 爱奇艺深度学习平台对TF Serving毛刺问题的优化
爱奇艺深度学习平台对TF Serving毛刺问题的优化
在点击率 CTR(Click Through Rate)预估算法的推荐场景中使用 TensorFlow Serving 热更新较大模型时会出现短暂的延时毛刺,导致业务侧超时,降低算法效果,为了解决这个问题,爱奇艺深度学习平台团队经过多个阶段的优化实践,最后对 TF Serving 和 TensorFlow 的源码进行深入优化,将模型热更新时的毛刺现象解决,本文将分享 TensorFlow Serving 的优化细节,希望对大家有帮助。
背景介绍
TensorFlow Serving是谷歌开源的用来部署机器学习模型的高性能推理系统。它主要具备如下特点:
同时支持 gRPC 和 HTTP 接口
支持多模型,多版本
支持模型热更新和版本切换
TensorFlow Serving
https://github.com/tensorflow/serving
爱奇艺深度学习平台上大量的 CTR 推荐类业务使用 TensorFlow Serving 来部署线上推理服务。
CTR 类业务对线上服务的可持续性要求很高,如果模型升级时要中断服务是不可接受的,因此 TF Serving 的模型热更新功能对这样的业务场景提供了很大的帮助,可以避免重启容器来做模型升级。
但是,随着业务对模型更新实时性的要求越来越高,我们发现,模型热更新时出现的短暂客户端请求超时现象(称之为毛刺现象)变成进一步提升实时性的一个比较大的障碍。
模型更新时的毛刺现象
先来看一下,
什么是模型更新时的毛刺现象?
下面这张图是我们在 TF Serving 代码中增加了 Bvar(https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md) 来查看内部请求的延迟情况。图中是延迟的分位比,延迟分位值分别为 [p80, p90, p99, p999],单位是微秒。
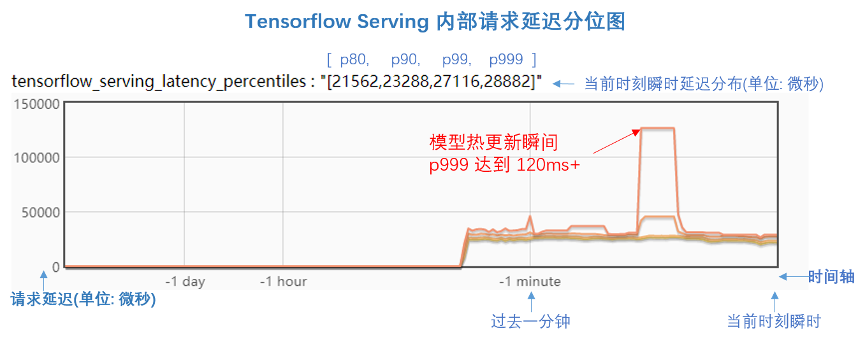
从图中可以看到,在模型更新前后,p999的延迟都在 30ms以下。但是,在模型更新的瞬间,p999延迟突然抖动到 120ms+,持续了大概 10 秒时间,这就是毛刺现象,反应到客户端就是会产生请求超时失败。
为了完全解决这个问题,爱奇艺深度学习平台经过多个阶段的深入优化,最后将模型更新时的毛刺现象解决。
TF Serving 的模型更新过程
工欲善其事必先利其器,我们先来看看 TF Serving 内部的模型更新过程。
如上图,Source会启动一个线程来不断查看模型文件,然后将发现的新模型构建相应的 Servable 数据结构放到 Aspired Versions 的队列中去。
DynamicManager也会启动一个线程,来不断查看 Aspired Versions队列是否有需要处理的请求,根据配置的 Version Policy 来执行模型更新策略,最后通过 SessionBundle来执行模型的加载和卸载。
