 AMD申请小芯片专利:RDNA3或将暴力堆核
AMD申请小芯片专利:RDNA3或将暴力堆核
随着半导体工艺、芯片规模的限制越来越大,传统的单个大芯片策略已经行不通,小芯片(Chiplet)成为新的方向,AMD无疑是其中的佼佼者,锐龙、线程撕裂者、霄龙三大产品线都在践行这一原则,并且取得了不俗的效果。现在,AMD要把这一策略延续到GPU显卡上了。
2020年的最后一天,AMD向美国专利商标局提交了一项新专利,勾勒了未来的GPU小芯片设计。
图:小芯片(Chiplet),AMD已经玩儿得很溜
AMD首先指出,传统的多GPU设计存在诸多问题(包括AMD自己的CrossFire),比如GPU编程模型不适合多路GPU,很难在多个GPU之间并行分配负载,多重GPU之间缓存内容同步极为复杂,等等。
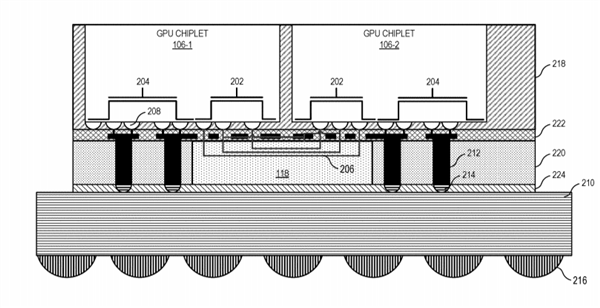
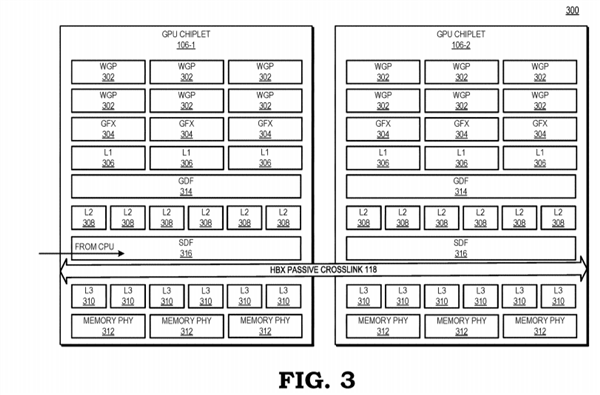
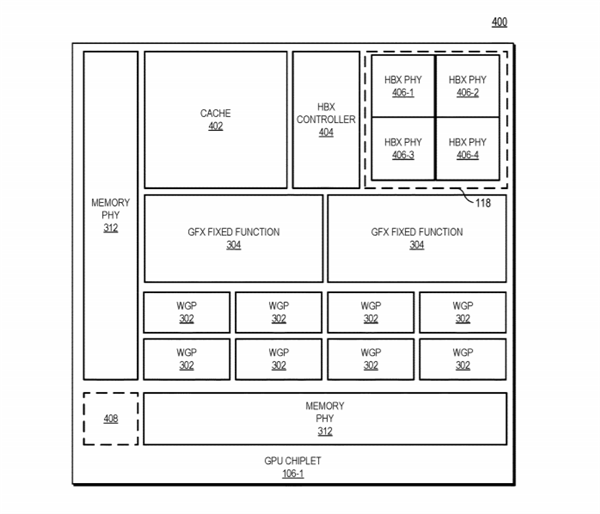
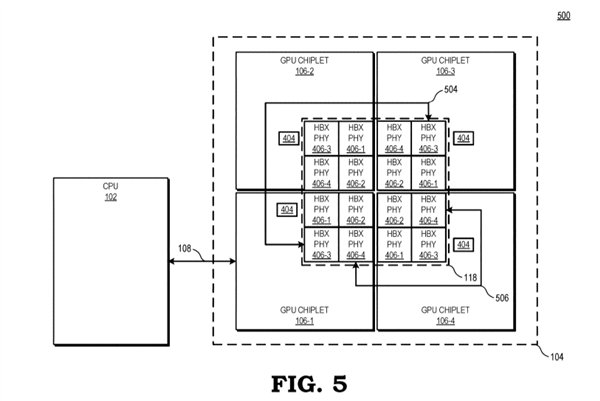
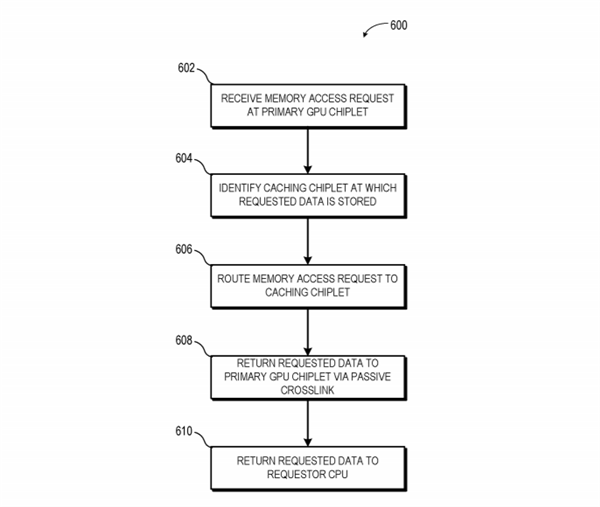
AMD的思路是利用“高带宽被动交联”(high bandwidth passive crosslink)来解决这些障碍,将第一个GPU小芯片与CPU处理器直接耦合在一起(communicably coupled),而其他GPU小芯片都通过被动交联与第一个GPU小芯片耦合,而所有的GPU小芯片都放置在同一个中介层(interposer)之上。
这样一来,整个GPU阵列就被视为单独一个SoC,然后划分成不同功能的子芯片。
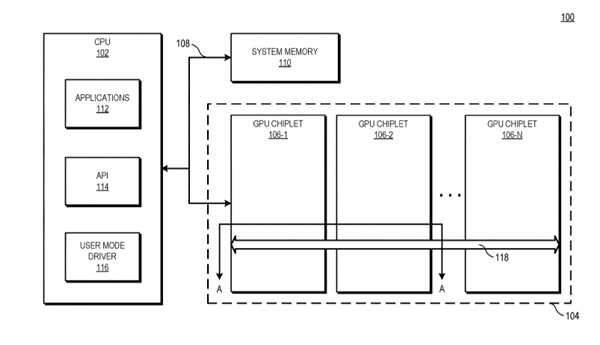
传统的GPU设计中,每个GPU都有自己的末级缓存,但为了避免同步难题,AMD也重新设计了缓存体系,每个GPU依然有自己的末级缓存,但是这些缓存和物理资源耦合在一起,因此所有缓存在所有GPU之间依然是统一的、一致性的。
