 加法网络再突破—NeurIPS 2020 Spotlight
加法网络再突破—NeurIPS 2020 Spotlight
华为诺亚方舟实验室联合悉尼大学发布论文《Kernel Based Progressive Distillation for Adder Neural Networks》,提出了针对加法神经网络的蒸馏技术,ResNet-34和ResNet-50网络在ImageNet上分别达到了68.8%和76.8%的准确率,效果与相同结构的CNN相比持平或超越,该论文已被NeurIPS2020接收。
开源链接:
huawei-noah/AdderNetgithub.com
论文链接:
https://arxiv.org/pdf/2009.13044.pdfarxiv.org
研究背景
深度卷积神经网络(CNN)被广泛应用于诸多计算机视觉领域的实际任务中(例如,图片分类、物体检测、语义分割等)。然而,为了保证性能,神经网络通常是过参数化的,因此会存在大量的冗余参数。近期提出的加法神经网络(ANN),通过将卷积操作中的距离度量函数替换为L1距离,极大减少了神经网络中的乘法操作,从而减少了网络运行所需的功耗和芯片面积。
然而,ANN在准确率方面和同结构的CNN相比仍然有一定差距,在某种程度上限制了ANN在实际应用中对CNN的替换。为了提高ANN的性能,我们提出了一种基于核的渐进蒸馏方法。具体的,我们发现一个训练好的ANN网络其参数通常服从拉普拉斯分布,而一个训练好的CNN网络其参数通常服从高斯分布。因此,我们对网络中间层的特征图输出进行核变换后,使用距离度量函数估计教师网络(CNN)和学生网络(ANN)之间的损失。对于最后一层,我们使用传统的KL散度估计两个网络之间的损失。同时,在训练中我们使用随机初始化的教师网络,与学生网络同时训练,以减少两个网络之间参数分布的差异性。
实验表明,我们的算法得到的ANN能够在CIFAR-10,CIFAR-100,ImageNet等标准图片分类数据集上达到或超越同结构CNN的准确率。
对网络中间层特征图输出进行核变换
ANN本身精度不好的原因是原始ANN在反向传播时,使用的是近似的梯度,导致目标函数无法向着最小的方向移动。传统KD方法应用到ANN上效果不佳的原因,在于ANN的权重分布是拉普拉斯分布,而CNN的权重分布为高斯分布,因此分布不同导致无法直接对中间层的feature map使用KD方法。本方法首先将核变换作用于教师网络和学生网络的中间层输出,并使用1x1卷积对新的输出进行配准。之后,结合最后一层的蒸馏损失与分类损失,得到整体的损失函数。
渐进式蒸馏算法
传统的蒸馏方法使用固定的,训练好的教师网络来教学生网络。这样做会带来问题。由于教师网络和学生网络处于不同的训练阶段,因此他们的分布会因为训练阶段的不同而不同,所以会导致KD方法效果不好。因此我们采用渐进式蒸馏方法,让教师网络和学生网络共同学习,有助于KD方法得到好的结果。即目标函数变为:
其中b为当前的step。
实验结果
我们在CIFAR-10、CIFAR-100、ImageNet三个数据集上分别进行了实验。
下表是在CIFAR-10和CIFAR-100数据集上的结果,我们使用了VGG-small、ResNet-20与ResNet-32作为教师网络,同结构的ANN作为学生网络。可以看到,使用了本方法得到的ANN在分类准确率上相比原始的ANN有大幅度的提升,并且能够超过同结构的CNN模型。表格中#Mul表示网络中乘法操作的次数。#Add表示加法操作次数,#XNOR表示同或操作的次数。
下表展示了在ImageNet数据集上的结果,我们使用ResNet-18与ResNet-50网络作为教师网络,同结构的ANN作为学生网络。结果显示我们的方法得到的ANN在分类准确率上相比同结构CNN基本相同或能够超越。
最后,我们展示了ResNet-20,ANN-20与通过本方法得到的PKKD ANN-20模型在CIFAR-10与CIFAR-100数据集上的训练精度曲线与测试精度曲线。
图中的实线表示训练精度,虚线表示测试精度。在两个数据集中,CNN的训练和测试准确率都超过了原始的ANN模型。这是因为在训练原始ANN时,反向传播的梯度使用的是L2 norm来近似,因此梯度方向是不准确的。当使用本方法后,CNN的训练过程可以指导ANN的训练,因此可以得到更好的结果。同时,知识蒸馏方法能够帮助学生网络防止过拟合,这也是我们的方法有最低的训练精度和最高的测试精度的原因。
推荐阅读
文章首发知乎,更多深度模型压缩相关的文章请关注深度学习压缩模型论文专栏。
审核编辑:符乾江
-
计算机视觉
+关注
关注
8文章
1695浏览量
45911 -
深度学习
+关注
关注
73文章
5485浏览量
120920
发布评论请先 登录
相关推荐
加法运放电路实验报告数据分析
加法运放电路输出电压是多少
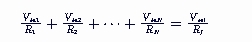
加法器是时序逻辑电路吗
请问增益为1的加法器有哪些?
