 如何通过FPGA和软件开发工具包(SDK)创建边缘AI应用
如何通过FPGA和软件开发工具包(SDK)创建边缘AI应用
边缘推理处理器实现人工智能(AI)算法的设计人员不断需要降低功耗和开发时间,即使处理需求不断增加。现场可编程门阵列(FPGA)提供了速度和功率效率的有效组合,用于实现边缘AI所需的神经网络(NN)推理引擎。但是,对于不熟悉FPGA的开发人员,常规的FPGA开发方法似乎很复杂,通常会导致开发人员转向不太理想的解决方案。
本文介绍了Microchip Technology的一种简单方法,该方法使开发人员可以绕过传统的FPGA开发,使用FPGA和软件开发工具包(SDK)创建经过训练的NN,或者使用基于FPGA的视频工具包执行智能嵌入式视觉应用程序开发。
为什么要在边缘使用AI?
边缘计算为工业自动化,安全系统,智能家居等各个领域的物联网(IoT)应用程序带来了许多好处。在针对工厂的工业物联网(IIoT)应用程序中,边缘计算可消除对基于云应用程序的往返延迟,从而改善过程控制回路中的响应时间。同样,即使意外或有意断开与云的连接,基于边缘的安全系统或智能家庭门锁也可以继续运行。在许多情况下,在任何这些应用程序中使用边缘计算都可以通过减少产品对云资源的依赖来帮助降低总运营成本。随着产品需求的增加,开发人员不必面对额外的昂贵云资源的意外需求,而是可以依靠产品内置的本地处理功能来帮助维持更稳定的运营支出。
机器学习(ML)推理模型的快速接受和需求的增加极大地增强了边缘计算的重要性。对于开发人员,推理模型的本地处理有助于减少响应延迟和基于云的推理所需的云资源成本。对于用户而言,使用本地推理模型可以增强信心,即使偶尔出现网络连接中断或产品供应商基于云的产品发生变化,其产品仍将继续运行。此外,对安全性和隐私的关注会进一步推动对本地处理和推理的需求,以限制通过公共Internet传输到云的敏感信息的数量。
开发用于基于视觉的对象检测的NN推理模型是一个多步骤过程,从模型训练开始,通常使用公开可用的标记图像或自定义标记图像在ML框架(例如TensorFlow)上执行。由于处理需求,通常使用云或其他高性能计算平台中的图形处理单元(GPU)进行模型训练。在完成训练之后,该模型将转换为能够在边缘或雾计算资源上运行的推理模型,并将推理结果作为一组对象类概率提供(图1)。
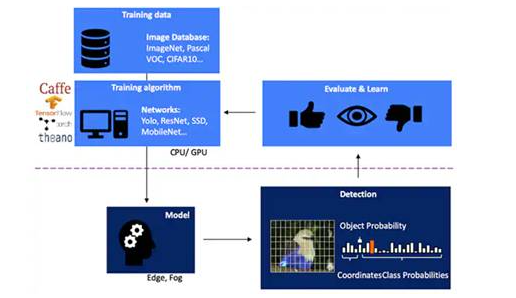
图1:为边缘AI实现推理模型位于多步骤过程的结尾,该过程需要使用可用或自定义训练数据在框架上对NN进行训练和优化。(图片来源:Microchip Technology)
为什么推理模型在计算上具有挑战性
尽管与训练过程中使用的模型相比,其大小和复杂度有所降低,但由于需要大量计算,因此NN推理模型仍然对通用处理器提出了计算难题。在其通用形式中,深度NN模型包括多层神经元集合。在完全连接的网络的每一层中,每个神经元都需要计算每个输入的乘积和相关的权重(图2)。
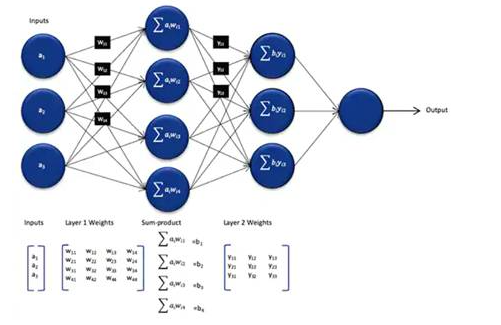
