 自动跨主题作文属性评分研究
自动跨主题作文属性评分研究

01
—
研究动机
自动作文评分(英文叫Automated Essay Scoring,简称AES)旨在使用计算机来根据论文的整体质量或与某些属性(trait)相关的质量来评分,例如,文章组织、切题程度、叙述性等。现有的大多数研究都是针对同一主题的已评分作文数据集上进行模型的训练和预测(如图1左上角和左下角),其中训练和测试数据都是从同一分布中(DA)提取的。
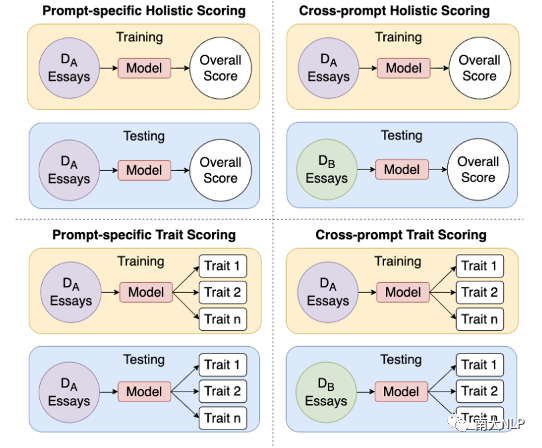
图1: AES任务概览
然而真实场景中的AES系统通常无法获得足够多的目标主题文章,因此有必要研究如何预测训练数据中不存在的主题的文章分数。因此,最近的一些研究探索了跨主题的AES,即从不同的主题中提取训练数据和测试数据(图1的右上角)。跨主题的AES研究目前只关注根据论文的整体性来评分,而我们认为一个有效的AES系统还应该能够提供属性级别的反馈,因此,我们引入了一个新的AES任务,即自动跨主题作文属性评分,该任务要求模型在仅有非目标主题作文进行训练的前提下,能够准确预测属于目标主题的文章的总分以及多个属性的分数(如图1右下角),其中训练和测试数据来自不同的分布,输出是不同属性的分数。
这项新的任务表现出两个主要的挑战:
第一,模型需要有足够的泛化能力,才能在新的主题中表现良好;
第二,模型需要能够从不同的方面表示文章质量,以便有效地对各种文章属性进行评分。
在探讨自动跨主题作文属性评分的任务中,我们解决了两个问题:
第一,属于不同题目的文章有不同的trait集,因此许多trait有部分覆盖率(论文中叫partial-trait coverage),这会导致某些trait的训练数据不足。例如,如果只有两个题目的文章在叙述性trait上有分数(所有其他题目的文章没有),那一个被训练为这一trait打分的模型只能在这两个题目的文章上进行训练;
第二,不同trait之间存在高度的相关性。例如,一个在word choice的trait上分数高的文章也可以预期在conventions上获得很好的分数。
为了解决partial-trait coverage的问题,我们引入了一种多任务的方法,即Cross-prompt Trait Scorer(CTS),该方法同时预测总体分数和所有trait的分数。这使得模型能够对训练集中的所有数据进行训练,以学习更鲁棒的表示。为了解决trait间关系的问题,我们设计了一个trait-attention机制,利用最相关的trait信息来预测每个trait的分数。
02
—
贡献
1.我们提出了一个新的任务,即自动主题作文属性评分,它将AES解决方案中的两个重要任务(跨主题作文评分和作文属性评分)结合起来,从而更贴近真实场景。
2.我们设计了一个新的方法叫Cross-prompt Trait Scorer(CTS),通过使用多任务方法来解决由于partial-trait coverage而导致训练数据受限的问题。
3.我们设计了一个trait-attention机制来利用不同trait之间存在的关系。
03
—
解决方案
