 揭秘赛灵思计算平台ACAP技术细节
揭秘赛灵思计算平台ACAP技术细节

在日前召开的FPGA领域的学术顶会--2019年“FPGA国际研讨会”上,赛灵思发表了两篇长论文,详细介绍了赛灵思“自适应计算加速平台”ACAP的系统架构和技术细节。本文将对ACAP的主要架构创新进行深入解读,让各位先睹为快。
ACAP是赛灵思在2018年推出的新一代计算平台。在发布伊始,赛灵思新任掌门人Victor Peng就再三强调,ACAP并不是FPGA,而是整合了硬件可编程逻辑单元、软件可编程处理器、以及软件可编程加速引擎的计算平台产品,是赛灵思“发明FPGA以来最卓越的工程成就”,足可见这个产品系列的重要性。
与其说ACAP是某种具体的芯片产品,不如说它像FPGA一样,代指一种芯片架构。而赛灵思这次发表的论文,主要介绍的是基于ACAP架构的首款产品,名为Versal,并将基于台积电的7纳米工艺制造。相比传统的FPGA架构,Versal ACAP在系统架构、电路结构、互联方式等很多方面进行了大胆革新,这也是本文将要讨论的重点。
芯片架构
Versal ACAP的芯片布局如下图所示。总体来看,它与传统FPGA结构非常类似,主要包含可编程逻辑部分、高速I/O与收发器、嵌入式处理器、存储器控制等FPGA的常见硬件资源与模块。
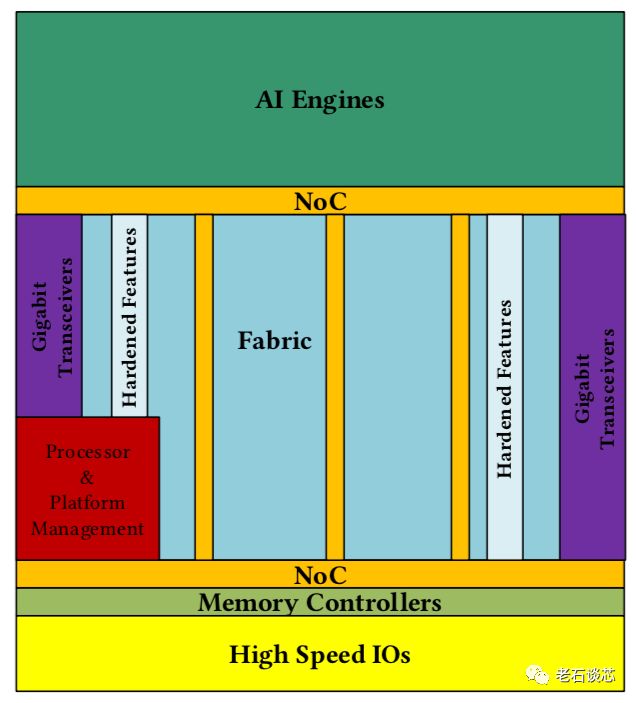
值得注意的是,ACAP架构与传统FPGA有两点主要区别:
芯片顶端(北侧)包含了AI加速引擎阵列,它们主要用来加速机器学习和无线网络等应用中常见的数学计算。然而,关于AI引擎的具体结构,在这篇论文中并未提及。
