 结合Rosetta介绍如何定制化改造TensorFlow前后端相关组件
结合Rosetta介绍如何定制化改造TensorFlow前后端相关组件
本文来自社区投稿与征集,作者Rosetta 技术团队。本文源自他们在 GDG 活动中的分享。
引言
我们之前分享了:【技术分享】隐私 AI 工程技术实践指南,从整体上了介绍了基于深度学习框架开发隐私 AI 框架的⼯程挑战和可⾏解决⽅案。在本文中,我们将进⼀步结合 Rosetta 介绍如何定制化改造 TensorFlow 前后端相关组件,以集成 MPC (Multi-Party Computation) 等隐私计算技术,同时保留对 TensorFlow 接口 API 的复⽤,从⽽实现我们上⼀篇⽂章中所强调的“系统易⽤性”。
⽬前 Rosetta 主要基于 TensorFlow 1.14 CPU 版本加以开发(以下简称 TensorFlow 为 TF),这是因为 TF 1.x ⽬前在⼯业界中实际应⽤较为⼴泛,⽽引⼊动态图等⾼级功能的 TF 2.0,则由于接⼝不向后兼容等问题,仍没有得到⼤规模落地。后续我们也将在 Rosetta 本身功能稳定的基础上考虑⽀持 TF 2.0。下⾯就让我们开始吧。
TensorFlow 快速回顾
想要基于 AI 框架进⼀步扩展引⼊隐私计算功能,第⼀步需要⽐较深⼊地了解这些 AI 框架,所以⾸先让我们简单回顾⼀下 TF 的核⼼概念以及宏观的内部处理过程。
TensorFlow 核心概念
Tensor(张量)
深度学习需要完成对⼤量⾼维度复杂数据的处理,在 TensorFlow 中,⽤ Tensor 来封装同⼀类型数据的⾼维数组。其中,基础类型除了各种不同精度的整数、浮点数外,还⽀持 tf.string 类型,这给我们提供了进⾏⾃定义类型改造的可能性。
⼀个三维 Tensor(图⽚来⾃⽹络)
Operation(算⼦)
Operation(算⼦,有时也称“操作”)⽤来封装对于 Tensor 的处理逻辑。同时也是连接 TF 的前端和后端之间逻辑处理的基本单元,在实际使⽤中,⽤户可以使⽤ Keras 等上层封装 API 更⽅便的表达复杂计算逻辑,但是这些上层模块的内部,最终也会调⽤各个算⼦来完成逻辑的表达。
Graph(计算图)
⽤户在 TF 前端调⽤各 API 形成的完整计算逻辑,在内部会以 dataflow graph 的形式来表达。在这⼀有向⽆环图 (DAG) 上,以算⼦等作为节点,以 Tesnor 等作为边来指明数据的流动路径。在 graph 上,有些节点是 TF 框架⾃身根据需要添加的,⽐如,⽤户在 training 算法阶段时,只需要调⽤各种优化器 (Optimizer) 的 minimize ⽅法,TF ⾃身就会⾃动找到前向图中各算⼦所对应的梯度算⼦,并按照数学上的链式求导法则,构建出反向梯度⼦图。
TensorFlow 数据流计算图
Session(会话)
Session 主要是在实际执⾏ graph 时对⼀次执⾏的上下⽂进⾏维护处理。当⽤户调⽤其 run ⽅法时,TF 就会分析为了获取这⼀次的计算⽬标所需要运⾏的⼦图,并结合 TF 内置的强⼤的并⾏优化、分布式执⾏等模块,将所需要执⾏的逻辑进⼀步拆分为各个⼦图,各⾃映射到当前的可⽤设备资源上,最终调度这些设备以并⾏的⽅式⾼效完成计算任务。
TensorFlow 分布式并⾏执⾏(图⽚来⾃⽹络)
TensorFlow 的 codebase 本身还是很复杂的,篇幅所限,难以在此对 TensorFlow 进⾏深⼊的介绍,感兴趣的读者可以参考 TensorFlow 公众号(TensorFlow_official) 上其他优秀⽂章以进⼀步学习 TensorFlow。
TensorFlow 自定义算子库的扩展方法
TF 提供了⽐较丰富的扩展⽅法,除了在 Python 层可以基于内置的丰富算⼦集合,通过模块的继承、组装等⽅式得到⾃定义的功能之外,还可以在后端 C++ 层⾃定义⾃⼰的算⼦[2]。在后端基于 CustomC++op 机制进⾏扩展相⽐于在前端层进⾏扩展有⼀些特别的优势:
有时候基于现有 TF 原⽣算⼦表达上层⾃定义逻辑很困难,⽽在后端实现则更灵活⾃由;
通过后端 CustomC++op,可以以更加⾼效的⽅式实现⾃⼰的逻辑,可以在其中进⾏更底层的、⾯向编译器等的各种优化;
