 从BERT得到最强句子Embedding的打开方式
从BERT得到最强句子Embedding的打开方式
你有尝试从 BERT 提取编码后的 sentence embedding 吗?很多小伙伴的第一反应是:不就是直接取顶层的[CLS] token的embedding作为句子表示嘛,难道还有其他套路不成?
nono,你知道这样得到的句子表示捕捉到的语义信息其实很弱吗?今天向大家介绍一篇来自于 CMU 和字节跳动合作,发表在 EMNLP2020 的 paper, 详尽地分析了从预训练模型得到 sentence embedding 的常规方式的缺陷和最佳打开方式,是一篇非常实用、轻松帮助大家用BERT刷分的文章。论文质量蛮高,分析和发现很有趣,通读之后感觉收获多多。
自2018年BERT惊艳众人之后,基于预训练模型对下游任务进行微调已成为炼丹的标配。然而近两年的研究却发现,没有经过微调,直接由BERT得到的句子表示在语义文本相似性方面明显薄弱,甚至会弱于GloVe得到的表示。此篇论文中首先从理论上探索了masked language model 跟语义相似性任务上的联系,并通过实验分析了BERT的句子表示,最后提出了BERT-Flow来解决上述问题。
为什么BERT的句子Embeddings表现弱?
由于Reimers等人之前已实验证明 context embeddings 取平均要优于[CLS] token的embedding。因而在文章中,作者都以最后几层文本嵌入向量的平均值来作为BERT句子的表示向量。
语义相似性与BERT预训练的联系
为了探究上述问题,作者首先将语言模型(LM)与掩盖语言模型(MLM) 统一为: 给定context(c)预测得到 token(x) 的概率分布,即
这里 是context的embedding, 表示 的word embedding。进一步,由于将 embedding 正则化到单位超球面时,两个向量的点积等价于它们的cosine 相似度,我们便可以将BERT句子表示的相似度简化为文本表示的相似度,即 。
另外,考虑到在训练中,当 c 与 w 同时出现时,它们对应的向量表示也会更接近。换句话说,context-context 的相似度可以通过 context-words 之间的相似度推出或加强。
各向异性嵌入空间
Jun Gao, Lingxiao Wang 等人在近几年的ICLR paper中有提到语言模型中最大似然目标的训练会产生各向异性的词向量空间,即向量各个方向分布并不均匀,并且在向量空间中占据了一个狭窄的圆锥体,如下图所示~
这种情况同样也存在于预训练好的基于Transformer的模型中,比如BERT,GPT-2。而在这篇paper中,作者通过实验得到以下两个发现:
词频率影响词向量空间的分布:文中通过度量BERT词向量表示与原点 l_2 距离的均值得到以下的图表。我们可以看到高频的词更接近原点。由于word embedding在训练过程中起到连接文本embedding的作用,我们所需的句子表示向量可能会相应地被单词频率信息误导,且其保留的语义信息可能会被破坏。

低频词分布偏向稀疏:文中度量了词向量空间中与K近邻单词的 l_2 距离的均值。我们可以看到高频词分布更集中,而低频词分布则偏向稀疏。然而稀疏性的分布会导致表示空间中存在很多“洞”,这些洞会破坏向量空间的“凸性”。考虑到BERT句子向量的产生保留了凸性,因而直接使用其句子embeddings会存在问题。
Flow-based 生成模型
那么,如何无监督情况下充分利用BERT表示中的语义信息?为了解决上述存在的问题,作者提出了一种将BERT embedding空间映射到一个标准高斯隐空间的方法(如下图所示),并称之为“BERT-flow”。而选择 Gaussian 空间的动机也是因为其自身的特点:
标准高斯分布满足各向同性
高斯分布区域没有“洞”,即不存在破坏“凸性”的情况
上图中 表示隐空间, 表示观测到的空间,f: 是可逆的变换。根据概率密度函数中变量替换的定理,我们可以得到观测变量的概率密度函数如下:
进一步,作者通过最大化BERT句子表示的边缘似然函数来学习基于流的生成模型,即通过如下的公式来训练flow的参数:
其中 表示数据集分布, 为神经网络。需要注意的是,在训练中,不需要任何人工标注!另外,BERT的参数保持不变,仅有流的参数进行优化更新。其次,在实验中,作者基于Glow (Dinh et al., 2015)的设计(多个可逆变换组合)进行改动,比如将仿射耦合(affine coupling)替换为了加法耦合(additive coupling)。
实验及结果
论文的实验部分在7个数据集上进行衡量语义文本相似性任务的效果。
实验步骤:
通过句子encoder得到每个句子的向量表示。
计算句子之间的cosine similarity 作为模型预测的相似度。
计算Spearman系数。
实验结果:
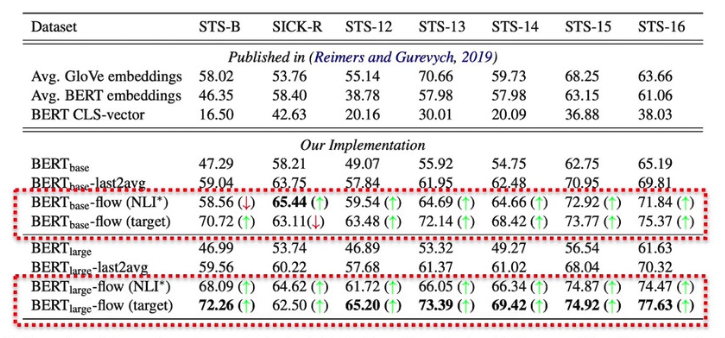
上图汇报了sentence embeddings的余弦相似度同多个数据集上真实标签之间的Spearman等级相关性得分(),其中flow-target 表示在完整的目标数据集(train+validation+test)上进行学习,flow-NLI 表示模型在NLI(natual language inference)任务的测试,绿色箭头表示相对于BERT的baseline,模型的效果有提升,红色反之。
我们可以注意到模型的改进对于效果的提升还是很显著滴!文章同样还在无监督问答任务证明模型的有效性,并将BERT-flow得到的语义相似度同词法相似度(通过编辑距离来衡量)进行对比,结果同样证明模型在引入流的可逆映射后减弱了语义相似性与词法相似性之间的联系!具体信息大家可查阅paper~
小结
总之,这篇paper探究了BERT句子表示对于语义相似性上潜在的问题,并提出了基于流的可逆映射来改进在对应任务上的表现。想多了解的童鞋可以看看原文,相信你们也会喜欢上这篇paper!
原文标题:还在用[CLS]?从BERT得到最强句子Embedding的打开方式!
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
计算机
+关注
关注
19文章
7492浏览量
87910 -
模型
+关注
关注
1文章
3238浏览量
48827
原文标题:还在用[CLS]?从BERT得到最强句子Embedding的打开方式!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
掌握压铸铝件气密性检测设备的正确打开方式-岳信仪器

嵌入式学习-飞凌嵌入式ElfBoard ELF 1板卡 -通用文件I/O模型之open
飞凌嵌入式ElfBoard ELF 1板卡-通用文件I/O模型之open
内置误码率测试仪(BERT)和采样示波器一体化测试仪器安立MP2110A

M8020A J-BERT 高性能比特误码率测试仪
换热设备清洗的正确打开方式,不仅清洗效果好,而且安全无腐蚀

AWG和BERT常见问题解答
新品|酷暑的新打开方式:SXB3568主板

请问esp32能不能自动找到信号最强的wifi ap进行连接?
Jacob:纯提效的工具,也许不是AI正确的打开方式

汽车水箱气密性检测仪的正确打开方式






 工商网监
工商网监
评论