 Google气球互联网:用 AI 控制气球导航,不怕 WiFi 被 “吹”出服务区
Google气球互联网:用 AI 控制气球导航,不怕 WiFi 被 “吹”出服务区
更长的飞行时间,更少的能量消耗,更复杂的飞行动作。”这是 Google「气球互联网」项目 “Project Loon”交回的最新成绩单。
Google 母公司 Alphabet 于 2013 年 6 月正式启动 Project Loon 计划,该计划旨在将 AI 技术与超压气球相结合,为更多地区提供低价且高速的无线互联网服务,尤其是与市中心相距甚远的偏远地区。
前段时间,Loon 顺利完成了最新一轮飞行测试。
昨日,最新分析结果显示,在飞跃太平洋的 39 天里,Loon 气球表现出了比以往更好的性能——基于最新人工智能系统,它能够更快地计算出气球的最佳导航路径;在目标区域上飞行的时间更长,消耗的能量更少,更关键的是,它还提出了研究团队此前未曾想到过的新的导航动作。
而这一最新人工智能系统正是基于强化学习( Reinforcement-Learnin,RL)算法的 AI 系统。
研究人员称,这是他们首次将 RL 系统应用到航空航天产品中。Loon 取得的成绩,表明 RL 可以作为解决现实世界自主控制问题的有效解决方案。
目前,有关这项研究发现的论文成果已经登上了《Nature》杂志。
接下来,我们来具体聊一下:Google 为什么要开展「气球互联网」计划,以及强化学习系统到底解决了哪些难题。
「气球互联网」计划
你可能难以想象,在互联网如此普及的当下,全球还有一半的以上的用户无法享受到这项服务。
2013 年,为了让 30 多亿用户所在的偏远地区覆盖互联网,Alphabet 正式启动了高空互联网服务项目。之后几年,陆续有不少科技公司也加入了这个队伍,比如 SpaceX、OneWeb 等。
其中最值得一提的,是马斯克的 “太空互联网”计划,他计划向太空发射 42000 颗通信卫星,在地球低空轨道形成一个巨型星座来完成与地面的通信任务。目前他已经成功发射了近 900 颗卫星。
相比于马斯克的「太空卫星」,Alpbet 则把通信业务的核心放在了「高空气球」上。
具体来说,用「高空气球」实现地面通信的过程如下:当气球上升到高空平流层后(超过云层 12 英里高),利用 “太阳能技术”吸收能量以作为电力支持,然后通过 “算法系统控制( Algorithmic Control)”让气球上下飘动,并根据风向捕捉风流信号,将气球稳定在一个固定区域。
最后通过 “网状回路(Mesh Networking)技术”,将互联网数据包从一个气球传输至另一个气球;从气球传输至在屋顶建立天线的家庭和企业用户;最后将这些用户的数据传输出去。
这一过程中,如果气球在平流层飞行的时间越长,意味着 Loon 越可以在较低成本下为目标区域提供更长久的连通性,这也意味着互联网服务将不仅可以覆盖到更偏远的地区,而且它的价格也会更便宜。
在近几年的飞行测试中,Loon 的平流层飞行时长不断刷新着世界纪录,目前最高成绩已经达到 312 天,接近一整年。
这项最高飞行纪录开始于 2019 年 5 月,Loon 从波多黎各(Puerto Rico)起飞,进入秘鲁(Peru),然后在那里进行为期三个月的飞行测试。测试结束后,向南越过太平洋,于今年 3 月在墨西哥的巴哈(Baja)登录。
这项记录刷新了当时 223 天的最高记录,Loon 首席技术官 Sal Candido 在博客中表示,创纪录的飞行成绩是该公司努力发展技术,并以创新的方式推动硬件和软件向不断升级的结果。
当时 Loon 的软件系统还并未引入 RL。
目前,Loon 已经在澳大利亚、昆士兰、肯尼亚、新西兰、加州中央峡谷以及巴西利亚东北部等多个地区提供了 Loon 测试服务。去年,因受到飓风袭击的影响,美国电信运营商还利用 Project Loon 为超过 25 万的灾民提供了网络连接。
不过,在以上服务过程中,Loon 的平流层导航问题依然面临很大的挑战。
此次,基于 RL 系统的提出为解决当前的挑战提供了一种全新的解决方案,与原有的气球导航系统相比,RL 算法改善了飞行过程中的决策时间问题。
谷歌加拿大公司的研究科学家、论文一作马克 · 贝勒马尔(Marc Bellemare)表示,