整体上看,基于 TF 的扩展⼯具,使⽤ customC++op,只需要完成以下四步即可:
1. 通过 TF 提供的 C++ 宏⼯具注册新的 op。这主要是定义好这个 op 的输⼊输出类型、名称等接⼝信息。例如在 Rosetta 中可以如下定义⼀个新的 op:
REGISTER_OP("RttMatmul") .Input("x: string") .Input("y: string") .Output("res: string") .Attr("transpose_a: bool = false") .Attr("transpose_b: bool = false") .SetIsStateful();
2. 在 C++ 中具体的实现这个 op 所对应的内部处理逻辑,这就是所谓的后端 “kernel”。TF 提供了⼀些⽅便的基类接⼝,⽤户⼀般只需要定义⼀个⼦类,override 实现其中的 compute ⽅法即可,例如:
template
3. 基于 REGISTER_KERNEL_BUILDER 这样的宏,将上⾯所定义的接⼝和内部的实现给绑定起来。这是因为 TF ⽀持基于不同的输⼊、输出类型和所运⾏的底层设备架构来定义同⼀个算⼦不同的内部实现,所以⽤户可以定义多种 kernel 实现,告知给系统什么场景下运⾏具体哪⼀个 kernel,在实际运⾏时,TF 就可以根据不同的设备、数据流上下⽂调⽤不同的 kernel 来实际执⾏此 op。例如:
REGISTER_KERNEL_BUILDER(Name("RttMatmul").Device(DEVICE_CPU), RttMatMulOp
4. 将你的后端算⼦库编译为⼀个动态库 so ⽂件后,在 Python 层调⽤接⼝引⼊此模块,然后就可以如同调⽤原⽣算⼦⼀样的⽅式来调⽤这些⾃定义算⼦了。例如:
# load librtt_ops.so _rtt_ops_lib = os.path.dirname(__file__) + '/../../../librtt-ops.so' rtt_ops = tf.load_op_library(_rtt_ops_lib) # now, you can use the ops in this library as rtt_ops.rtt_matmul
如果你需要在模型训练程序中调⽤这个⾃定义算⼦,你还需要在 Python 层通过 @ops.RegisterGradient("XXXOp") 来注册这个算⼦对应的梯度算⼦,通过这种⽅式,TF 就可以在⾃动构建反向梯度图时⾃动的实现对⾃定义算⼦梯度的集成。
Rosetta 利用 TF 这⼀扩展机制引⼊两类算⼦:中间过渡层 RttOps 算⼦库和隐私计算 SecureOps 算⼦库,前者是为了⽀持⾯向⾃定义数据类型的计算图的构建,后者是为了对接后端隐私计算功能,并在执⾏图时进⾏动态绑定。之所以从设计上区分这两类算⼦,是因为可以进⼀步解耦图的构建和图的执⾏,提供更多的灵活性。引⼊了这两个基础的算⼦库之后,就可以进⼀步的进⾏整体的改造了。
RttOp 算⼦库
与后端 MPC 隐私计算完全⽆关的辅助中间层,⼀系列的“浮标”置位算⼦,⽀持⾃定义Tensor类型。其内部默认的实现逻辑是和对应的 TF 原⽣算⼦⼀样的。
SecureOp 算⼦库
完整的前后端算⼦库,注册了对应的梯度函数;在内部实现中调⽤隐私协议层的抽象算⼦接⼝实现和 TF 的对接。
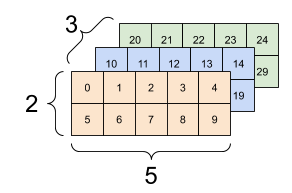
Rosetta 对 TensorFlow 的深度定制化
如上⼀篇⽂章整体介绍的那样,作为⾯向实际⼯业落地⽬标的隐私 AI 框架,Rosetta 对于 TF 的改造原则始终是为了提供更加便于 AI 开发者使⽤的上层接⼝,以及兼顾系统后端隐私协议的可扩展性。
Rosetta 整体⼯程架构
从系统架构和代码上看,改造的⼊⼝可以分为两⼤部分:
后端 C++ 部分的适配定制。主要以⾃定义算⼦的 kernel 形式进⾏适配。⼤部分接⼝的输⼊输出参数是以 tf.string 基础类型的 Tensor,⾥⾯封装的是⾃定义的密⽂数据。在隐私算⼦ SecureOps 的 kernel 内部会进⼀步调⽤统⼀的密码协议接⼝来完成 TF 到隐私计算功能的联通。
前端 Python 部分的适配定制。这⾥除了在 Python 前端引⼊我们⾃定义的算⼦库之外,还需要进⼀步改造 TF 中的⾃动求导功能等模块以实现对于新隐私算⼦的⾃动构建图、⾃动求导的⽀持。