在传统FPGA片上互联技术的基础上,ACAP采用了固化的片上网络(NoC),这主要是针对高带宽、高吞吐量的应用场景,如存储器控制和AI应用等,在上图中也可以清晰的看到NoC与这些应用模块的紧密互联。
关于NoC的具体技术细节,在本次会议有另外一篇论文进行详细阐述,见下图。本文将对其进行简单概述,并会在下篇文章中深入解析。
除NoC以外,ACAP选择将很多常用的IP固化在芯片上,以提高性能、稳定性,并减少额外的可编程逻辑资源的使用。除了常见的PCIe、DDR控制器、以太网MAC之外,ACAP还选择将嵌入式处理器和芯片管理单元进行固化,这令人有些意外。
在论文中介绍,在亚马逊AWS F1实例中使用的片上管理单元占据了芯片面积的很大部分,如下图所示,而这也是赛灵思选择在ACAP上对这类逻辑进行固化的主要原因。
在可编程芯片上固化逻辑其实是一把双刃剑,在提升性能和降低逻辑单元使用率的同时,牺牲的是被固化单元的灵活性。因此,往往只会选择固化已经由成熟标准的逻辑单元,比如上文提到的通信接口与内存控制器等。对于芯片管理单元,固化后是否仍能适用于不同的应用场景?是否比集成ARM等硬核处理器更有效?这些问题就需要通过实际使用得到答案。
Versal ACAP架构的一个主要的创新之处,就是采用了非常规整的可编程逻辑阵列和时钟域分布。老石之前曾介绍过一种名为“Overlay”的FPGA虚拟化技术,它的本质就是在FPGA的硬件层之上,抽象出一层虚拟的Overlay结构,如下图所示。Overlay层基于CGRA等规整的逻辑结构,对应用层非常友好,但对不规整的FPGA底层架构而言,实现起来势必会造成资源的浪费和性能的损失。
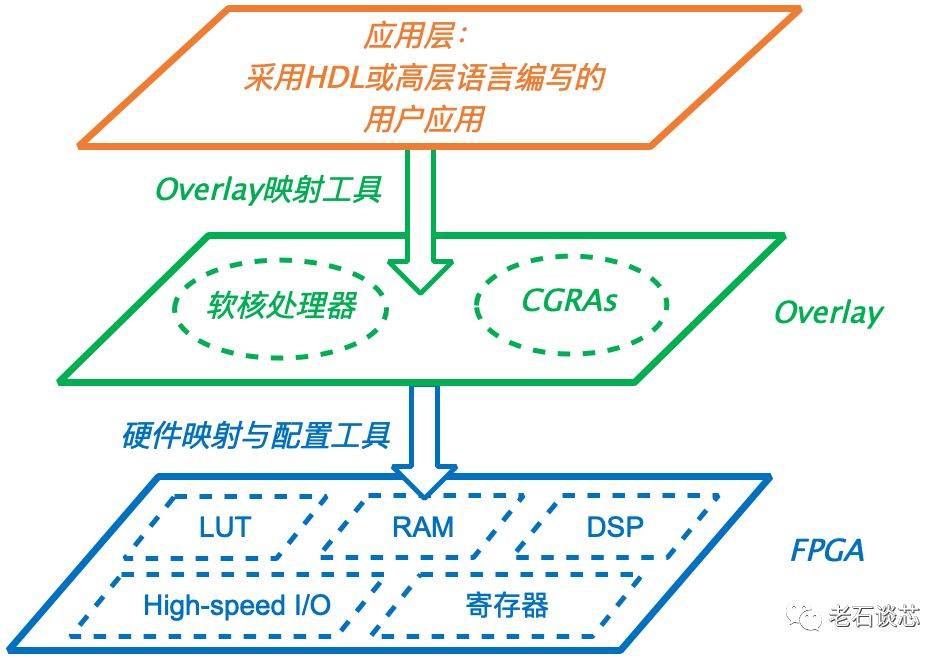