图2:使用NN进行推理所需的计算数量可能会导致大量的计算工作。 (图片来源:Microchip Technology)
图2中未显示激活函数所施加的额外计算要求,该函数通过将负值映射为零,将值映射为大于1到1以及类似的函数来修改每个神经元的输出。每个神经元nij的激活函数的输出用作下一层i + 1的输入,以这种方式在每一层继续。最终,NN模型的输出层生成一个输出向量,该输出向量表示原始输入向量(或矩阵)对应于在监督学习过程中使用的类(或标签)之一的概率。
有效的NN模型是使用比典型的通用NN拱形更大,更复杂的架构构建的。例如,用于图像对象检测的典型卷积神经网络(CNN)以分段方式应用这些原理,跨输入图像的宽度,高度和颜色深度进行扫描,以生成一系列特征图,最终生成输出预测矢量(图3)。
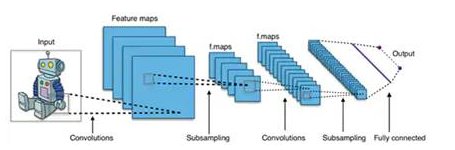
图3:用于图像对象检测的CNN涉及许多层的大量神经元,对计算平台提出了更高的要求。 (图片来源:Aphex34 CC BY-SA 4.0)
使用FPGA加速NN
尽管在边缘执行推理模型的方法不断涌现,但几乎没有其他选择可以提供在边缘进行实际高速推理所需的灵活性、性能和能效的最佳组合。在边缘AI的现有替代方案中,FPGA尤其有效,因为它们可以提供基于硬件的高性能计算密集型操作,而消耗的功率却相对较小。
尽管具有优势,但由于传统的开发流程有时会绕开FPGA,而对于那些没有丰富的FPGA经验的开发人员来说,这可能令人望而生畏。为了创建由NN框架生成的NN模型的有效FPGA实现,开发人员需要了解将模型转换为寄存器传输语言(RTL),综合设计以及完成最终布局和布线物理设计的细微差别阶段以产生优化的实现(图4)。
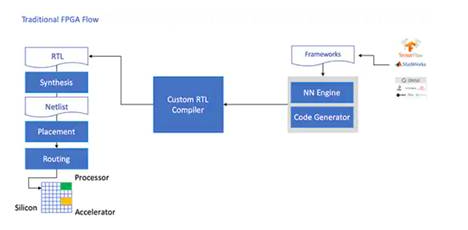
图4:要在FPGA上实现NN模型,到目前为止,开发人员需要了解如何将其模型转换为RTL并通过传统的FPGA流程进行工作。 (图片来源:Microchip Technology)
凭借其PolarFire FPGA,专用软件和相关的知识产权(IP),Microchip Technology提供了一种解决方案,可以在没有FPGA经验的情况下广泛地为开发人员提供高性能,低功耗的推理。
PolarFire FPGA采用先进的非易失性处理技术制造,旨在最大程度地提高灵活性和性能,同时将功耗降至最低。除了用于通信和输入/输出(I / O)的大量高速接口外,它们还具有能够使用软IP内核支持高级功能的深度FPGA结构,包括RISC-V处理器,高级存储控制器和其他功能。标准接口子系统(图5)。
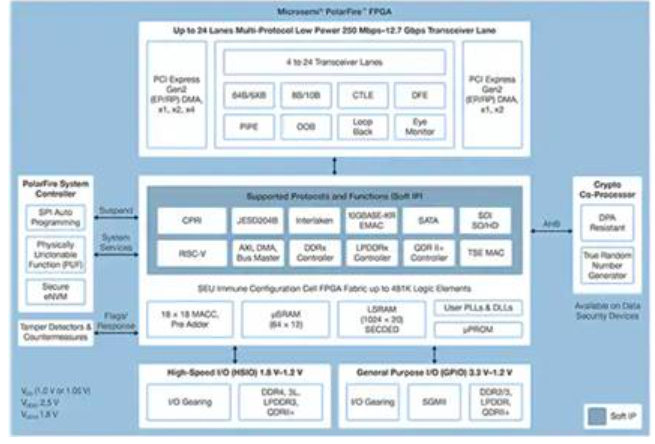
图5:Microchip Technology PolarFire架构提供了一种深层结构,旨在支持高性能设计要求,包括计算密集型推理模型的实现。 (图片来源:Microchip Technology)
PolarFire FPGA架构提供了广泛的逻辑元素和专用模块集,由PolarFire FPGA系列的不同成员(包括MPF100T,MPF200T,MPF300T和MPF500T系列)以各种容量支持(表1)。