通过强化学习,我们可以根据数据决定该如何操作,AI 不仅可以做出决策,而且可以根据移动的时间做出实时决策。
Loon:强化学习飞行控制器
如果在一个区域提供完全的网络覆盖,Loon 一次至少要运行 5 到 10 个气球。如果覆盖范围扩大,需要调用周围的备用气球,在空中组建一个更大的网状网络。
在这一过程中,气球一般会出现以下状况:一是因电池报废等因素,导致气球寿命缩短并自动降落。二是受飓风等恶劣天气影响,气球被吹出固定服务区;
三是最关键也是难度最高的气球导航。
上文已经提到过,Loon 的气球导航是通过球体上下移动,寻找合适的气流来进行导航。
如下图(a)气球通过在不同高度的风之间移动来接近它的指定位置。(b)显示了气球的飞行线路,蓝色圆直径代表 50 公里,为气球之间的最佳距离。
但气流是不稳定的东西。靠风在天空中移动就像使用一个道路网,在那里街道会改变方向、车道数和速度限制,甚至在不可预知的时间完全消失。
因此要做到这一点就需要一套更复杂的算法—强化学习。通过训练飞行控制器,RL 可以形成一套控制策略,以处理高维的、异质的输入,并优化长期目标。比如,RL 已经在 Dota 2 等即时策略性游戏中多次战胜人类顶级玩家,而且在长远策略方面表现惊人。
而对于一个好的飞行控制器,需要确保三点:精准且丰富和数据集,最低负载消耗以及低计算成本。
在数据集方面,研究人员根据欧洲中期天气预报中心(ECMWF)的全球再分析数据(ERA5)创建了可信的风数据集,并通过数据集的模型训练重新解释历史天气观测的结果。(ERA5 提供了用程序噪声修改的基准风,通过产生高分辨率风场改变驱动程序噪声的随机种子,可以提高控制器建模误差的鲁棒性。)
在最低负载消耗方面,研究人员将部署控制器的平均功率控制在了 StationSeeker 之下(之前的风控制系统),同时使用奖励 r 对目标进行了编码。当气球距离保持在 50 公里范围内时,r=1 为最大值。当然这种奖励也与气球的状态有关,也就是说,它的响应随时间 t 的变化而提供不同的指示(上升、下降或停留)
当系数小于 1 时,最优控制器将使未来回报的预测折现总和最大化,即 “回报”。
其中 E 表示期望值。Rs 表示飞行控制器从初始状态形成的长期值。
最后,计算成本主要体现在风的测量上,研究人员使用高斯过程将气球的测量结果与 ECMWF 的预报结果相结合,将风预报作为先验平均值。后验分布的方差量化了不同风估计的不确定性。作为控制器的输入,对气球正上方和下方的风大小和相对方位进行编码,在 181 个气压等级下,范围为 5 kPa 到 14 kPa。
太平洋高空测试
基于以上 RL 控制器,研究人员在太平洋上空进行了为期 39 天的气球导航测试。
从 2019 年 12 月 17 日—2020 年 1 月 25 日,Loon 累计飞行了约 2884 小时。这些数据被划分为 851 个三小时时间,每个时间段作为一个独立样本。最终测试结果显示,
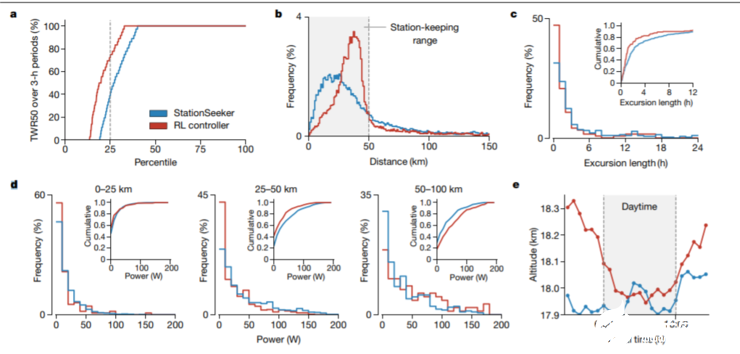
RL 控制器在平流层内飞行的时间更长(TWR50 79% 对 72%;U=850, 410.5,P《10-4);高度控制使用的功率更少(29w 对 33w,U=1048,814,P》10-4)。
与 StationSeeker 相比,在 50 公里射程内,RL 控制器根据风况使用不同的策略,可以使其在 25-50km 射程内花费更多的时间(图 4b);通过主动移动以返回目标区域,缩短了偏移时间(图 4c)。同时也让它节省了更多能耗(图 d)最后,RL 控制器利用海拔高度将电池容量过剩的太阳能转化为了势能(图 4e)。
这些结果表明,强化学习是解决现实世界中自主控制问题的有效解决方案,在传统控制方法(StationSeeker)无法满足要求的情况下,需要创建与真实动态环境持续交互的人工智能体。更长的飞行时间,更少的能量消耗,更复杂的飞行动作。
这是 Google「气球互联网」项目“Project Loon”交回的最新成绩单。
Google 母公司 Alphabet 于 2013 年 6 月正式启动 Project Loon 计划,该计划旨在将 AI 技术与超压气球相结合,为更多地区提供低价且高速的无线互联网服务,尤其是与市中心相距甚远的偏远地区。