ACAP架构采用了更加规整的可编程逻辑阵列,以及分布均匀的时钟域,理论上这是极其有用的创新,特别是对于布局布线后的设计而言。通过这种方式,使得IP接口可以复用,即把一个IP从一个位置挪到另一个位置时,不需要对整个设计重新编译,只需要单独处理修改的部分即可。
更重要的是,这使得用户可以重复使用已经完成布局布线的“半成品”或“模板”,只需要在事先保留的区域内加入新设计即可,这样可以极大的减少编译时间。这个创新与目前FPGA已有的划分可编程区域等技术类似,但更进一步。只可惜,在这篇论文中没有给出这个创新的任何实例或数据,因此很难确定这项技术是否已经实现,还是仅仅停留在理论层面。
CLB微结构
CLB是可编程逻辑块的缩写,它包含了多个可编程逻辑单元及其互联。与传统FPGA相比,Versal ACAP对它的CLB微结构进行了重大革新,用“翻天覆地”来形容也不为过。其中,最主要的架构变化有以下四点。
首先,CLB的容量相较UltraScale FPGA架构扩大了四倍,包含32个LUT和64个寄存器,见下图。
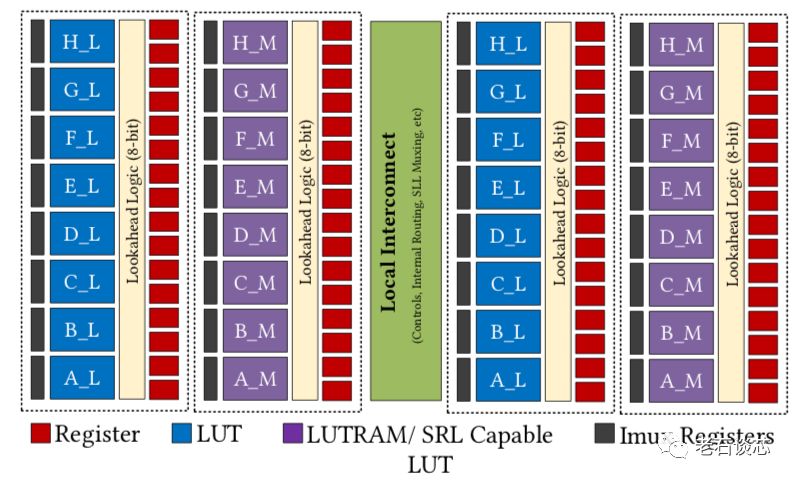
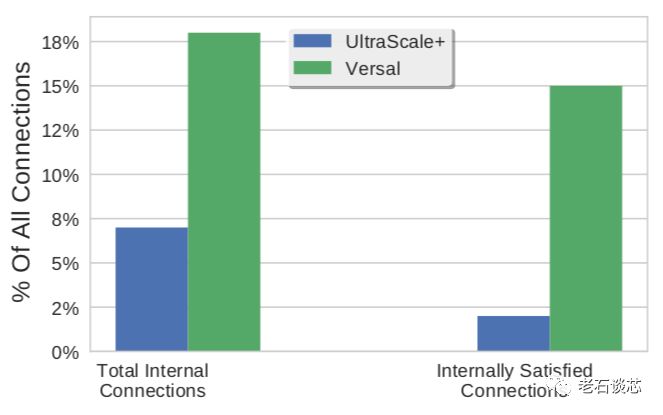
这样做的主要目的,是为了减少全局布线资源的使用。ACAP为每个CLB设置了单独的内部高速互联,与全局布线相比,这些内部互联更加快速,布线逻辑也更简单,从而减轻了全局布线的压力与拥挤。如下图所示,采用了大CLB后,有18%的布线可以通过内部互联完成。而对于传统FPGA,只有7%的布线能在CLB内完成,其他都需要占用全局布线资源。
