 GitHub nanodet开源移动端实时的Anchor-free检测模型,上线仅两天Star量已经超过200
GitHub nanodet开源移动端实时的Anchor-free检测模型,上线仅两天Star量已经超过200
目标检测一直是计算机视觉领域的一大难题,其目标是找出图像中的所有感兴趣区域,并确定这些区域的位置和类别。目标检测中的深度学习方法已经发展了很多年,并出现了不同类型的检测方法。 目前,深度学习目标检测方法主要分为两大类,分别是两阶段式和单阶段式目标检测算法。两阶段式目标检测框架首先生成候选区域,然后将其分类成不同的目标类别,代表模型有 R-CNN、Fast R-CNN 等;单阶段式目标检测框架将目标检测任务视为一个统一的端到端回归问题,代表模型有 MultiBox、YOLO、SSD 等。这类框架通常结构更简单,检测速度也更快。 深度学习目标检测方法还可划分为 Anchor-base 和 Anchor-free 两大类,今年又出现了将 Transformer 用于目标检测的尝试,各种方法百花齐放。但是,在移动端目标检测算法上,YOLO 系列和 SSD 等 Anchor-base 的模型一直占据主导地位。
近日,GitHub 上出现了一个项目 nanodet,它开源了一个移动端实时的 Anchor-free 检测模型,希望能够提供不亚于 YOLO 系列的性能,而且同样方便训练和移植。该项目上线仅两天,Star 量已经超过 200。
项目地址:https://github.com/RangiLyu/nanodet NanoDet 模型介绍 NanoDet 是一个速度超快和轻量级的移动端 Anchor-free 目标检测模型。该模型具备以下优势:
超轻量级:模型文件大小仅 1.8m;
速度超快:在移动 ARM CPU 上的速度达到 97fps(10.23ms);
训练友好:GPU 内存成本比其他模型低得多。GTX1060 6G 上的 Batch-size 为 80 即可运行;
方便部署:提供了基于 ncnn 推理框架的 C++ 实现和 Android demo。
模型性能 目前开源的 NanoDet-m 模型在 320x320 输入分辨率的情况下,整个模型的 Flops 只有 0.72B,而 yolov4-tiny 则有 6.96B,小了将近十倍。模型的参数量也只有 0.95M,权重文件在使用 ncnn optimize 进行 16 位存储之后,只有 1.8mb。 尽管模型非常的轻量,但是它的性能不容小觑。在与其他模型进行比较时,项目作者选择使用 COCO mAP (0.5:0.95) 作为评估指标,兼顾检测和定位的精度,在 COCO val 5000 张图片上测试,并且没有使用 Testing-Time-Augmentation。在这种设置下,320 分辨率输入能够达到 20.6 的 mAP,比 tiny-yolov3 高 4 分,只比 yolov4-tiny 低 1 个百分点。在将输入分辨率与 YOLO 保持一致,都使用 416 输入的情况下,NanoDet 与 yolov4-tiny 得分持平。具体结果如下表所示:
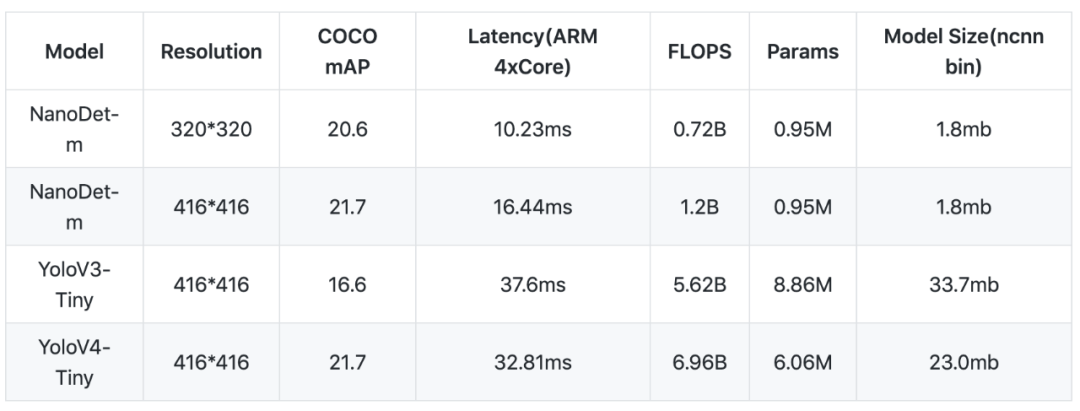
以上性能基于 ncnn 和麒麟 980 (4xA76+4xA55) ARM CPU 获得。 此外,项目作者将 ncnn 部署到手机(基于 ARM 架构的 CPU 麒麟 980,4 个 A76 核心和 4 个 A55 核心)上之后跑了一下 benchmark,模型前向计算时间只要 10 毫秒左右,而 yolov3 和 v4 tiny 均在 30 毫秒的量级。在安卓摄像头 demo app 上,算上图片预处理、检测框后处理以及绘制检测框的时间,NanoDet 也能轻松跑到 40+FPS。
NanoDet 和 yolov4-tiny 的性能对比。 最后,该项目提供了 Android demo、C++ demo 和 Python demo。NanoDet 在安卓端的目标检测结果如下所示:
NanoDet 方法 NanoDet 是一种 FCOS 式的单阶段 anchor-free 目标检测模型,它使用 ATSS 进行目标采样,使用 Generalized Focal Loss 损失函数执行分类和边框回归(box regression)。 据项目作者介绍,该项目的主要目的是希望开源一个移动端实时的 Anchor-free 检测模型,能够提供不亚于 YOLO 系列的性能,并且方便训练和移植。为此,他参考了以下研究: 最终得到的 NanoDet 模型架构如下:
损失函数 项目作者想要实现一个 FCOS 式的 anchor-free 目标检测模型,但将 FCOS 轻量化处理时,由于 FCOS 的 centerness 分支在轻量级的模型上很难收敛,模型效果不如预期。 最终,NanoDet 使用了李翔等人提出的 Generalized Focal Loss 损失函数。该函数能够去掉 FCOS 的 Centerness 分支,省去这一分支上的大量卷积,从而减少检测头的计算开销,非常适合移动端的轻量化部署。