我们的方法建立在PAES(Ridley et al. 2020,如图2左)之上,PAES是一个跨主题AES的SOTA方法。该方法利用词性嵌入来学习广义句法表示。首先,每个句子都有一个卷积层,通过attention pooling来实现句子级的表示。然后,这些表示被输入一个recurrent层,该层使用LSTM,然后是第二个attention pooling层来学习完整的文章表示。然后将一组非主题特定的特征与文章表示链接起来,最后通过一个线性层和sigmoid激活来预测单个分数。
这类方法通过独立地对每个trait进行训练,也可以直接应用于本文提出的新任务中,然而这样做有两个问题:首先,如果训练数据中只有少量的文章拥有目标trait的标签,那么就没有足够的数据来训练一个鲁棒的模型。其次,这些trait并不是相互独立的,而是相互关联的。这种简单的方法不利用任何隐含的trait间的关系。
为了解决上述问题,我们设计了一个名为Cross prompt Trait Scorer(CTS)的模型,如图2右所示。针对partial-trait coverage导致数据不足的问题,我们采用了基于多任务的体系结构,这使得模型能够对数据集中的所有样本进行训练,以便学习更鲁棒的编码器表示。为了解决trait间的关系问题,我们在模型的低级别实现共享层,然后在高级别实现私有层。共享层旨在学习对所有任务都有用的通用表示。在多任务结构中,高级别的层能够表示更复杂的信息,因此私有层被用来学习更多的任务特定表示。此外,为了更明确地共享trait之间的信息,我们设计了一个trait-attention机制,允许每个trait集中于其他trait的相关信息。
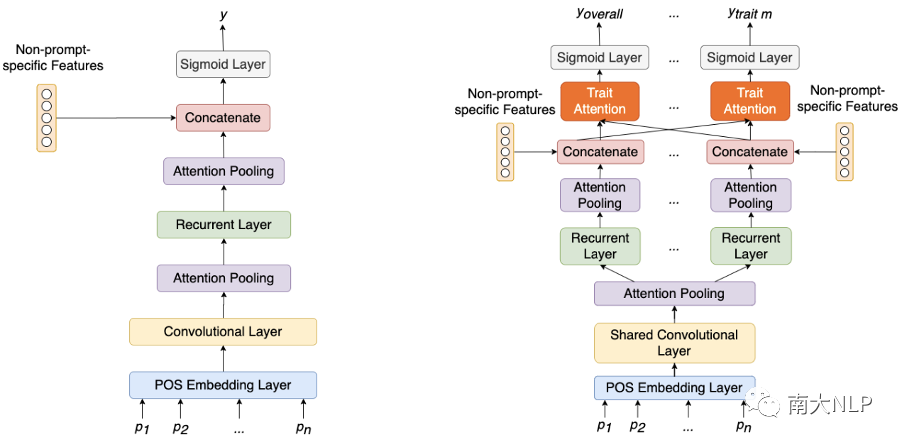
图2: PAES(左,Ridley et al. 2020)及本文给出的CTS模型(右)
04
—
实验
本文的实验是在Automated Student Assessment Prize(ASAP)数据集上进行的。ASAP数据集包含八个不同的文章集,每个集中的文章都有不同的题目。每一篇文章都会根据文章的整体质量获得一个人性化的评分,而文章集7和8的文章则会根据评分标准对一些相关trait进行额外评分。由于只有文章集7和8具有trait分数,因此我们还使用了ASAP++数据集,该数据集是在原始ASAP数据集的基础上构建的。ASAP++的作者为文章集1-6提供了各种相关trait的分数,以补充ASAP的原始总分。
表1: ASAP和ASAP++数据集中的属性定义
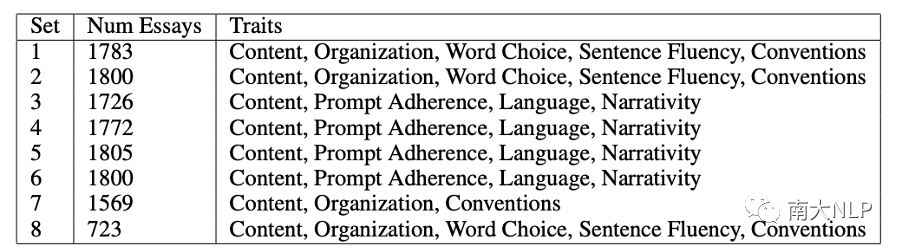
每个文章集的trait如表1所示,文章集1-6的trait分数来自补充的ASAP++数据集,文章集7和8的trait分数来自ASAP数据集。所有的总分都来自原始的ASAP数据集。
在实验中,一个文章集的作文被用作测试数据,其余几组的文章被用作训练数据。对于每个文章集重复此操作。在每种情况下,开发集包含与训练集相同集的文章。
我们将CTS与四个baseline模型进行了比较,Hi att和AES aug都是在Prompt-specific Holistic scoring和Prompt-specific Trait Scoring都取得了很好性能的模型,PAES是我们的base模型,是一个面向Cross-prompt Holistic Scoring的SOTA方法,最后,CTS no att是我们的CTS模型的一个消融版本,没有添加trait-attention机制。
表2:各文章集的平均QWK值