第二,每个查找表结构(LUT)增加了一个额外的输出,这是一个重要的架构变化。传统FPGA的LUT结构为6输入、2输出,如下图所示,可以实现任意的6输入逻辑,或者两个5输入逻辑。当添加了一个新的输出O5_2之后,就可以实现两个独立的6输入逻辑功能。
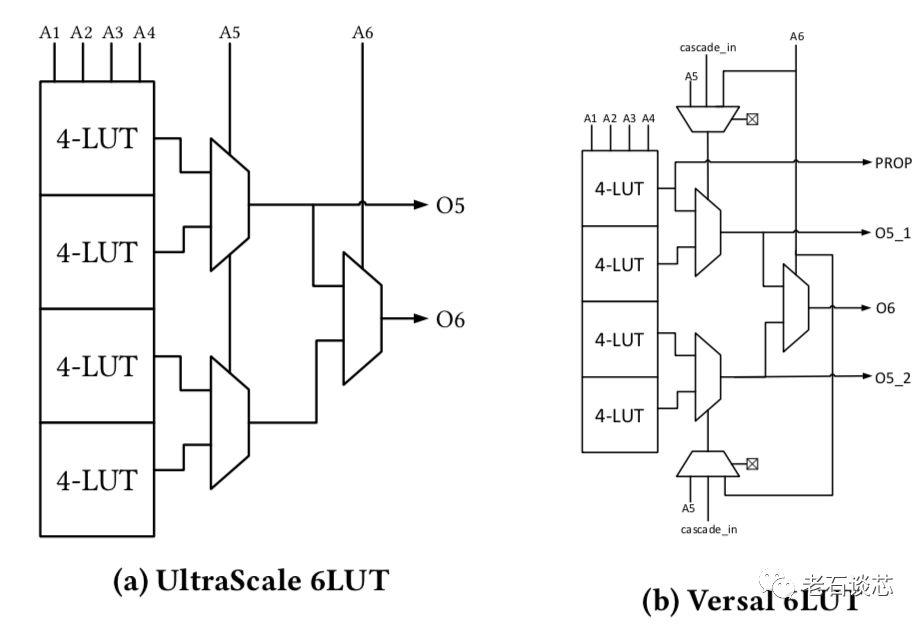
这种结构的另外一个好处,是允许更多的逻辑功能进行合并,以减少LUT的使用量。FPGA设计工具会根据两个LUT的距离,判断这两个LUT里的逻辑能否进行合并。例如,与UltraScale架构相比,当两个LUT之间的距离小于5个Slice网格距离时,Versal ACAP架构能多合并21.5%的逻辑功能,从而减少相应的硬件资源使用。
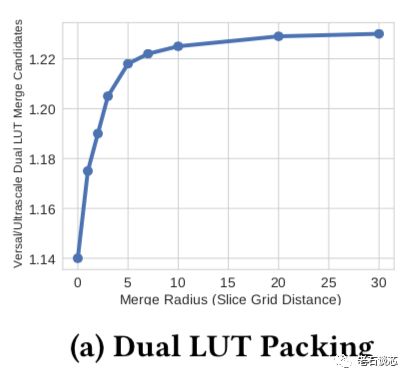
作为代价,在UltraScale架构中存在的Wide Function功能被移走。因此如果需要实现诸如32:1的选择器时,就可能会扩展到多个Slice,对时序造成负面影响,并且需要额外的硬件资源支持。
第三,每个Slice的进位链逻辑结构进行了彻底修改,如下图所示。事实上,一直是现代FPGA标配的固化进位链被完全移除,取而代之的是使用LUT中新增加的cascade_in和LUT逻辑完成加法结构。
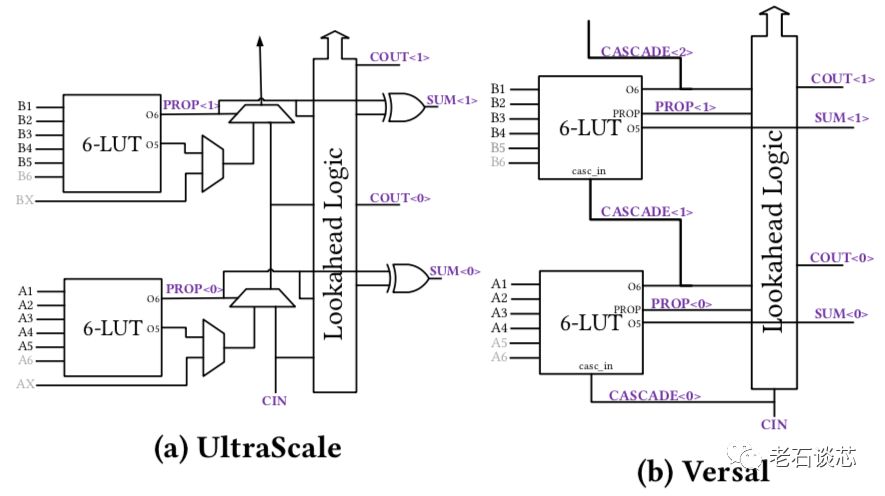
论文中对这部分的讨论过于简单,对这个重要的架构改变没有给出详细原因,对上图中Versal进位链的具体实现结构也含糊不清。老石猜测,这个改变的主要原因还是由于新增加的第二个LUT输出,如果继续保留进位链逻辑,会导致LUT间延时过大,从而影响时序。但是,这种新的进位链结构是否会对算术运算的性能产生负面影响,赛灵思并未在论文中给出数据佐证。