图源:https://arxiv.org/pdf/2006.04388.pdf 检测头轻量化 找到合适的损失函数后,如何使其在轻量级模型上发挥作用呢? 首先需要优化的是检测头。 FCOS 系列使用了共享权重的检测头,即对 FPN 出来的多尺度 Feature Map 使用同一组卷积预测检测框,然后每一层使用一个可学习的 Scale 值作为系数,对预测出来的框进行缩放。
图源:https://openaccess.thecvf.com/content_ICCV_2019/papers/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.pdf 这么做的好处是能够将检测头的参数量降低为不共享权重状态下的 1/5。这对于光是检测头就拥有数百通道卷积的大模型来说非常有用,但是对于轻量化模型来说,共享权重检测头并没有很大的意义。由于移动端模型推理由 CPU 执行计算,共享权重并不会带来推理过程的加速,而且在检测头非常轻量的情况下,共享权重使其检测能力进一步下降,因此项目作者认为选择对每一层特征使用一组卷积比较合适。 同时,FCOS 系列在检测头上使用了 Group Normalization(GN)作为归一化方式,GN 对比 BN(Batch Normalization)有很多好处,但是却有一个缺点:BN 在推理时能够将其归一化的参数直接融合进卷积中,可以省去这一步计算,而 GN 则不行。为了能够节省归一化操作的时间,项目作者选择将 GN 替换为 BN。 FCOS 的检测头使用了 4 个 256 通道的卷积作为一个分支,也就是说在边框回归和分类两个分支上一共有 8 个 c=256 的卷积,计算量非常大。为了将其轻量化,项目作者首先选择用深度可分离卷积替换普通卷积,并且将卷积堆叠的数量从 4 个减少为 2 组。在通道数上,将 256 维压缩至 96 维,之所以选择 96,是因为需要将通道数保持为 8 或 16 的倍数,能够享受到大部分推理框架的并行加速。 最后,项目作者借鉴了 YOLO 系列的做法,将边框回归和分类使用同一组卷积进行计算,然后 split 成两份。最终得到的轻量化检测头如下图所示:
FPN 层改进 目前针对 FPN 的改进有许多,如 EfficientDet 使用了 BiFPN,YOLO v4 和 v5 使用了 PAN,除此之外还有 BalancedFPN 等等。BiFPN 虽然性能强大,但是堆叠的特征融合操作会导致运行速度降低,而 PAN 只有自上而下和自下而上两条通路,非常简洁,是轻量级模型特征融合的好选择。 原版的 PAN 和 YOLO 系列中的 PAN 都使用了 stride=2 的卷积进行大尺度 Feature Map 到小尺度的缩放。而该项目出于轻量化的考虑,选择完全去掉 PAN 中的所有卷积,只保留从骨干网络特征提取后的 1x1 卷积来进行特征通道维度的对齐,上采样和下采样均使用插值来完成。与 YOLO 使用的 concatenate 操作不同,项目作者选择将多尺度的 Feature Map 直接相加,使整个特征融合模块的计算量变得非常小。 最终得到的极小版 PAN 结构非常简单:
NanoDet 使用的超轻量 PAN(图源:https://zhuanlan.zhihu.com/p/306530300) 骨干网络 项目作者选择使用 ShuffleNetV2 1.0x 作为骨干网络,他去掉了该网络的最后一层卷积,并且抽取 8、16、32 倍下采样的特征输入到 PAN 中做多尺度的特征融合。整个骨干模型使用了 Torchvision 提供的代码,能够直接加载 Torchvision 上提供的 imagenet 预训练权重,对加快模型收敛起到很大帮助。 目前,项目作者已将 Pytorch 训练代码、基于 NCNN 的 Linux 和 Windows C++ 部署代码以及 Android 摄像头 Demo 全部开源,并在 Readme 中提供了详细教程,参见项目 GitHub 主页。
责任编辑:PSY
原文标题:1.8M超轻量目标检测模型NanoDet,比YOLO跑得快,上线两天Star量超200
-
检测模型
+关注
关注
0文章
17浏览量
7309 -
移动端
+关注
关注
0文章
41浏览量
4403 -
GitHub
+关注
关注
3文章
471浏览量
16457
原文标题:1.8M超轻量目标检测模型NanoDet,比YOLO跑得快,上线两天Star量超200
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
腾讯混元大模型开源成绩斐然,GitHub Star数近1.4万
AI模型部署边缘设备的奇妙之旅:目标检测模型
ADS1299用一个频率为1Hz的正弦波来作为模拟输入信号,当峰峰值超过10mV是就已经满量程了,为什么?
腾讯混元大模型上线并开源文生视频能力
国家管网集团与华为联合打造“管网”大模型
MediaTek天玑移动平台赋能腾讯会议端侧AI人像分割模型
尊界S800预定火爆,两天超2000台
《DNK210使用指南 -CanMV版 V1.0》第三十九章 YOLO2人脸检测实验
GitHub Copilot引入多模型支持
GitHub推出GitHub Models服务,赋能开发者智能选择AI模型
tcp方式连接不了服务器了,服务器代码还能开源吗?
RT-Thread 新里程碑达成——GitHub Star 破万!






 工商网监
工商网监
评论