Version Policy 默认为 AvailabilityPreservingPolicy,该 policy 的特点是当有新的模型加入时,会保证至少有一个可服务的模型版本,当新版本加载完成后,再卸载旧版本,这样可以最大程度的保证模型的可服务性。
举例子来讲,如果只支持一个模型版本,当前版本是 2,如果有新的版本 3 加入,那么会先加载版本 3,然后再卸载版本 2。
接下来,详细看一下 TF Serving 的模型加载过程,主要分成以下几个步骤:
创建一个 DirectSession
将模型的 Graph 加载到 Session 中
执行 Graph 中的 Restore Op 来将变量从模型中读取到内存
执行 Graph 中的 Init Op 做相关的模型初始化
如果配置了 Warmup,执行 Warmup 操作,通过定义好的样本来预热模型
TensorFlow 的模型执行有个非常显著的特点是 lazy initialization,也就是如果没有 Warmup,当 TF Serving 加载完模型,其实只是加载了 Graph 和变量,Graph 中的 OP 其实并没有做初始化,只有当客户端第一次发请求过来时,才会开始初始化 OP。
问题的初步优化
从上面的分析来看,可以看到初步的解决方案,那就是做模型的 Warmup,具体方案如下:
配置模型 Warmup,在模型目录中增加 tf_serving_warmup_requests 文件
使用独立线程来做模型的加载和卸载操作,配置 num_unload_threads和 num_load_threads
模型如何做 Warmup 详细请参考 TF 的文档 SavedModel Warmup。
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
第二项优化主要是参考美团的文章基于 TensorFlow Serving 的深度学习在线预估。
https://tech.meituan.com/2018/10/11/tfserving-improve.html
我们来对比一下优化前后的区别:
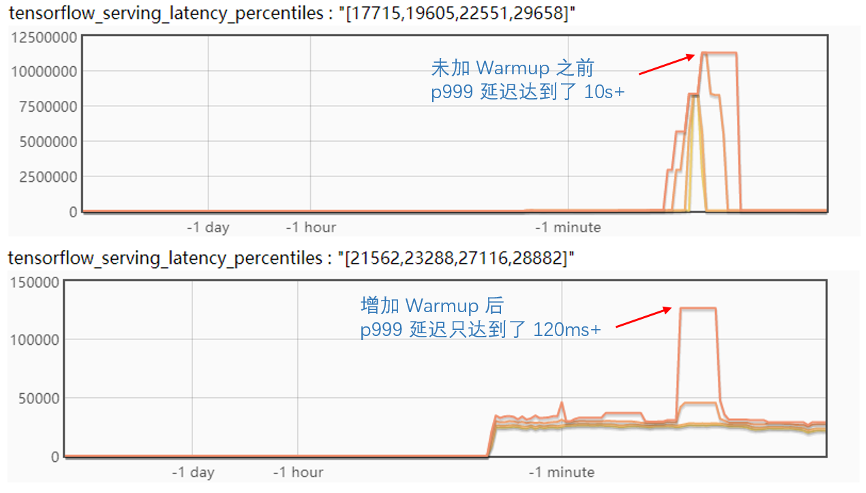
可以看到,使用上面的优化,抖动的延迟减少了几个数量级,效果很明显。
问题的进一步优化
虽然上面的优化将模型更新时的毛刺降低到只有 120ms+,但是这个仍然会对客户端的请求产生超时现象,如果模型更新的频率不高,比如一天更新一次,那么基本上是可以接受的。
但是,如果业务对模型更新的实时性到一个小时以内,甚至更高,那么就必须进一步解决毛刺问题。我们不得不继续思考,剩下的这个毛刺是由于什么原因产生的?
TF Serving 是一个计算密集型的服务,对可能产生影响的因素,我们做了如下猜测:
计算原因:是不是新模型的初始化,包括 Warmup 的计算,影响了推理请求?
内存原因:是不是模型更新过程中的内存分配或释放产生锁而导致的?
或者两者都有?
计算原因分析
先来分析一下计算方面的原因,如果模型加载会影响到推理请求,那么能不能将模型的加载也用独立的线程来做?