第四,引入了名为“Imux寄存器”的新结构。这种新寄存器架构很明显是用来对标英特尔的HyperFlex架构。Imux寄存器共有四种模式,如下图所示。
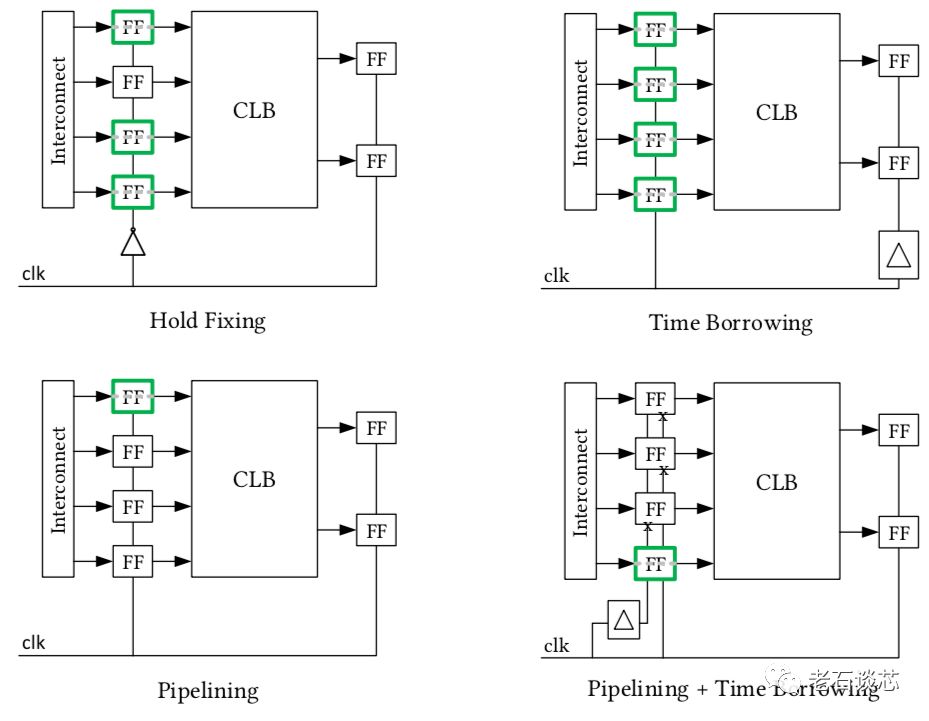
这种架构只在CLB之前引入了用于优化时序、增加流水线的寄存器。同时,这些寄存器包含了复位、初始化、时钟使能等常见寄存器功能。这与HyperFlex的海量寄存器架构有着明显不同,如下图。Imux没有在全部布线资源上都设置寄存器,因此引入的额外延时会更小。但在深度流水线设计中,这种结构的绝对性能应该不如HyperFlex架构。
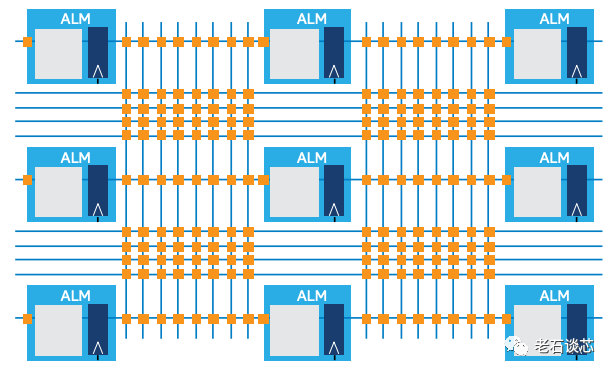
上面的四种Imux使用模式在本文中不再赘述,例如下图展示了其中的Time Borrowing、Pipelining、以及二者结合的模式。但这几种方式与传统的流水线和Retiming方式并没有本质区别。
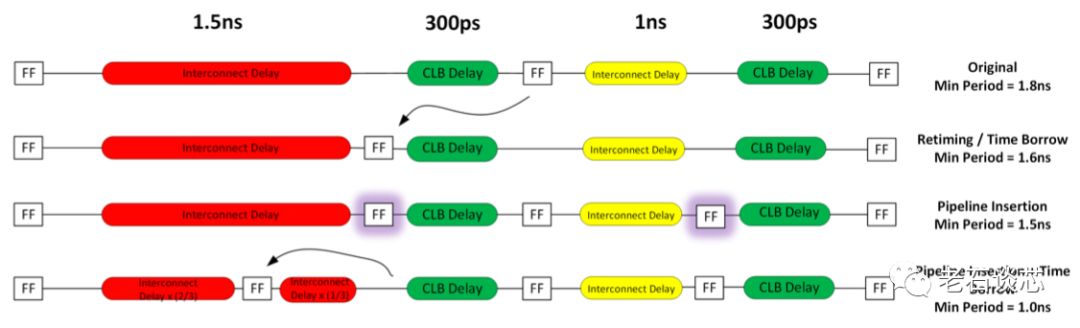
关于Imux寄存器架构,这篇论文最严重的问题在于实测数据和对比很少。这样的实验和论述,使得这部分内容更像一篇白皮书,而非高端学术论文。严谨的学术方法是需要兼顾可重复性和标准性,例如,选取一些标准的参考设计和Benchmark,分别使用英特尔的HyperFlex架构、赛灵思的UltraScale架构,以及这里提出的Imux架构,进行实现,并测量这些在这些架构上分别能得到多快的运行频率。很显然,这篇论文在很多地方都存在这样的问题。