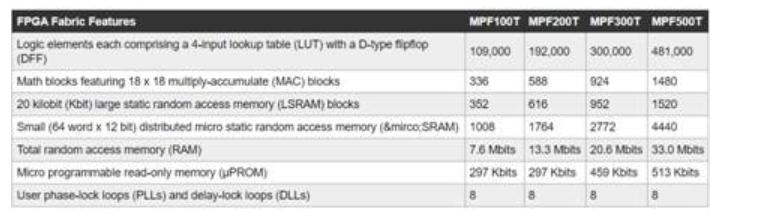
表1:PolarFire系列提供了多种FPGA架构功能和容量。 (表来源:Digi-Key,基于Microchip Technology PolarFire数据表)
在推理加速令人关注的功能中,PolarFire架构包括一个专用的数学模块,该模块提供了带有预加器的18位×18位带符号乘法累加函数(MAC)。内置点积模式使用单个数学块执行两个8位乘法运算,从而提供了一种机制,可以利用模型量化对精度的影响可以忽略不计。
除了加速数学运算之外,PolarFire架构还有助于缓解在通用架构上实现推理模型时遇到的内存拥塞,例如用于存储在NN算法执行期间创建的中间结果的小型分布式内存。此外,NN模型的权重和偏差值可以存储在16位深度乘18位系数的只读存储器(ROM)中,该存储器由位于数学块附近的逻辑元素构建而成。
结合其他PolarFire FPGA架构功能,数学模块为Microchip Techno提供了基础的更高级别的CoreVectorBlox IP。这是一个灵活的NN引擎,能够执行不同类型的NN。连同一组控制寄存器,CoreVectorBlox IP包括三个主要功能块:
单片机:一个简单的RISC-V软处理器,可从外部存储读取Microchip固件二进制大对象(BLOB)和用户特定的NN BLOB文件。它通过执行BLOB固件中的指令来控制整个CoreVectorBlox操作。
矩阵处理器(MXP):一种软处理器,包括八个32位算术逻辑单元(ALU),设计为使用元素张量运算对数据矢量执行并行运算,包括加,减,异或,移位,mul,dotprod等,根据需要使用8位,16位和32位混合精度。
CNN加速器:使用二维数组的MAC函数加速MXP的操作,这些MAC函数使用数学块实现,并以8位精度运行。
完整的NN处理系统将结合CoreVectorBlox IP块,内存,内存控制器和主机处理器,例如Microsoft RISC-V(Mi-V)软件处理器内核(图6)。
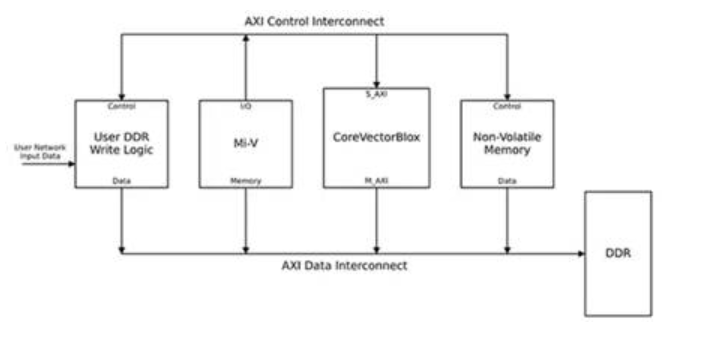
图6:CoreVectorBlox IP模块与诸如Microchip的Mi-V RISC-V微控制器之类的主机处理器配合使用,以实现NN推理模型。 (图片来源:Microchip Technology)
在视频系统实现中,主机处理器将从系统闪存中加载固件和网络BLOB,并将它们复制到DDR RAM中,以供CoreVectorBlox块使用。当视频帧到达时,主处理器将它们写入DDR RAM,并向CoreVectorBlox块发送信号以开始处理图像。在运行BLOB网络中定义的推理模型后,CoreVectorBlox块将包括图像分类在内的结果写回到DDR RAM中,以供目标应用程序使用。
开发流程简化了NN FPGA的实现
