 sklearn的API参数解析:sklearn.linear_model.LinearRegression
sklearn的API参数解析:sklearn.linear_model.LinearRegression
sklearn.linear_model.LinearRegression
调用
sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
Parameters
fit_intercept
释义:是否计算该模型的截距。
设置:bool型,可选,默认True,如果使用中心化的数据,可以考虑设置为False,不考虑截距。
normalize
释义:是否对数据进行标准化处理
设置:bool型,可选,默认False,建议将标准化的工作放在训练模型之前,通过设置sklearn.preprocessing.StandardScaler来实现,而在此处设置为false
当fit_intercept设置为false的时候,这个参数会被自动忽略。
如果为True,回归器会标准化输入参数:减去平均值,并且除以相应的二范数
copy_X
释义:是否对X复制
设置:bool型、可选、默认True,如为false,则即经过中心化,标准化后,把新数据覆盖到原数据上
n_jobs
释义:计算时设置的任务个数,这一参数的对于目标个数>1(n_targets>1)且足够大规模的问题有加速作用
设置:int or None, optional, 默认None,如果选择-1则代表使用所有的CPU。
Attributes
coef_
释义:对于线性回归问题计算得到的feature的系数
输出:如果输入的是多目标问题,则返回一个二维数组(n_targets, n_features);
如果是单目标问题,返回一个一维数组 (n_features,)
rank_
释义:矩阵X的秩,仅在X为密集矩阵时有效
输出:矩阵X的秩
singular_
释义:矩阵X的奇异值,仅在X为密集矩阵时有效
输出:array of shape (min(X, y),)
intercept_
释义:截距,线性模型中的独立项
输出:如果fit_intercept = False,则intercept_为0.0
Methods
fit(self, X, y[, sample_weight])
训练模型,,sample_weight为每个样本权重值,默认None
get_params(self[, deep])
deep默认为True,返回一个字典,键为参数名,值为估计器参数值
predict(self, X)
模型预测,返回预测值
score(self, X, y[, sample_weight])
模型评估,返回R^2系数,最优值为1,说明所有数据都预测正确
set_params(self, **params)
设置估计器的参数,可以修改参数重新训练
本文由博客一文多发平台 OpenWrite 发布!
审核编辑:符乾江
-
机器学习
+关注
关注
66文章
8418浏览量
132652 -
深度学习
+关注
关注
73文章
5503浏览量
121172
发布评论请先 登录
相关推荐
芯盾时代入选《API安全技术应用指南(2024版)》API安全十大代表性厂商
IP风险画像详细接入规范、API参数(Ipdatacloud)

api驱动的云服务是什么意思?
使用OpenVINO Model Server在哪吒开发板上部署模型
API :软件程序间沟通的桥梁
请问Scene Server Model的state值应该怎样设置?
华为云发布 CodeArts API,为 API 护航

OpenAI API Key获取与充值教程:助开发者解锁GPT-4.0 API
API安全风险显现,F5助API实现可信访问
特斯拉Model 3用了哪些芯片?
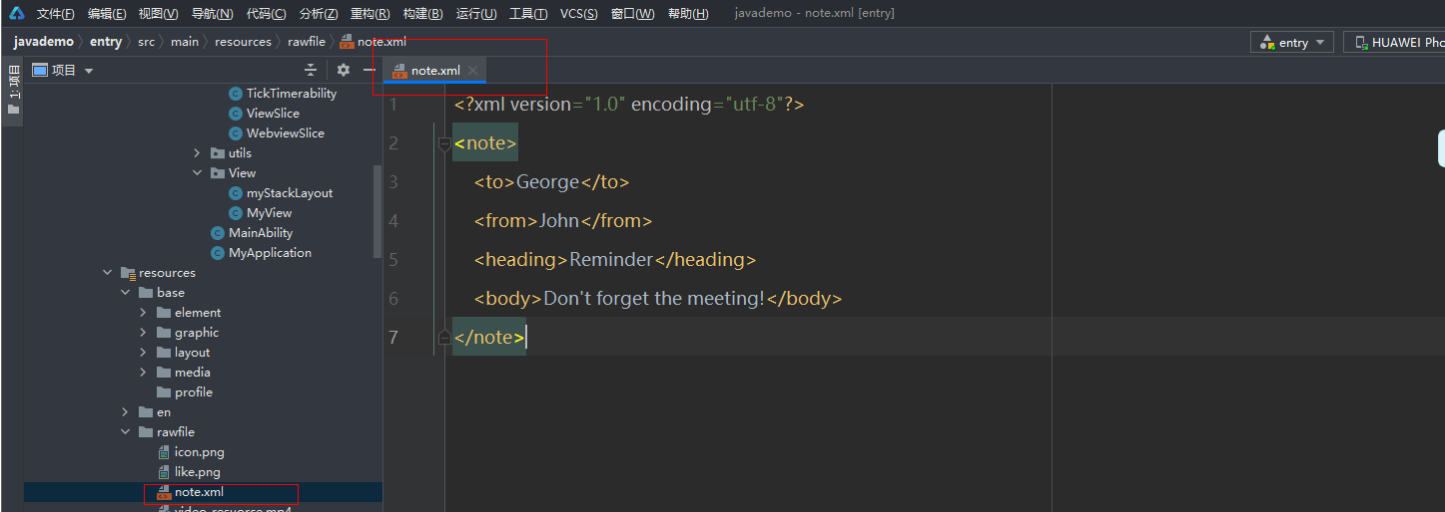
【JAVA UI】【HarmonyOS】【Demo】 鸿蒙如何进行 xml 解析
Kubernetes Gateway API攻略教程





 工商网监
工商网监
评论