3D芯片制造技术SSIT
ACAP采用了赛灵思的第四代硅片堆叠技术SSIT。关于这个技术的细节,老石在之前的文章中详细介绍过。这个技术本质上是将多个小型硅片,放置在一个大的无源硅中介层上,然后通过硅通孔和芯片连线进行互联,从而组成一个大芯片。
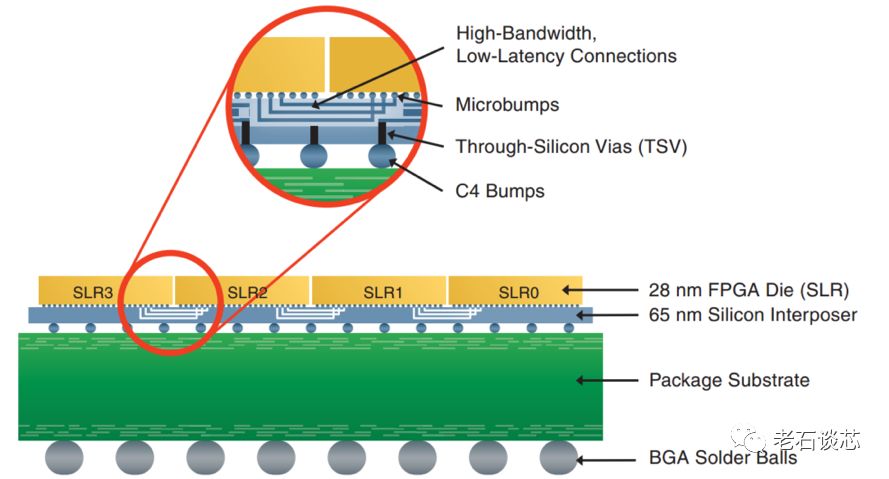
这种技术非常适合在每代半导体工艺的发展早期,特别是制造大型硅片的良率较低的情况。另外,SSIT的灵活性比较高,技术思路比较直接,发展至今已有四代,已经比较成熟。
不过,这种技术的主要问题非常明显,主要有以下几点:
当工艺成熟后,这种方式带来的良率提升就不甚明显,综合成本反而会上升。
将多枚硅片通过硅中间层组合,可能会带来明显的性能降低。这主要受制于硅片间的互联资源,以及互联导线的巨大延迟。
该技术会限制FPGA配置的灵活性,因为它相当于人为的增加了多个设计区域和边界。这也对设计工具的优化能力造成了很大的挑战。
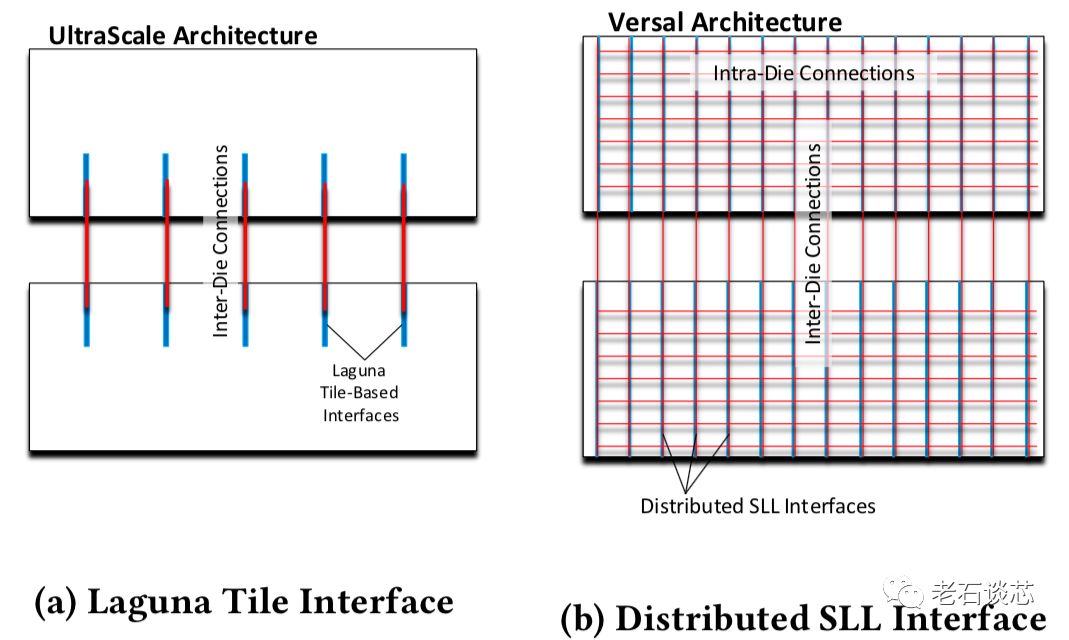
在这篇论文中,Versal ACAP主要针对上面的第二和第三点进行了优化和改进。例如,在Versal架构中,采用了更多的硅片间的互联通道(SLL channel),如下图所示。同时,这些互联通道的传输延时也得到了进一步优化,相比传统连线的延时下降了30%。
片上网络NoC
片上网络是ACAP的主要技术革新之一。对于诸如DDR、高速网络、PCIe等高速接口与应用来说,通常有着很高的带宽要求。这一方面需要采用高位宽的总线,另一方面需要高速时钟。因此,传统的FPGA设计方法都是通过对总线进行深度流水线来实现。但对于一个大型设计而言,这种方法会很快造成片上布线资源的拥挤。这就需要寻找有效的方法,同时解决高速数据传输和低拥堵布线两个问题。
