 这些机器学习分类器性能标准你知道吗?
这些机器学习分类器性能标准你知道吗?
在机器学习算法中,在模型训练出来之后,总会去寻找衡量模型性能的指标。评价指标是针对将相同的数据,使用不同的算法模型,或者输入不同参数的同一种算法模型,而给出这个算法或者参数好坏的定量指标。在模型评估过程中,往往需要使用多种不同的指标协作评估一个模型的好坏,因为众多的评价指标中,大部分指标只能片面的反应模型的一部分特点,那么对模型的评估就会比较片面,在算法落地后也会出现很多问题。根据评估指标的反馈进行模型调整,这些都是机器学习在模型评估阶段的关键问题,也是一名合格的算法工程师应当具备的基本功[文献1]。
本文参考文献1, 2,详细介绍机器学习分类任务的常用评价指标:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、P-R曲线(Precision-Recall Curve)、F1 Score、混淆矩阵(Confuse Matrix)、ROC、AUC。
1 准确率(Accuracy)
准确率定义如下:
也就是被正确分类的样本个数与总样本的个数之比,对于二分类来说可以这样看:
其中(正、负样本代表两个不同类别):
真正例(True Positive, TP):标注的数据为正样本,被模型预测为正的正样本;
假正例(False Positive, FP):标注的数据为负样本,被模型预测为正的负样本;
假负例(False Negative, FN):标注的数据为负样本,被模型预测为负的正样本;
真负例(True Negative, TN):标注的数据为正样本,被模型预测为负的负样本;
准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷,就是在数据的类别不均衡,特别是一种类别数据特别多另一种类别数据特别少的情况下,准确率就不能客观评价算法的优劣了。举个例子:当负样本占99%时,分类器把所有样本都预测为负样本,那么对于这个模型来说可以获得99%的准确率,所以在样本数据极度不均衡的时候,选用这种方式去评价一个模型是不可取的。
2 精确率(Precision)
精准率又叫查准率,容易与准确率弄混,请记住这个“精”字,「它是针对一个类别预测结果而言的」,含义是在所有被预测为正的样本中实际为正的样本的概率,在预测为正样本的结果中,有多少把握可以预测正确,因为其他类别的数据也可能被预测成为该类别。以二分类(以下不特殊说明,都以二分类为例介绍)来说其公式如下:
精准率代表对正样本「结果」中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
3 召回率(Recall)
召回率又叫查全率,「它是针对原样本而言的」,即在实际为正的样本中被预测为正样本的概率,其公式如下:
精确率和召回率又是一对欢喜冤家(一个查准率,一个查全率)。引用wiki上的图,来理解一下:
实际中该如何选择这两个指标呢?因为精确率和召回率有不同的侧重点,并且精确率和召回率是一对此消彼长的度量,精确率高可能原因是原始样本中正样本预测为正样本比较少,负样本预测为正样本也比较多,那么这个时候召回率就低了,因为召回率是正样本预测为正样本的比率。例如,在预测股票的时候,更关心精准率,假如你买的股票现在有涨有跌,预测这些股票涨的多,那么这就是对我们有用的,因为所预测涨的股票都是你投钱的。而在预测病患的场景下,则更关注召回率,即真的患病的那些人中预测对了情况应该越多越好,即召回率越高越好。
因为两种精准率和召回率是此消彼长的参数,而在实际情况中,例如推荐系统中有这样的情形。在给用户推荐的N个数据中,我们都认为是预测为正的值,那么其中有用户喜欢的就是预测正样本预测为正样本的情形,即TP,其中用户不喜欢的就是预测负样本为正样本的情形,即FP。当准确率比较高的时候,那么类别就比较多,而用户实际喜欢的并没有那么多,而当召回率比较高,那么推送的类别少,用户可能想看更多的类别,推送的又没有。所以,在实际工程中,往往需要结合两个指标的结果,去寻找一个平衡点,使综合性能最大化。
4 P-R曲线
P-R曲线(Precision Recall Curve)是描述精确率/召回率变化的曲线,如下图所示,横轴为召回率,纵轴为精确率:
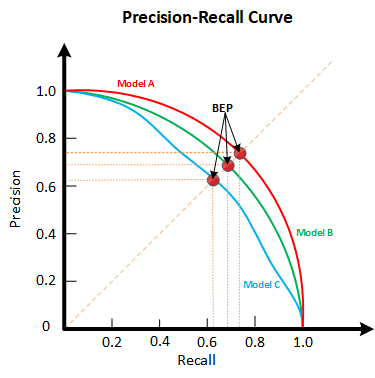
对于一个模型来说,其P-R曲线上的一个点代表着:在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时就可以计算出对应的召回率和精确率。改变这个阈值就可以得到一条P-R曲线。那么如何去看一个P-R曲线呢?若一个学习器A的P-R曲线被另一个学习器B的P-R曲线完全包住,则称:B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
5 F1-Score
除了使用P-R曲线去兼顾精准率和召回率一个模型之外,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均,使用最多也就是F1值了,即:
当F1较高时,模型的性能越好。
6 ROC曲线
介绍了这么多指标为什么还要介绍ROC(Receiver Operating Characteristic Curve,又称接受者操作特征曲线)曲线呢,因为ROC曲线有很多优点,经常作为评估二值分类器最重要的指标之一。如:「当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变」。在输出为概率分布的分类模型中,如果仅使用准确率、精确率、召回率作为评价指标进行模型对比时,都必须是基于某一个给定阈值的,对于不同的阈值,各模型的Metrics结果也会有所不同,这样就很难得出一个很置信的结果。需要注意的是P-R曲线是不依赖阈值的,但是在绘制P-R曲线的时候需要阈值。