经过调研 TF Serving 的源码,我们发现了这样的参数,原来 TF 已经考虑到这样的因素。
// If set, session run calls use a separate threadpool for restore and init // ops as part of loading the session-bundle. The value of this field should // correspond to the index of the tensorflow::ThreadPoolOptionProto defined as // part of session_config.session_inter_op_thread_pool. google.protobuf.Int32Value session_run_load_threadpool_index = 4;
通过配置 session_inter_op_thread_pool并设置 session_run_load_threadpool_index可以将模型的初始化放在独立的线程。
修改配置后,并做了相关验证,如下图。
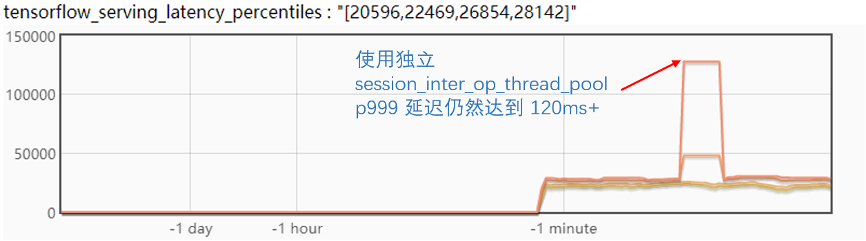
验证的结论很遗憾,使用独立的线程来处理模型初始化并不能缓解毛刺问题。
从而,进一步分析了 TF Serving 的线程机制,发现计算部分主要集中在 TF 的 Inter 和 Intra Op 线程,在模型初始化线程独立出来后,原来的推理请求基本不会被影响到。
另外,经过分析还发现,TF 在执行 Restore Op 的时候会创建额外的线程池来恢复大的变量,于是尝试将 Restore 时的线程池去掉,发现仍然没有效果。
内存原因分析
先来看一下 TF 内存的分配机制,TF 的 GPU 显存是通过 BFC (best-fit with coalescing) 算法来分配的,CPU 内存分配是直接调用底层 glibc ptmalloc2 的 memory allocation。
目前平台上 CTR 类业务基本都是 CPU 推理,因此内存的分配和释放都是通过 glibc ptmalloc2 来管理的。
经过调研了解到,Linux glibc 的内存管理也是经过优化的,原来的实现是 dlmalloc,对多线程的支持并不好,现在的 ptmalloc2 是优化后支持了多线程。
如果要深入到 ptmalloc2 优化内存管理就比较麻烦,不过调研发现已经有了开源的优化方案,那就是谷歌的 Tcmalloc和 Facebook 的 Jemalloc。
Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html)
Jemalloc
http://jemalloc.net/