听起来很难懂对吧?确实如此,毕竟一般在专利文件中,厂商往往都会故意隐藏具体设计细节,甚至可能存在一些故意使之难以理解、甚至误导的描述。
AMD没有透露是否正在实际进行GPU小芯片设计,但早先就有传闻称,下一代的RNA3架构就会引入多芯片,这份专利正提供了进一步佐证。
可以预料,RDNA3架构如果真的上小芯片设计,核心规模必然会急剧膨胀,一两万个流处理器都是小意思。
AMD也不是唯一有此想法的人。Intel Xe HP、Xe HPC高性能架构就将采取基于Tile区块的设计,今年晚些时候问世,直奔高性能计算、数据中心而去。
NVIDIA据说会在Hopper(霍珀)架构上采用MCM多芯封装设计,而在那之前还有一代“Ada Lovelace”(阿达·洛夫莱斯),有望上5nm工艺,并堆到多达18432个流处理器。
-
amd
+关注
关注
25文章
5470浏览量
134255 -
gpu
+关注
关注
28文章
4744浏览量
129018 -
chiplet
+关注
关注
6文章
434浏览量
12604
发布评论请先 登录
相关推荐
AMD获得玻璃核心基板技术专利
发现基于Zen 5架构的AMD Threadripper “Shimada Peak” 96核和16核CPU


AMD或涉足手机芯片市场
AMD确认2025年推出RDNA 4显卡,光追与AI性能大幅提升
如何申请xilinx IP核的license
AMD RDNA4或采用GDDR6显存,Navi 4X或Navi 4C具备216个计算单元
AMD明年Zen5 APU性能确切,Strix Halo APU将应用多芯粒
AMD RDNA4显卡全部搭载18Gbps显存,带宽略逊于部分RDNA3产品
AMD锐龙PRO8040/8000系列新品预计下半年台积电代工上市
欧洲专利局2023年专利申请量创新纪录
华为领跑2023年国际专利体系申请量
苹果申请可折叠设备专利
AMD Zen6架构继续飞跃!核显跨越下下代RDNA5






 工商网监
工商网监
评论