前段时间,Loon 顺利完成了最新一轮飞行测试。
昨日,最新分析结果显示,在飞跃太平洋的 39 天里,Loon 气球表现出了比以往更好的性能——基于最新人工智能系统,它能够更快地计算出气球的最佳导航路径;在目标区域上飞行的时间更长,消耗的能量更少,更关键的是,它还提出了研究团队此前未曾想到过的新的导航动作。
而这一最新人工智能系统正是基于强化学习( Reinforcement-Learnin,RL)算法的 AI 系统。
研究人员称,这是他们首次将 RL 系统应用到航空航天产品中。Loon 取得的成绩,表明 RL 可以作为解决现实世界自主控制问题的有效解决方案。
目前,有关这项研究发现的论文成果已经登上了《Nature》杂志。
接下来,我们来具体聊一下:Google 为什么要开展「气球互联网」计划,以及强化学习系统到底解决了哪些难题。
「气球互联网」计划
你可能难以想象,在互联网如此普及的当下,全球还有一半的以上的用户无法享受到这项服务。
2013 年,为了让 30 多亿用户所在的偏远地区覆盖互联网,Alphabet 正式启动了高空互联网服务项目。之后几年,陆续有不少科技公司也加入了这个队伍,比如 SpaceX、OneWeb 等。
其中最值得一提的,是马斯克的“太空互联网”计划,他计划向太空发射 42000 颗通信卫星,在地球低空轨道形成一个巨型星座来完成与地面的通信任务。目前他已经成功发射了近 900 颗卫星。
相比于马斯克的「太空卫星」,Alpbet 则把通信业务的核心放在了「高空气球」上。
具体来说,用「高空气球」实现地面通信的过程如下:当气球上升到高空平流层后(超过云层 12 英里高),利用“太阳能技术”吸收能量以作为电力支持,然后通过“算法系统控制( Algorithmic Control)”让气球上下飘动,并根据风向捕捉风流信号,将气球稳定在一个固定区域。
最后通过“网状回路(Mesh Networking)技术”,将互联网数据包从一个气球传输至另一个气球;从气球传输至在屋顶建立天线的家庭和企业用户;最后将这些用户的数据传输出去。
这一过程中,如果气球在平流层飞行的时间越长,意味着 Loon 越可以在较低成本下为目标区域提供更长久的连通性,这也意味着互联网服务将不仅可以覆盖到更偏远的地区,而且它的价格也会更便宜。
在近几年的飞行测试中,Loon 的平流层飞行时长不断刷新着世界纪录,目前最高成绩已经达到 312 天,接近一整年。
这项最高飞行纪录开始于 2019 年 5 月,Loon 从波多黎各(Puerto Rico)起飞,进入秘鲁(Peru),然后在那里进行为期三个月的飞行测试。测试结束后,向南越过太平洋,于今年 3 月在墨西哥的巴哈(Baja)登录。
这项记录刷新了当时 223 天的最高记录,Loon 首席技术官 Sal Candido 在博客中表示,创纪录的飞行成绩是该公司努力发展技术,并以创新的方式推动硬件和软件向不断升级的结果。
当时 Loon 的软件系统还并未引入 RL。
目前,Loon 已经在澳大利亚、昆士兰、肯尼亚、新西兰、加州中央峡谷以及巴西利亚东北部等多个地区提供了 Loon 测试服务。去年,因受到飓风袭击的影响,美国电信运营商还利用 Project Loon 为超过 25 万的灾民提供了网络连接。
不过,在以上服务过程中,Loon 的平流层导航问题依然面临很大的挑战。
此次,基于 RL 系统的提出为解决当前的挑战提供了一种全新的解决方案,与原有的气球导航系统相比,RL 算法改善了飞行过程中的决策时间问题。
谷歌加拿大公司的研究科学家、论文一作马克·贝勒马尔(Marc Bellemare)表示,
通过强化学习,我们可以根据数据决定该如何操作,AI 不仅可以做出决策,而且可以根据移动的时间做出实时决策。
Loon:强化学习飞行控制器
如果在一个区域提供完全的网络覆盖,Loon 一次至少要运行 5 到 10 个气球。如果覆盖范围扩大,需要调用周围的备用气球,在空中组建一个更大的网状网络。
在这一过程中,气球一般会出现以下状况:一是因电池报废等因素,导致气球寿命缩短并自动降落。二是受飓风等恶劣天气影响,气球被吹出固定服务区;
三是最关键也是难度最高的气球导航。