Ptmalloc,Tcmalloc 和 Jemalloc 的优缺点网上有很多分析的文章,都指出 Tcmalloc 和 Jemalloc 在多线程环境下有比较好的性能,大体从原理上来讲是区分大小内存块的分配,各个线程有自己内存分配区域,减少锁竞争。
对比试验了三个内存分配器,实验结果如下图:
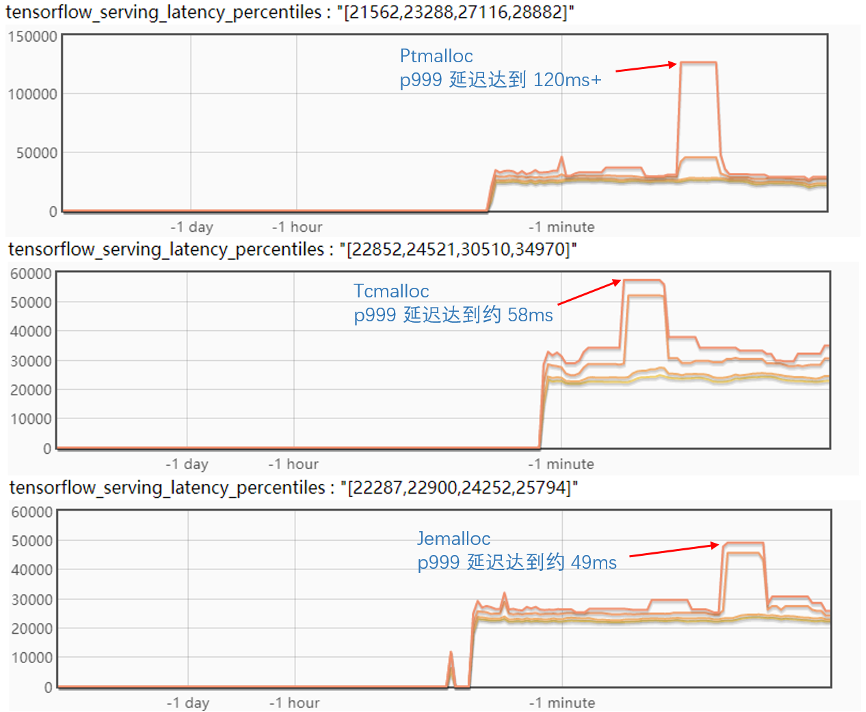
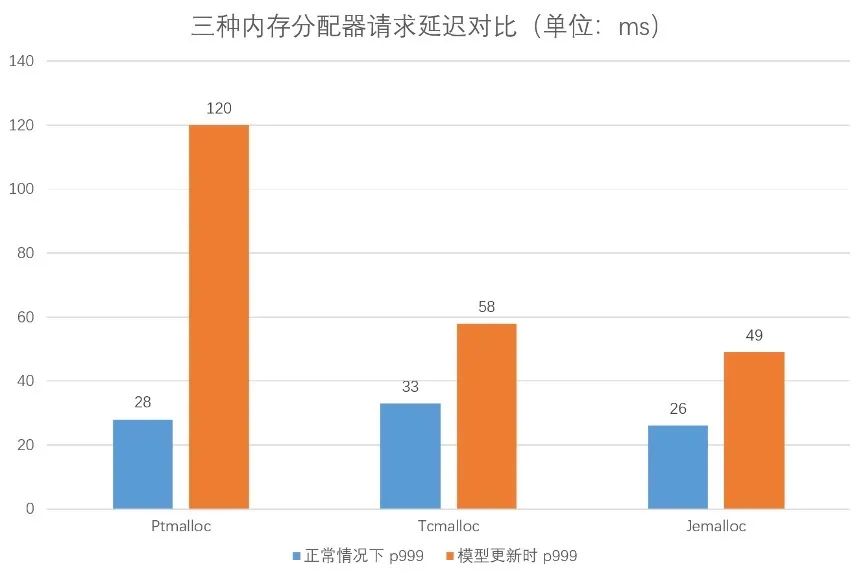
从实验结果来看,Tcmalloc 和 Jemalloc 对毛刺都有比较好的缓解,但是 Tcmalloc 会增加正常情况下的 p999 延迟;而反观 Jemalloc 的毛刺 p999 降到了 50ms 以下,正常情况下的 p999 比 Ptmalloc也有所优化。
看起来 Jemalloc 是一个相对比较理想的方案,不过在进一步的试验中发现,如果同时更新两个版本,Jemalloc 的 p999 毛刺会达到近 60ms,并且更新后会有一个比较长的延迟抖动期,会持续近一分钟时间,如下图:
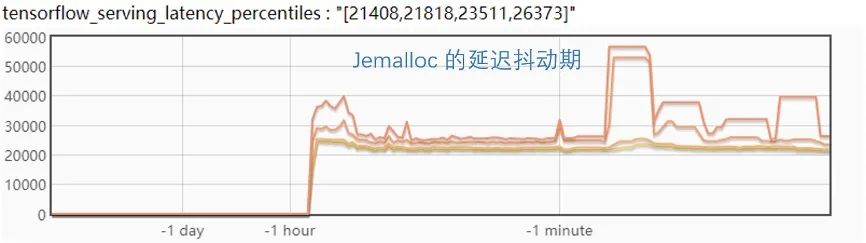
优化到这一步,如果对这样的延迟变化不敏感的话,基本就可以用 Jemalloc 来做为方案上线了,但对这样的效果仍觉得不是非常理想,因此进行了更深入的优化。
问题的最终深入优化
上面内存方案的优化效果提供了一个很好的启示和方向,毛刺的根本原因应该在内存的分配和释放竞争上,所以来进一步分析 TF 的内存分配。
TF 内存分配和释放的使用场景主要分成两个部分:
一部分是模型 Restore 时变量本身 Tensor 的分配,这个是在加载模型时分配的,内存的释放是在模型被卸载的时候
一部分是 RPC 请求时网络前向计算时的中间输出Tensor 内存分配,在请求处理结束后就被释放
模型更新时,新模型加载时的 Restore OP 有大量的内存被分配,旧模型被卸载时的有很多对象被析构,大量内存被释放。
而这个过程中,RPC 请求没有中断,这个时候两者的内存分配和释放会产生冲突和竞争关系。
因此设计了内存分配隔离方案:
将模型本身参数的内存分配和 RPC 请求过程中的内存分配隔离开来,让它们的分配和释放在不同的内存空间。
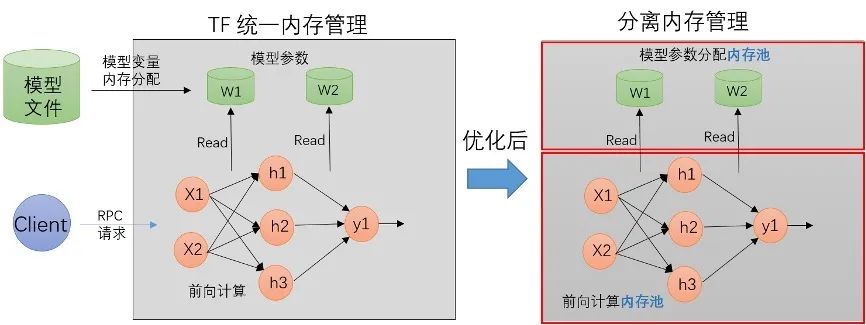
结合模型的更新,线上模型一个容器里面最多就两个版本的模型文件,给每个模型版本各自分配了独立的内存池,用来做 AB 切换。
在代码的编写上,TF 刚好有一个现成的 BFC 内存分配器,利用 BFC 做模型参数的内存分配器,RPC 请求的内存分配仍然使用 glibc ptmalloc2 来统一分配,因此最后的设计是这样:
代码改动主要在 TF 的源码,主要是对 ProcessState,ThreadPoolDevice和 Allocator做了一些改动。