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性率(True Positive Rate,TPR)。FPR和TPR的计算方法分别为:
其中,FP是所有负样本中预测为正样本那些负样本数目,N是真实负样本数目。
其中,TP是所有正样本中预测为正样本那些正样本数目,P是真是正样本数目。
上面定义有点绕,举个例子:假设有10位疑似癌症患者,其中有3位很不幸确实患了癌症(P=3),另外7位不是癌症患者(N=7)。医院对这10位疑似患者做了诊断,诊断出3位癌症患者,其中有2位确实是真正的患者(TP=2)。那么真阳性率TPR=TP/P=2/3。对于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(FP=1),那么假阳性率FPR=FP/N=1/7。对于“该医院”这个分类器来说,这组分类结果就对应ROC曲线上的一个点(1/7,2/3)。(还是有点绕?那就沉下心理一下)。下面就有一个ROC曲线,来欣赏一下。
「那么为什么ROC曲线衡量效果可以不用在意数据的分布呢?」举个例子:假设总样本中,90%是正样本,10%是负样本。因为TPR只关注90%正样本中有多少是被预测正确的,而与那10%负样本毫无关系,同理,FPR只关注10%负样本中有多少是被预测错误的,也与那90%正样本毫无关系。这样就避免了样本不平衡的问题。那么两者协作起来就能够很好地衡量一个模型了。
「那么如何绘制ROC曲线呢?」这里也需要我们通过阈值来绘制(「与之前一样,遍历所有阈值来绘制整条曲线的」)。当改变阈值时,那么预测出正样本和负样本的数目也随之变化,如下图:
「知道了如何绘制ROC曲线了,那么怎么去看ROC曲线呢,也就是说如何根据ROC曲线确定一个模型的好坏?即如何根据ROC曲线判断模型性能?」 FPR(假阳率)表示模型对于负样本误判的程度,而TPR(真阳率)表示模型对正样本召回的程度。可想而知:负样本误判的越少越好,正样本召回的越多越好。所以总结一下就是TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。可参考如下动态图进行理解:
也就是说:在进行模型的性能比较时,若一个模型A的ROC曲线被另一个模型B的ROC曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。下面再次借用文献2中的图片演示ROC曲线不随样本数目的变化而变化的动图,如下:
当然,我们也不可能总是通过看图去比较几个模型的性能,那么问题就来了,如何将图形进行量化呢?
7 AUC值
AUC(Area Under Curve)指的是ROC曲线下的面积大小,该值能够量化地反映基于ROC曲线衡量出的模型性能。计算AUC值只需要沿着ROC横轴做积分就可以了。由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1−p就可以得到一个更好的分类器),所以AUC的取值一般在0.5~1之间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。具体计算方法可参考文献[3]。
8 混淆矩阵
混淆矩阵(Confusion Matrix)也称错误矩阵,通过它可以直观地观察到算法的效果。它的每一列是样本的预测分类,每一行是样本的真实分类(反过来也可以),顾名思义,它反映了分类结果的混淆程度。混淆矩阵i行j列的原始是原本是类别i却被分为类别j的样本个数,计算完之后还可以对之进行可视化,可看看文献[2]中的混淆矩阵图片演示:
9 多分类
最基本的内容是二分类,多分类也可以拆分为多个二分类进行。在了解二分类的基础上,我们来看看如何衡量一个多分类模型的性能了,毕竟实际的问题属于多分类的概率是比较大的。
估算模型全局性能的方法有两种:宏平均(macro-average)和微平均(micro-average)。综合来看宏平均会比微平均更可靠一些,因为微平均受稀有类别影响更大。宏平均平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均平等考虑数据集中的每一个样本,所以它的值受到常见类别的影响比较大。
简单来说,宏平均就是先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,再算出F1值。微平均则是计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出F1值。同理可以使用这两种方式计算出其他的衡量指标。这两种计算公式如下:
原文标题:机器学习分类器性能标准(Accuracy、Precision、Recall、P-R曲线、F1等)你是否真的懂了?
文章出处:【微信公众号:自然语言处理爱好者】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
数据
+关注
关注
8文章
7017浏览量
89012 -
机器学习
+关注
关注
66文章
8416浏览量
132619
原文标题:机器学习分类器性能标准(Accuracy、Precision、Recall、P-R曲线、F1等)你是否真的懂了?
文章出处:【微信号:NLP_lover,微信公众号:自然语言处理爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【每天学点AI】KNN算法:简单有效的机器学习分类器
这些电源常用仿真软件,你都知道吗?
电源的这些常识你知道吗?
PCB打样不简单:这些特殊工艺你知道吗?

【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
深度学习中的时间序列分类方法
SMT贴片加工中的这些问题,你知道吗?

入门嵌入式系统这些知识你知道吗?
机器学习多分类任务深度解析
这些磁棒电感发热解决方法你知道几个
电抗器的这些特点你都知道吗







 工商网监
工商网监
评论