上文已经提到过,Loon 的气球导航是通过球体上下移动,寻找合适的气流来进行导航。
如下图(a)气球通过在不同高度的风之间移动来接近它的指定位置。(b)显示了气球的飞行线路,蓝色圆直径代表 50 公里,为气球之间的最佳距离。
但气流是不稳定的东西。靠风在天空中移动就像使用一个道路网,在那里街道会改变方向、车道数和速度限制,甚至在不可预知的时间完全消失。
因此要做到这一点就需要一套更复杂的算法—强化学习。通过训练飞行控制器,RL 可以形成一套控制策略,以处理高维的、异质的输入,并优化长期目标。比如,RL 已经在 Dota 2 等即时策略性游戏中多次战胜人类顶级玩家,而且在长远策略方面表现惊人。
而对于一个好的飞行控制器,需要确保三点:精准且丰富和数据集,最低负载消耗以及低计算成本。
在数据集方面,研究人员根据欧洲中期天气预报中心(ECMWF)的全球再分析数据(ERA5)创建了可信的风数据集,并通过数据集的模型训练重新解释历史天气观测的结果。(ERA5 提供了用程序噪声修改的基准风,通过产生高分辨率风场改变驱动程序噪声的随机种子,可以提高控制器建模误差的鲁棒性。)
在最低负载消耗方面,研究人员将部署控制器的平均功率控制在了 StationSeeker 之下(之前的风控制系统),同时使用奖励r对目标进行了编码。当气球距离保持在 50 公里范围内时,r=1 为最大值。当然这种奖励也与气球的状态有关,也就是说,它的响应随时间t的变化而提供不同的指示(上升、下降或停留)
当系数小于 1 时,最优控制器将使未来回报的预测折现总和最大化,即“回报”。
其中E表示期望值。Rs表示飞行控制器从初始状态形成的长期值。
最后,计算成本主要体现在风的测量上,研究人员使用高斯过程将气球的测量结果与 ECMWF 的预报结果相结合,将风预报作为先验平均值。后验分布的方差量化了不同风估计的不确定性。作为控制器的输入,对气球正上方和下方的风大小和相对方位进行编码,在 181 个气压等级下,范围为 5 kPa 到 14 kPa。
太平洋高空测试
基于以上 RL 控制器,研究人员在太平洋上空进行了为期 39 天的气球导航测试。
从 2019 年 12 月 17 日—2020 年 1 月 25 日,Loon 累计飞行了约 2884 小时。这些数据被划分为 851 个三小时时间,每个时间段作为一个独立样本。最终测试结果显示,
RL 控制器在平流层内飞行的时间更长(TWR50 79% 对 72%;U=850, 410.5,P《10-4);高度控制使用的功率更少(29w 对 33w,U=1048,814,P《10-4)。
与 StationSeeker 相比,在 50 公里射程内,RL 控制器根据风况使用不同的策略,可以使其在 25-50km 射程内花费更多的时间(图 4b);通过主动移动以返回目标区域,缩短了偏移时间(图 4c)。同时也让它节省了更多能耗(图d)最后,RL 控制器利用海拔高度将电池容量过剩的太阳能转化为了势能(图 4e)。
这些结果表明,强化学习是解决现实世界中自主控制问题的有效解决方案,在传统控制方法(StationSeeker)无法满足要求的情况下,需要创建与真实动态环境持续交互的人工智能体。
责任编辑:PSY
-
Google
+关注
关注
5文章
1766浏览量
57576 -
互联网
+关注
关注
54文章
11163浏览量
103387 -
AI
+关注
关注
87文章
30996浏览量
269292
发布评论请先 登录
相关推荐
高速服务区充电桩远程监控运维管理系统方案
高速服务区供水泵站智能管理系统方案
Cloudflare发布2024年度互联网流量趋势报告
Coremail亮相世界互联网大会“互联网之光”博览会

浅谈高速公路服务区光储充电站运行解决方案

中国高速服务区加油站应用触摸屏查询一体机智慧便民

ESP8266无法连接到互联网是怎么回事?
【HZHY-AI300G智能盒试用连载体验】+ 智能工业互联网网关
heap连上互联网的时候,heap空间慢慢的就变小了,直到最后程序僵死在那,为什么?
esp8266已连接到Wifi但无法连接到互联网,为什么?
工业互联网平台中什么是关键
什么是卫星互联网?卫星互联网的组成






 工商网监
工商网监
评论