最后来看一下试验效果:
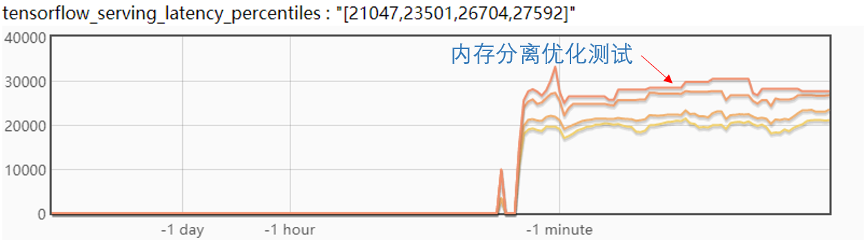
从图中,可以看到模型更新后,延迟抖动很少,大约在 2ms,在实际的线上测试高峰期大概有 5ms 的抖动,满足业务需求。
总结
本文介绍了爱奇艺深度学习平台对 TF Serving 毛刺问题的优化,主要归纳如下:
配置模型 Warmup 文件来初预热模型
使用 Jemalloc 做内存分配优化
TF 模型参数分配和 RPC 请求内存分配分离
经过实践,每个方法都有进一步的优化,最后基本解决了模型热更新过程中的毛刺问题。
— 参考文献 —
1. TF ServingAarchtecture
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/architecture.md
2. BVar
https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md
3. TF WarmUp
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
4. 美团基于 TensorFlow Serving 的深度学习在线预估
https://tech.meituan.com/2018/10/11/tfserving-improve.html
5. Google Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html
6. Facebook Jemalloc: http://jemalloc.net/
责任编辑:xj
原文标题:社区分享 | TensorFlow Serving 模型更新毛刺的完全优化实践
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
-
毛刺
+关注
关注
0文章
29浏览量
15664 -
深度学习
+关注
关注
73文章
5503浏览量
121172 -
tensorflow
+关注
关注
13文章
329浏览量
60536
原文标题:社区分享 | TensorFlow Serving 模型更新毛刺的完全优化实践
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU在深度学习中的应用
深度学习模型的鲁棒性优化
AI大模型与深度学习的关系
FPGA做深度学习能走多远?
深度学习算法在嵌入式平台上的部署
深度学习中的时间序列分类方法
深度学习与nlp的区别在哪
深度学习中的模型权重
深度学习模型训练过程详解
深度学习的模型优化与调试方法
深度解析深度学习下的语义SLAM

燧原科技与爱奇艺共同探索生成式AI在泛娱乐行业的技术变革
为什么深度学习的效果更好?






 工商网监
工商网监
评论