从对程序的动态处理⻆度来看,如前⼀篇⽂章所说,Rosetta 是经过两个阶段的 Pass,来完成到底层多⽅协作的 MPC 处理程序的转换。这⾥⼤部分基于 TF 的前后端改造都是为了完成 StaticPass 阶段的转换,即将原⽣ Tensor 转换为⽀持⾃定义密⽂类型的 RttTensor,将原⽣ Operation 转换为⽀持 tf.string 格式输⼊输出的 RttOp ,并最终在图开始启动时进⼀步的转换为承载实际 MPC 操作的 SecureOp 。
细⼼的读者可以看出,上⾯在介绍 TF 的 customC++op 扩展机制的同时,我们已经展示了如何定义 Rosetta 中的单个新算⼦。接下来,我们介绍⼀下如何基于这些算⼦实现计算图的分阶段转换。
计算图的转换构建过程
引入 rosetta 库时
⽤户在前端执⾏ import lattciex.rosetta 之后,Rosetta 就会⽤ RttOp 静态替换掉原⽣ TF 中对应的原⽣ API 算⼦,且各个原⽣ Tensor 也会被包装⼀层到 RttTensor ,其与原⽣ Tensor 的主要区别是,其数据的基础类型是 tf.string,且对应的计算算⼦是 RttOp。这种基础类型的转换是基于 RttOp 算⼦库中的 TfToRtt 和 RttToTf 两个⽤于类型转换的算⼦来完成的。
Rosetta在import时的静态替换
调用 Session.run 接口时
我们同样 hook 了 Session.run ⼊⼝,在其内部完成从上⼀步骤中 RttOp 算⼦到 SecureOp 算⼦的转换。如果⽤户使⽤ TensorBoard ⼯具查看此时的运⾏图,就会看到我们在图上添加了⼀个和原⽣ TF 计算图基本同构的新⼦图,这个⼦图就是由 SecureOp 构成。
TensorBoard 可以查看得到的 SecureOp 计算图
和上⽂介绍的原⽣ TF 中的完整图构建过程⼀样,如果⽤户的程序含有模型训练过程,调⽤了优化器 Optimizer 的 minimize ⽅法,则我们还需要完成对 SecureOp 的反向梯度图⾃动⽣成的⽀持。
⾸先,我们需要注册各个 SecureOp 算⼦所对应的梯度函数。⽐如对于隐私矩阵乘法算⼦ SecureMatMul,我们按照底层梯度的计算逻辑,定义其梯度函数如下:
@ops.RegisterGradient("SecureMatmul") def SecureMatMulGrad(op, grad): """The gradient for the Secure MatMul operator.""" t_a = op.get_attr("transpose_a") t_b = op.get_attr("transpose_b") a = op.inputs[0] b = op.inputs[1] if not t_a and not t_b: grad_a = SecureMatMul(grad, b, transpose_b=True) grad_b = SecureMatMul(a, grad, transpose_a=True) elif not t_a and t_b: grad_a = SecureMatMul(grad, b) grad_b = SecureMatMul(grad, a, transpose_a=True) elif t_a and not t_b: grad_a = SecureMatMul(b, grad, transpose_b=True) grad_b = SecureMatMul(a, grad) elif t_a and t_b: grad_a = SecureMatMul(b, grad, transpose_a=True, transpose_b=True) grad_b = SecureMatMul(grad, a, transpose_a=True, transpose_b=True) return grad_a, grad_b
此外,由于我们使⽤ tf.string 来统⼀承载⾃定义的密⽂数据类型,⽽ TF 本身是不⽀持对于 tf.string 类型算⼦的⾃动求导的,所以 Rosetta 中还对 tf.python.ops.gradients_util 等⼊⼝进⾏了 hook 改造。⽐如,在下⾯这⾥,我们设定当 tensor 的基础类型为 string 时仍可以继续进⾏反向传播:
反向梯度图的⾃动⽣成
通过这些精细的定制化改造,最终就可以实现反向梯度⼦图的⾃动⽣成,可以极⼤的降低⽤户上⼿隐私计算的开发难度。
补充说明
并⾮所有的算⼦都需要转换为 SecureOp,这是因为如果⼀个局部⼦图中全部的输⼊都是本地的常量(公开的写定到代码中的数据,⽆需保护),那么就没有必要将这个⼦图转换为多⽅协作的隐私计算⽅式计算,这样可以减少不必要的计算时间。
转换时,由于此时知道了即将运⾏的完整⼦图的信息,⽐如 DAG 图上有多少了算⼦需要运⾏,所以可以在这⾥进⾏⼀些定制化的优化,⽐如优化底层协议中多⽅之间的并发通讯。
在通过上述过程完成在前端层到 SecureOp 图的构建后,接下⾥就是依赖 TensorFlow ⾃身的图执⾏引擎来调度执⾏各个 SecureOp 的后端实现了,在这个 kernal 中,为了和具体使⽤的隐私计算技术解耦,我们所调⽤的是密码协议接⼝,⽐如 SecureMatMul ⾥最终通过如下代码⽚段来调⽤内部“隐私计算引擎”。这⾥的内部细节,我们会在后续内容中加以介绍。
// call protocol ops vector
小结
在本篇⽂章中,我们进⼀步介绍了 Rosetta 是如何深度适配、定制化改造 TensorFlow 的各个组件以引⼊隐私计算功能的。与其他隐私 AI 开源框架相⽐,Rosetta 由于需要同时对 TensorFlow 的前端和后端进⾏扩展,并且完全复⽤对上层的 API 接⼝,所以定制化的程度更加深⼊。这⾥的改造是偏向于“系统易⽤性”这⼀⽬标的,不需要太多涉及 MPC 等隐私计算技术。
作者介绍
Rosetta 技术团队,⼀群专注于技术、玩转算法、追求⾼效的⼯程师。Rosetta 是⼀款基于主流深度学习框架 TensorFlow 的隐私 AI 框架,作为矩阵元公司⼤规模商业落地的重要引擎,它承载和结合了隐私计算、区块链和 AI 三种典型技术。
⽬前 Rosetta 已经在 Github 开源(https://github.com/LatticeX-Foundation/Rosettaf),欢迎关注并参与到 Rosetta 社区中来。
参考文献
[1] Abadi,Martín,etal."Tensorflow:A system for large-scale machine learning." 12th{USENIX}symposium on operat ing syst ems design and implement at ion({OSDI}16).2016.
[2] TensorFlow 对定制化 Op 扩展的⽀持:https://tensorflow.google.cn/guide/create_op
责任编辑:xj
原文标题:社区分享 | ⾯向隐私 AI 的 TensorFlow 深度定制化实践
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
-
开发
+关注
关注
0文章
370浏览量
40871 -
AI
+关注
关注
87文章
31097浏览量
269423 -
tensorflow
+关注
关注
13文章
329浏览量
60540
原文标题:社区分享 | ⾯向隐私 AI 的 TensorFlow 深度定制化实践
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

第四章:在 PC 交叉编译 aarch64 的 tensorflow 开发环境并测试
通力发布最新定制化电梯更新改造方案
宜科EEDS Slim数字化扩展组件介绍
TensorFlow是什么?TensorFlow怎么用?
前后端数据传输约定探讨
tensorflow和pytorch哪个更简单?
tensorflow和pytorch哪个好
tensorflow简单的模型训练
keras模型转tensorflow session
如何使用Tensorflow保存或加载模型
TensorFlow的定义和使用方法
英特尔联手日企研发后端芯片自动化制造技术
鸿蒙OS开发实例:【组件化模式】





 工商网监
工商网监
评论