Microchip使开发人员免于在PolarFire FPGA上实现NN推理模型的复杂性。NN模型开发人员无需像传统的FPGA流程那样处理细节,而是照常使用其NN框架,并将结果模型加载到Microchip Technology的VectorBlox加速器软件开发套件(SDK)中。 SDK生成所需的文件集,包括正常FPGA开发流程所需的文件集以及前面提到的固件和网络BLOB文件(图7)。
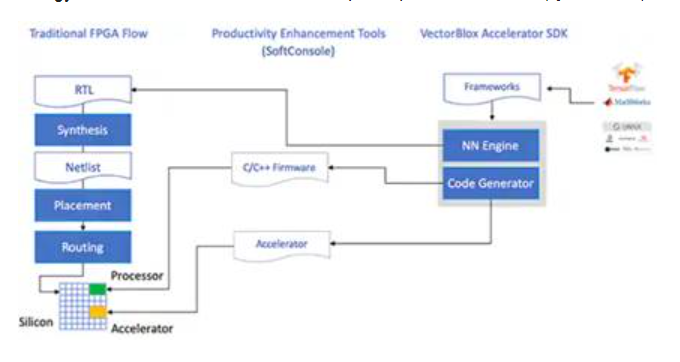
图7:VectorBlox Accelerator SDK管理在FPGA上实现NN模型的细节,自动生成设计和运行基于FPGA的推理模型所需的文件。 (图片来源:Microchip Technology)
由于VectorBlox Accelerator SDK流程将NN设计覆盖在FPGA中实现的NN引擎,因此不同的NN可以在同一FPGA设计上运行,而无需重做FPGA设计综合流程。开发人员可以为生成的系统创建C / C ++代码,并能够使用时间切片在系统中即时切换模型或同时运行模型。
VectorBlox Accelerator SDK融合了Microchip Technology Free FPGA设计套件,并具有用于NN推理模型开发的全面功能。除了模型优化,量化和校准服务外,SDK还提供了一个NN仿真器,使开发人员可以在将其用于FPGA硬件实现之前,使用相同的BLOB文件评估其模型(图8)。
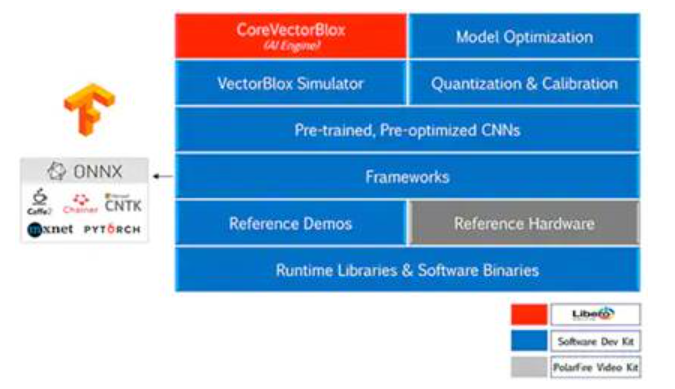
图8:VectorBlox Accelerator SDK提供了一整套服务,旨在优化框架生成的推理模型的FPGA实现。 (图片来源:Microchip Technology)
VectorBlox Accelerator SDK支持开放神经网络交换(ONNX)格式的模型,以及来自多个框架的模型,包括TensorFlow,Caffe,Chainer,PyTorch和MXNET。受支持的CNN架构包括MNIST,MobileNet版本,ResNet-50,Tiny Yolo V2和Tiny Yolo V3。 Microchip正在努力扩展支持,以将大多数网络纳入预训练模型的开源OpenVINO工具包以及open model zoo中,包括Yolo V3,Yolo V4,RetinaNet和SSD-MobileNet等。
视频套件演示了FPGA推理
为了帮助开发人员快速进入智能嵌入式视觉应用开发,Microchip Technology提供了一个全面的示例应用,旨在在该公司的MPF300-VIDEO-KIT PolarFire FPGA视频和成像套件以及参考设计上运行。
该套件的电路板基于Microchip MPF300T PolarFire FPGA,结合了双摄像头传感器,DDR4 RAM,闪存,电源管理和各种接口(图9)。
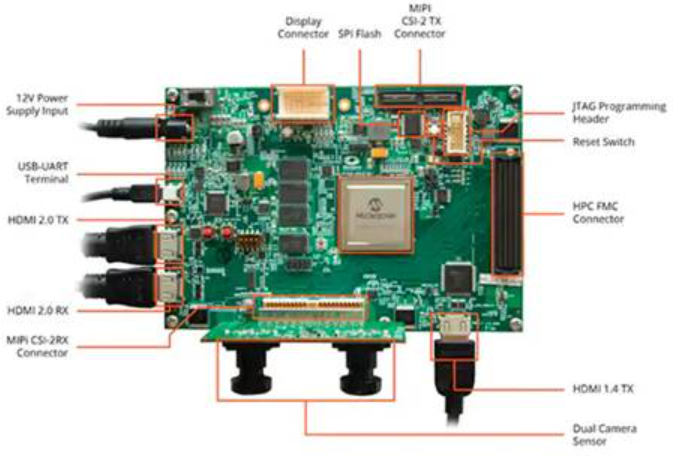