ACAP采用了片上网络(Network-on-Chip,NoC)技术应对上述问题。在传统的FPGA布线资源之外,引入了NoC网络,将需要进行高速数据传输的内容转化成基于数据包的形式,通过NoC的交换机逻辑实现数据交换,如下图所示。与网络应用类似,这种片上网络也能对各类的传输进行服务质量控制(QoS)。
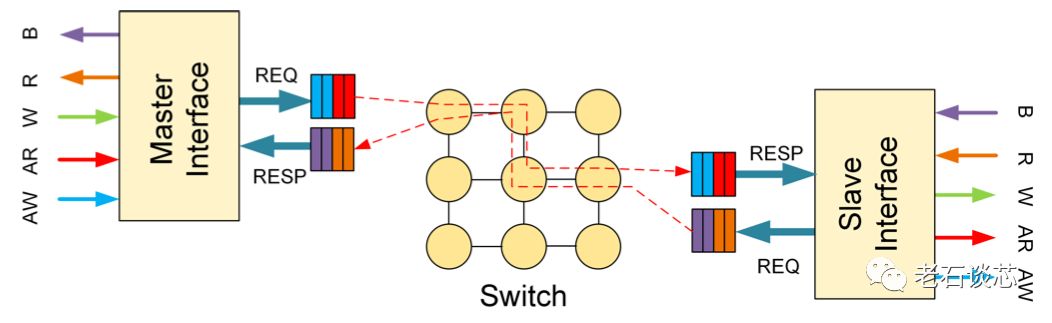
这种方法最大的优点是在系统层面,将数据传输与数据计算进行了分离,从而在保证带宽的基础上,缓解了系统的布局布线压力。例如,数据计算可以在AI引擎或片上其他部分实现,而不需紧靠DDR控制器等高速接口。
不过,这种方法的主要问题是引入了额外的传输延时,这对于需要固定延时或者低延时的应用可能会有影响。在这篇论文中,并没有提及延时的数据。此外,片上网络的位宽是固定的,无法对应用进行优化,这也有可能对不同应用的系统性能造成负面影响。
结语
ACAP作为赛灵思重磅推出的下一代计算平台,从发布之初就备受瞩目。究竟ACAP是不是FPGA,这个问题其实并不重要,重要的是ACAP的本质仍然是基于可编程逻辑阵列的异构计算芯片。与传统FPGA架构相比,ACAP带来了诸多系统和微结构的换代和革新,这也让人们看到了业界为了延续摩尔定律的发展所做的不懈努力。
就这篇论文而言,虽然很多地方的学术严谨性有待提高,但瑕不掩瑜。作为第一篇完整的介绍Versal ACAP架构细节的论文,它还是为我们带来了很多对ACAP新结构、新技术的详细阐述和讨论,也让我们得以一窥ACAP的技术细节。
原文标题:赛灵思计算平台ACAP技术细节全揭秘
文章出处:【微信公众号:FPGA技术江湖】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
FPGA
+关注
关注
1664文章
22537浏览量
640181 -
赛灵思
+关注
关注
33文章
1798浏览量
133719 -
ACAP
+关注
关注
1文章
54浏览量
8769
原文标题:赛灵思计算平台ACAP技术细节全揭秘
文章出处:【微信号:HXSLH1010101010,微信公众号:FPGA技术江湖】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深入剖析 TMS570LS0914 微控制器:特性、应用与技术细节
T89C51CC01微控制器:特性、应用与技术细节深度解析
赛灵思FPGA电源解决方案全解析
2.4 GHz低通滤波器2450LP15A050:技术细节与设计考量
工程师必入!288 元解锁赛灵思开发板

有哪些具体的技术细节需要企业在选择电能质量在线监测装置数据存储方式时注意?
PCIe 7.0技术细节曝光

揭秘徐工新能源重卡的技术细节
【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
SMA连接器名称由来:SubMiniature Version A 的技术细节

比亚迪 · 超级e平台 · 技术方案的全面揭秘 | 第三曲: 30000转驱动电机 · 12项核心技术揭秘




评论