 textCNN论文与原理——短文本分类
textCNN论文与原理——短文本分类
前言
之前书写了使用pytorch进行短文本分类,其中的数据处理方式比较简单粗暴。自然语言处理领域包含很多任务,很多的数据向之前那样处理的话未免有点繁琐和耗时。在pytorch中众所周知的数据处理包是处理图片的torchvision,而处理文本的少有提及,快速处理文本数据的包也是有的,那就是torchtext[1]。下面还是结合上一个案例:【深度学习】textCNN论文与原理——短文本分类(基于pytorch)[2],使用torchtext进行文本数据预处理,然后再使用torchtext进行模型分类。
关于torchtext的基本使用除了可以参考官方文档,也可以看看这篇文章:TorchText用法示例及完整代码[3]。
下面就开始看看该如何进行处理吧。
1 数据处理
首先导入包:
from torchtext import data
我们处理的语料中,主要涉及两个内容:文本,文本对应的类别。下面使用torchtext构建这两个字段:
# 文本内容,使用自定义的分词方法,将内容转换为小写,设置最大长度等 TEXT = data.Field(tokenize=utils.en_seg, lower=True, fix_length=config.MAX_SENTENCE_SIZE, batch_first=True) # 文本对应的标签 LABEL = data.LabelField(dtype=torch.float)
其中的一些参数在一个config.py文件中,如下:
# 模型相关参数 RANDOM_SEED = 1000 # 随机数种子 BATCH_SIZE = 128 # 批次数据大小 LEARNING_RATE = 1e-3 # 学习率 EMBEDDING_SIZE = 200 # 词向量维度 MAX_SENTENCE_SIZE = 50 # 设置最大语句长度 EPOCH = 20 # 训练测轮次 # 语料路径 NEG_CORPUS_PATH = ‘。/corpus/neg.txt’ POS_CORPUS_PATH = ‘。/corpus/pos.txt’
utils.en_seg是自定义的文本分词函数,如下:
def en_seg(sentence): “”“ 简单的英文分词方法, :param sentence: 需要分词的语句 返回分词结果 ”“” return sentence.split()
当然也可以书写更复杂的,或者使用spacy。下面就是书写读取文本数据到torchtext对象的数据了,便于使用torchtext中的方法,如下:
def get_dataset(corpus_path, text_field, label_field, datatype): “”“ 构建torchtext数据集 :param corpus_path: 数据路径 :param text_field: torchtext设置的文本域 :param label_field: torchtext设置的文本标签域 :param datatype: 文本的类别 torchtext格式的数据集以及设置的域 ”“” fields = [(‘text’, text_field), (‘label’, label_field)] examples = [] with open(corpus_path, encoding=‘utf8’) as reader: for line in reader: content = line.rstrip() if datatype == ‘pos’: label = 1 else: label = 0 # content[:-2]是由于原始文本最后的两个内容是空格和。,这里直接去掉,并将数据与设置的域对应起来 examples.append(data.Example.fromlist([content[:-2], label], fields)) return examples, fields
现在就可以获取torchtext格式的数据了,如下:
# 构建data数据 pos_examples, pos_fields = dataloader.get_dataset(config.POS_CORPUS_PATH, TEXT, LABEL, ‘pos’) neg_examples, neg_fields = dataloader.get_dataset(config.NEG_CORPUS_PATH, TEXT, LABEL, ‘neg’) all_examples, all_fields = pos_examples + neg_examples, pos_fields + neg_fields # 构建torchtext类型的数据集 total_data = data.Dataset(all_examples, all_fields)
有了上面的数据,下面就可以快速地为准备模型需要的数据了,如切分,构造批次数据,获取字典等,如下:
# 数据集切分 train_data, test_data = total_data.split(random_state=random.seed(config.RANDOM_SEED), split_ratio=0.8) # 切分后的数据查看 # # 数据维度查看 print(‘len of train data: %r’ % len(train_data)) # len of train data: 8530 print(‘len of test data: %r’ % len(test_data)) # len of test data: 2132 # # 抽一条数据查看 print(train_data.examples[100].text) # [‘never’, ‘engaging’, ‘,’, ‘utterly’, ‘predictable’, ‘and’, ‘completely’, ‘void’, ‘of’, ‘anything’, ‘remotely’, # ‘interesting’, ‘or’, ‘suspenseful’] print(train_data.examples[100].label) # 0 # 为该样本数据构建字典,并将子每个单词映射到对应数字 TEXT.build_vocab(train_data) LABEL.build_vocab(train_data) # 查看字典长度 print(len(TEXT.vocab)) # 19206 # 查看字典中前10个词语 print(TEXT.vocab.itos[:10]) # [‘《unk》’, ‘《pad》’, ‘,’, ‘the’, ‘a’, ‘and’, ‘of’, ‘to’, ‘。’, ‘is’] # 查找‘name’这个词对应的词典序号, 本质是一个dict print(TEXT.vocab.stoi[‘name’]) # 2063 # 构建迭代(iterator)类型的数据 train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data), batch_size=config.BATCH_SIZE, sort=False)
这样一看,是不是减少了我们书写的很多代码了。下面就是老生常谈的模型预测和模型效果查看了。
2 构建模型并训练
模型的相关理论已在前文介绍,如果忘了可以回过头看看。模型还是那个模型,如下:
import torch from torch import nn import config class TextCNN(nn.Module): # output_size为输出类别(2个类别,0和1),三种kernel,size分别是3,4,5,每种kernel有100个 def __init__(self, vocab_size, embedding_dim, output_size, filter_num=100, kernel_list=(3, 4, 5), dropout=0.5): super(TextCNN, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) # 1表示channel_num,filter_num即输出数据通道数,卷积核大小为(kernel, embedding_dim) self.convs = nn.ModuleList([ nn.Sequential(nn.Conv2d(1, filter_num, (kernel, embedding_dim)), nn.LeakyReLU(), nn.MaxPool2d((config.MAX_SENTENCE_SIZE - kernel + 1, 1))) for kernel in kernel_list ]) self.fc = nn.Linear(filter_num * len(kernel_list), output_size) self.dropout = nn.Dropout(dropout) def forward(self, x): x = self.embedding(x) # [128, 50, 200] (batch, seq_len, embedding_dim) x = x.unsqueeze(1) # [128, 1, 50, 200] 即(batch, channel_num, seq_len, embedding_dim) out = [conv(x) for conv in self.convs] out = torch.cat(out, dim=1) # [128, 300, 1, 1],各通道的数据拼接在一起 out = out.view(x.size(0), -1) # 展平 out = self.dropout(out) # 构建dropout层 logits = self.fc(out) # 结果输出[128, 2] return logits
为了方便模型训练,测试书写了两个函数,当然也和之前的相同,如下:
def binary_acc(pred, y): “”“ 计算模型的准确率 :param pred: 预测值 :param y: 实际真实值 返回准确率 ”“” correct = torch.eq(pred, y).float() acc = correct.sum() / len(correct) return acc def train(model, train_data, optimizer, criterion): “”“ 模型训练 :param model: 训练的模型 :param train_data: 训练数据 :param optimizer: 优化器 :param criterion: 损失函数 该论训练各批次正确率平均值 ”“” avg_acc = [] model.train() # 进入训练模式 for i, batch in enumerate(train_data): pred = model(batch.text) loss = criterion(pred, batch.label.long()) acc = binary_acc(torch.max(pred, dim=1)[1], batch.label) avg_acc.append(acc) optimizer.zero_grad() loss.backward() optimizer.step() # 计算所有批次数据的结果 avg_acc = np.array(avg_acc).mean() return avg_acc def evaluate(model, test_data): “”“ 使用测试数据评估模型 :param model: 模型 :param test_data: 测试数据 该论训练好的模型预测测试数据,查看预测情况 ”“” avg_acc = [] model.eval() # 进入测试模式 with torch.no_grad(): for i, batch in enumerate(test_data): pred = model(batch.text) acc = binary_acc(torch.max(pred, dim=1)[1], batch.label) avg_acc.append(acc) return np.array(avg_acc).mean()
涉及相关包的话,就自行导入即可。下面就是创建模型和模型训练测试了。好紧张,又到了这个环节了。
# 创建模型 text_cnn = model.TextCNN(len(TEXT.vocab), config.EMBEDDING_SIZE, len(LABEL.vocab)) # 选取优化器 optimizer = optim.Adam(text_cnn.parameters(), lr=config.LEARNING_RATE) # 选取损失函数 criterion = nn.CrossEntropyLoss() # 绘制结果 model_train_acc, model_test_acc = [], [] # 模型训练 for epoch in range(config.EPOCH): train_acc = utils.train(text_cnn, train_iterator, optimizer, criterion) print(“epoch = {}, 训练准确率={}”.format(epoch + 1, train_acc)) test_acc = utils.evaluate(text_cnn, test_iterator) print(“epoch = {}, 测试准确率={}”.format(epoch + 1, test_acc)) model_train_acc.append(train_acc) model_test_acc.append(test_acc) # 绘制训练过程 plt.plot(model_train_acc) plt.plot(model_test_acc) plt.ylim(ymin=0.5, ymax=1.01) plt.title(“The accuracy of textCNN mode”) plt.legend([‘train’, ‘test’]) plt.show()
模型最后的结果如下:
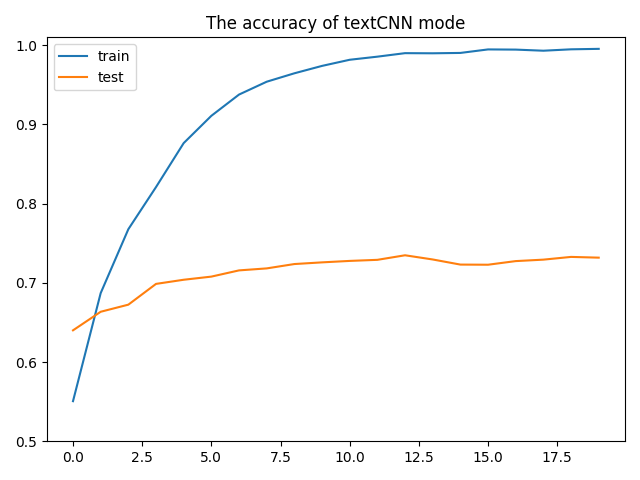
模型训练过程
这个和之前结果没多大区别,但是在数据处理中却省去更多的时间,并且也更加规范化。所以还是有时间学习一下torchtext咯。
3 总结
torchtext支持的自然语言处理处理任务还是比较多的,并且自身还带有一些数据集。最近还在做实体识别任务,使用的算法模型是bi-lstm+crf。这个任务的本质就是序列标注,torchtext也是支持这种类型数据的处理的,后期有时间的话也会做相关的介绍,记得关注哦。对啦,本文的全部代码和语料,我都上传到github上了:https://github.com/Htring/NLP_Applications[4],后续其他相关应用代码也会陆续更新,也欢迎star,指点哦。
原文标题:textCNN论文与原理——短文本分类(基于pytorch和torchtext)
文章出处:【微信公众号:自然语言处理爱好者】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
python
+关注
关注
56文章
4811浏览量
85102 -
深度学习
+关注
关注
73文章
5521浏览量
121660
原文标题:textCNN论文与原理——短文本分类(基于pytorch和torchtext)
文章出处:【微信号:NLP_lover,微信公众号:自然语言处理爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用自然语言处理分析文本数据
图纸模板中的文本变量
如何在文本字段中使用上标、下标及变量

使用LLM进行自然语言处理的优缺点
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
利用TensorFlow实现基于深度神经网络的文本分类模型
llm模型有哪些格式
llm模型和chatGPT的区别
卷积神经网络在文本分类领域的应用

交换机的基本分类
鸿蒙UI界面——@ohos.measure (文本计算)
了解如何使用PyTorch构建图神经网络





 工商网监
工商网监
评论