图9:MPF300-VIDEO-KIT PolarFire FPGA视频、图像套件和相关软件为开发人员提供了快速入门,帮助他们在智能嵌入式视觉应用中进行基于FPGA的推理。 (图片来源:Microchip Technology)
该套件随附一个完整的Libero设计项目,用于生成固件和网络BLOB文件。将BLOB文件编程到板载闪存中后,开发人员单击Libero中的运行按钮开始演示,该演示处理来自摄像头传感器的视频图像并在显示屏上显示推断结果(图10)。
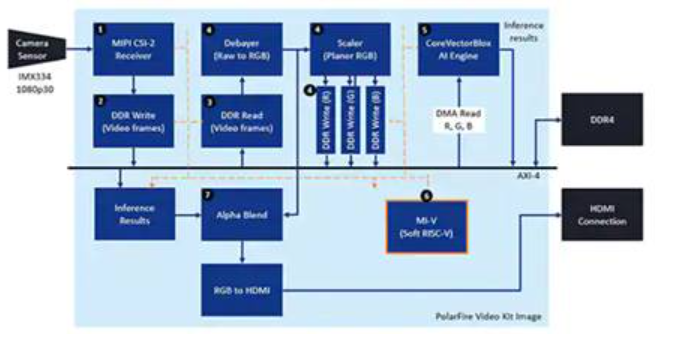
图10:Microchip Technology PolarFire FPGA视频和成像套件演示了如何设计和使用基于Microchip CoreVectorBlox NN引擎构建的智能嵌入式视觉系统的FPGA实现。 (图片来源:Microchip Technology)
对于每个输入视频帧,基于FPGA的系统执行以下步骤(步骤编号与图10相关):
1、从相机加载框架
2、将帧存储在RAM中
3、从RAM读取帧
4、将原始图像转换为RGB,平面RGB,并将结果存储在RAM中
5、Mi-V软核RISC-V处理器启动CoreVectorBlox引擎,该引擎从RAM检索图像,执行推理,并将分类概率结果存储回RAM
6、Mi-V使用结果创建带有边框,分类结果和其他元数据的覆盖框架,并将该框架存储在RAM中
7、原始帧与覆盖帧融合并写入HDMI显示屏
该演示支持Tiny Yolo V3和MobileNet V2模型的加速,但是开发人员可以使用前面描述的方法运行其他SDK支持的模型,只需稍作更改即可将模型名称和元数据添加到包含两个默认模型的现有列表中。
结论
诸如NN模型之类的AI算法通常会施加计算密集型工作负载,这些工作负载需要比通用处理器更强大的计算资源。尽管FPGA具备足够的能力来满足推理模型执行的性能和低功耗要求,但传统的FPGA开发方法似乎很复杂,常常使开发人员转向次优解决方案。
如图所示,使用Microchip Technology的专用IP和软件,没有FPGA经验的开发人员也可以实施基于推理的设计,从而更好地满足性能,功耗和设计进度要求。
编辑:hfy
-
FPGA
+关注
关注
1631文章
21806浏览量
606703 -
神经网络
+关注
关注
42文章
4785浏览量
101279 -
人工智能
+关注
关注
1797文章
47867浏览量
240854
发布评论请先 登录
相关推荐
功能更强 高通发布Snapdragon S4 8960 SDK(软件开发工具包)
联发科技发布两款Apple HomeKit软件开发工具包
c++对于ARM软件开发工具包用户及参考指引
ARM软件开发工具包2.50版参考指南
谷歌发布针对Android2.2操作系统的软件开发工具包Fr
Rethink Robotics推出Sawyer智能协作机器人软件开发工具包
三星为区块链Keystore软件开发工具包SDK添加了BTC支持
Unify SDK软件开发工具包可以提供什么好处
Emulex软件开发工具包实用程序(elxsdkutil)






 工商网监
工商网监
评论