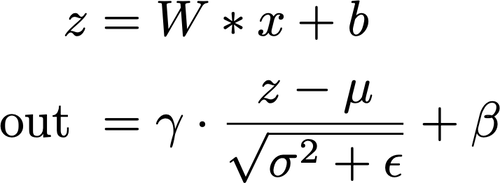
那么,如果我们重新排列卷积的W和b,考虑batch normalization的参数,如下:
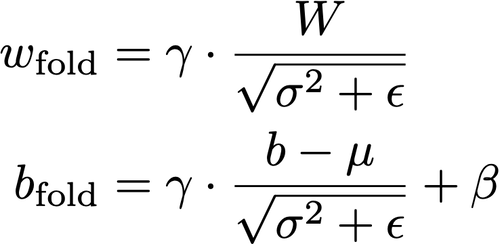
我们可以去掉batch normalization层,仍然得到相同的结果!
注意:通常,在batch normalization层之前的层中是没有bias的,因为这是无用的,也是对参数的浪费,因为任何常数都会被batch normalization抵消掉。
这样做的效果怎样?
我们将尝试两种常见的架构:
使用batch norm的VGG16
ResNet50
为了演示,我们使用ImageNet dataset和PyTorch。两个网络都将训练5个epoch,看看参数数量和推理时间的变化。
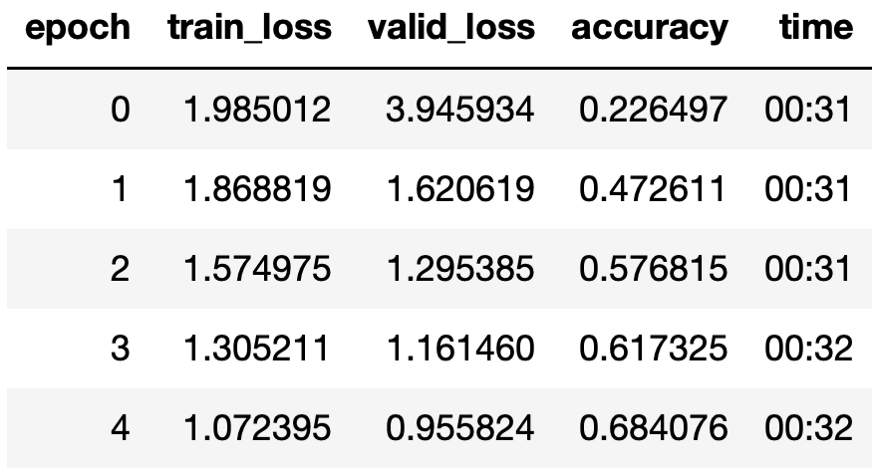
1. VGG16
我们从训练VGG16 5个epoch开始(最终的准确性并不重要):
参数的数量:

单个图像的初始推理时间为:

如果使用了batch normalization折叠,我们有:

以及:

8448个参数被去掉了,更好的是,几乎快了0.4毫秒!最重要的是,这是完全无损的,在性能方面绝对没有变化:

让我们看看它在Resnet50的情况下是怎么样的!
2. Resnet50
同样的,我们开始训练它5个epochs:
初始参数量为:
推理时间为:

使用batch normalization折叠后,有:

和:

现在,我们有26,560的参数被移除,更惊讶的hi,推理时间减少了1.5ms,性能一点也没降。

责任编辑:lq!
-
神经网络
+关注
关注
42文章
4771浏览量
100772 -
参数
+关注
关注
11文章
1834浏览量
32224 -
线性
+关注
关注
0文章
198浏览量
25151
原文标题:使用Batch Normalization折叠来加速模型推理
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论