串行加法器和并行加法器的区别?
加法器的原理是什么 加法器有什么作用

同相加法器和反相加法器的区别是什么
加法放大器的原理和应用
加法器ICL7660M/TR芯片发热问题?
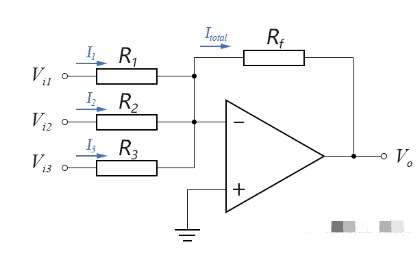
什么是反相加法运算电路?反相加法运算电路与减法运算电路
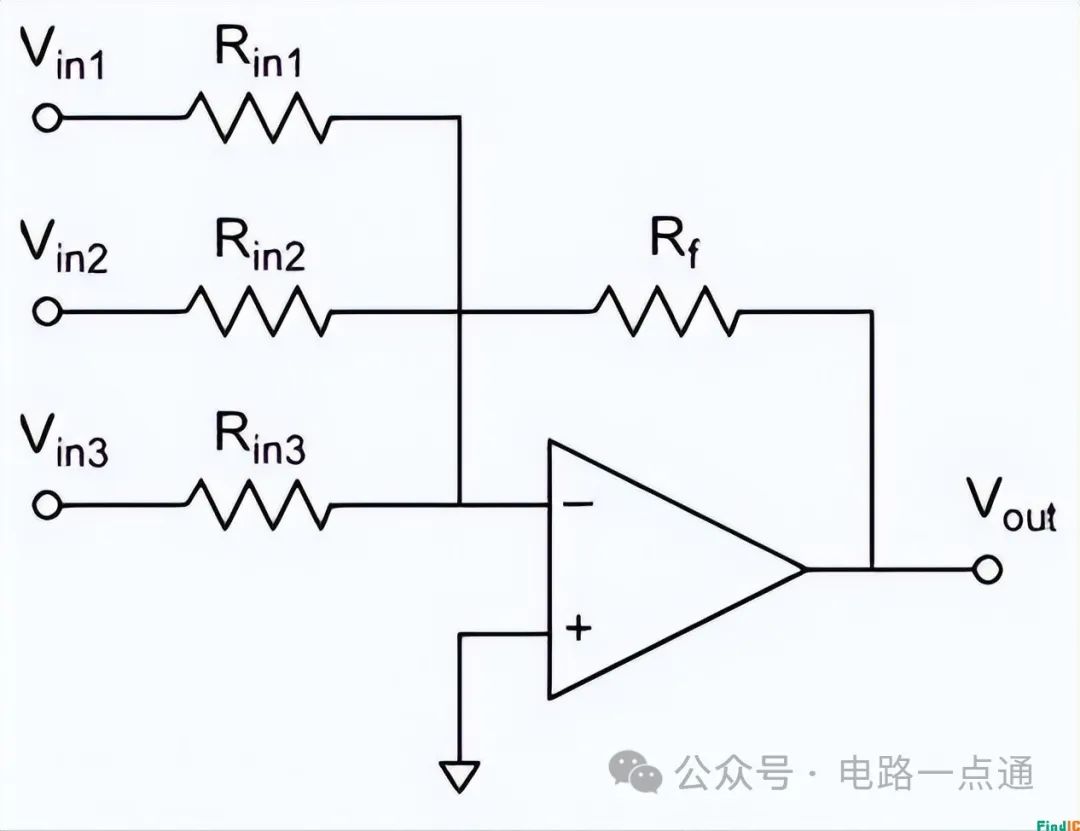
反相加法运算电路原理介绍





 工商网监
工商网监
评论