表3:各属性的平均QWK值

在表2中,我们显示了每个文章集的所有trait的平均分数,在表3中,我们显示了每个trait的所有文章集的平均分数。从这两个表来看,我们可以看出两个面向Prompt-specific的方法(Hi att 和AES aug)都表现不好。这是因为这些模型不是为Cross-prompt的设置设计的,因此它们过拟合很严重。
当我们比较三种面向Cross-prompt模型时,我们可以看到,除了文章集5外,CTS在所有文章集上的性能都超过了PAES和CTS no att,而且在大多数文章集中,多任务方法CTS no att的性能都优于单任务方法PAES。这是因为PAES无法利用完整的训练数据集,它只能在目标trait有标签的样本上进行训练。CTS no att和CTS的多任务结构能够利用训练集中的所有样本进行训练。
表4:文章集2中每个属性的平均QWK值

我们还通过实验来验证可用的训练数据的数量对模型性能的影响。表4中显示了PAES、CTS no att和CTS的文章集2的每个属性的性能。在这个表格中,有Word Choice和Sentence Fluency只出现在另外两个文章集中。因此,在对这两个属性进行评分时,基于单任务方法仅能对训练集9499篇论文中的2129篇进行训练,与其他两个模型相比,这两个trait的表现显著降低。
图3:预测文章集3的总分时所有属性的注意力权重
为了深入了解trait-attention机制的运作方式,我们将注意力权重可视化。在图3中,当预测文章集3的总分时,由于这是一个整体评分,应该从多个不同方面考虑文章的质量,因此我们可以看到注意力在所有属性中的分布相对均匀,基本没有权重明显高于其他属性的属性。
图4:预测文章集3的Language分数时的属性注意权重
图4则显示了在预测文章集3的Language分数时的trait注意权重。这是一个比总分更具体、更集中的属性,此时与语言密切相关的属性Word Choice的权重要明显高于其他属性权重。
05
—
总结
为了满足真实场景中AES系统的需求,我们引入了一个新的AES任务,即Automated Cross-prompt Scoring of Essay Traits。此外,我们还提出了一个新的方法(Cross-prompt Trait Scorer),它利用共享和私有层的多任务结构以及trait-attention机制来解决在跨主题设置中某些属性数据有限以及属性间关系利用的两个问题。
责任编辑:xj
原文标题:【AAAI2021】自动跨主题作文属性评分
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
机器学习
+关注
关注
67文章
8562浏览量
137209 -
深度学习
+关注
关注
73文章
5604浏览量
124617
原文标题:【AAAI2021】自动跨主题作文属性评分
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
巧用API接口,数据驱动提升店铺DSR评分

使用PYTHON进行的跨平台仿真

NVIDIA DRIVE AV软件平台与Halos架构助力梅赛德斯奔驰CLA车型获得最高安全评分
比亚迪ESG评分实现重大突破
华为郑晓龙受邀出席CNCC 2025并发表主题演讲
商品类目属性查询接口技术实现详解

手机板 layout 走线跨分割问题
国家级认证!拓维海云天“中文手写体作文图像识别评分生成算法”通过国家网信办备案

中国科学院自动化研究所携手中科曙光打造高性能工具链解决方案
喜报!科士达以实力超越期待:EcoVadis评分70分,远超客户目标!
连续四年!Splashtop 再度荣膺 TrustRadius 最高评分奖




评论