 哈工大讯飞联合实验室发布的中文ELECTRA系列预训练模型再迎新成员
哈工大讯飞联合实验室发布的中文ELECTRA系列预训练模型再迎新成员
哈工大讯飞联合实验室发布的中文ELECTRA系列预训练模型再迎新成员。我们基于大规模法律文本训练出中文法律领域ELECTRA系列模型,并且在法律领域自然语言处理任务中获得了显著性能提升。欢迎各位读者下载试用相关模型。
项目地址:http://electra.hfl-rc.com
中文法律领域ELECTRA
我们在20G版(原版)中文ELECTRA的基础上加入了高质量2000万裁判文书数据进行了二次预训练,在不丢失大规模通用数据上学习到的语义信息,同时使模型对法律文本更加适配。本次发布以下三个模型:
legal-ELECTRA-large, Chinese:24-layer,1024-hidden, 16-heads, 324M parameters
legal-ELECTRA-base, Chinese:12-layer,768-hidden, 12-heads, 102M parameters
legal-ELECTRA-small, Chinese: 12-layer, 256-hidden, 4-heads, 12M parameters
快速加载
哈工大讯飞联合实验室发布的所有中文预训练语言模型均可通过huggingface transformers库进行快速加载访问,请登录我们的共享页面获取更多信息。
https://huggingface.co/HFL
模型键值如下:
hfl/chinese-legal-electra-large-discriminator
hfl/chinese-legal-electra-large-generator
hfl/chinese-legal-electra-base-discriminator
hfl/chinese-legal-electra-base-generator
hfl/chinese-legal-electra-small-discriminator
hfl/chinese-legal-electra-small-generator
效果评测
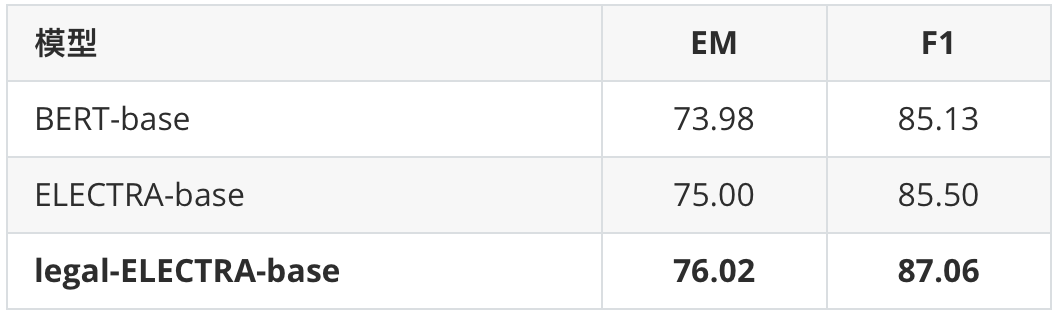
我们在罪名预测以及要素抽取任务上进行了基线测试。其中罪名预测任务使用的是CAIL 2018数据,要素抽取任务为in-house实际应用。可以看到本次发布的法律领域ELECTRA模型均相比通用ELECTRA模型获得了显著性能提升。
表1罪名预测任务
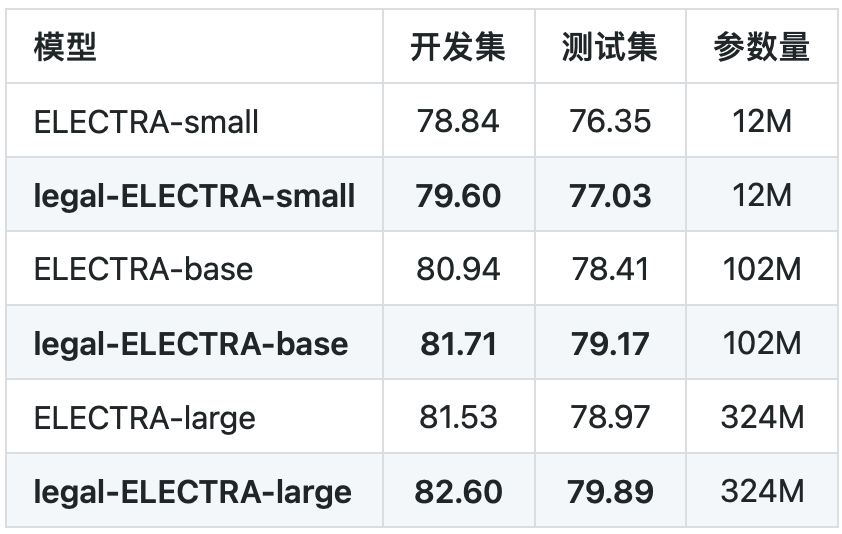
表2要素抽取任务
其他相关资源
TextBrewer知识蒸馏工具
http://textbrewer.hfl-rc.com
中文BERT、RoBERTa、RBT系列模型
http://bert.hfl-rc.com
中文XLNet系列模型
http://xlnet.hfl-rc.com
中文MacBERT模型
http://macbert.hfl-rc.com
责任编辑:xj
原文标题:哈工大讯飞联合实验室发布法律领域ELECTRA预训练模型
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
算法
+关注
关注
23文章
4612浏览量
92901 -
深度学习
+关注
关注
73文章
5503浏览量
121170 -
训练模型
+关注
关注
1文章
36浏览量
3826
原文标题:哈工大讯飞联合实验室发布法律领域ELECTRA预训练模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
小米与聚飞光电成立联合实验室
科大讯飞发布讯飞星火4.0 Turbo大模型及星火多语言大模型
华工科技联合哈工大实现国内首台激光智能除草机器人落地
荣耀与智谱携手共建AI大模型联合实验室
高鸿信安出席飞腾基础软件联合实验室第三届年会
MediaTek与小米集团联合实验室正式揭幕
【大语言模型:原理与工程实践】大语言模型的预训练
西井科技和香港理工大学签署合作协议,将共建联合创新实验室

AI+教育 深圳市中小学联合实验室正式启用






 工商网监
工商网监
评论