 机器人定位及建图的准确性和鲁棒性
机器人定位及建图的准确性和鲁棒性
将一个机器人随机放入未知环境中,是否有办法让机器人一边移动一边确定自己的位置并构建该环境的地图?近日,由重庆大学王科副教授带领的团队的论文 SBAS:Salient Bundle Adjustment for Visual SLAM,将显著性预测模型应用于 SLAM 框架中去,模拟人类执行这一任务的过程,有效提升了机器人定位及建图的准确性和鲁棒性。
1. 什么是 SLAM?
SLAM 的全称是 Simultaneous Localization And Mapping,即同时定位与建图。
通俗来说,该技术希望搭载特定传感器的机器人在未知的环境中,通过不断的运动提取环境中的特征如墙角、柱子等来估计自身的位置,并同时根据传感器观测到的数据建立环境的地图,从而达到同时定位和地图构建的目的。
通常情况下,基于几何的方法的 SLAM 技术可以分为两类:特征法和直接法。
特征法通过提取和匹配图像中的关键点通过最小化重投影误差来估计相机的姿态,而直接法则直接利用图像中的像素强度通过最小化光度误差来估计相机的姿态。目前,该领域已经有了一些较为出色的算法模型。
MonoSLAM 是第一个使用扩展卡尔曼滤波(EKF)和 Shi-Tomasi 角点的实时视觉 SLAM 系统。该方法简化了 SLAM 对硬件的要求,并可以被应用于仿人机器人实时 3D 定位和建图以及手持相机的在线增强现实。

PTAM 是最早提出将 Track 和 Map 分开作为两个线程的一种 SLAM 算法,也是一种基于关键帧的单目视觉 SLAM 算法。采用非线性优化方法代替基于滤波器的方法作为后端优化方法,PTAM 提出并实现了跟踪映射过程的并行化。
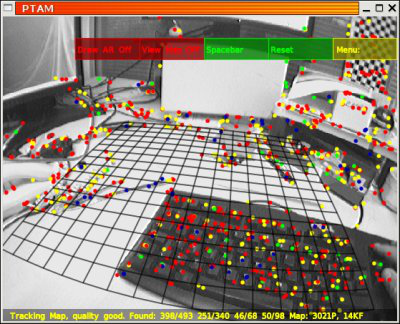
直接法不提取特征点,而是利用像素强度通过最小化光度误差来估计摄像机的姿态。基于直接法的 SLAM 模型如下:
DTAM 是第一个使用直接方法生成密集三维地图的系统。然而,它需要商用 GPU 来执行复杂的计算。为了提高效率,SVO 提取 FAST 特征,然后利用直接法的方式来估计摄像机的姿态和三维结构。

LSD-SLAM 扩展了这项工作,并且可以在大比例尺环境下生成半密集地图。同时能够将三维环境地图实时重构为关键帧的姿态图和对应的半稠密的深度图。
除了基于几何的方法的 SLAM 外,基于深度学习的 SLAM 凭借神经网络强大的学习能力也取得了很大的进步。PoseNet 是最早使用 CNN 端到端估计相机姿态的方法之一。Deep VO 使用 RNN 来建模运动动力学和图像序列之间的关系,ESP-VO 在此基础上增加了位姿估计的不确定性估计。
2. 基于显著性模型的 SLAM 框架
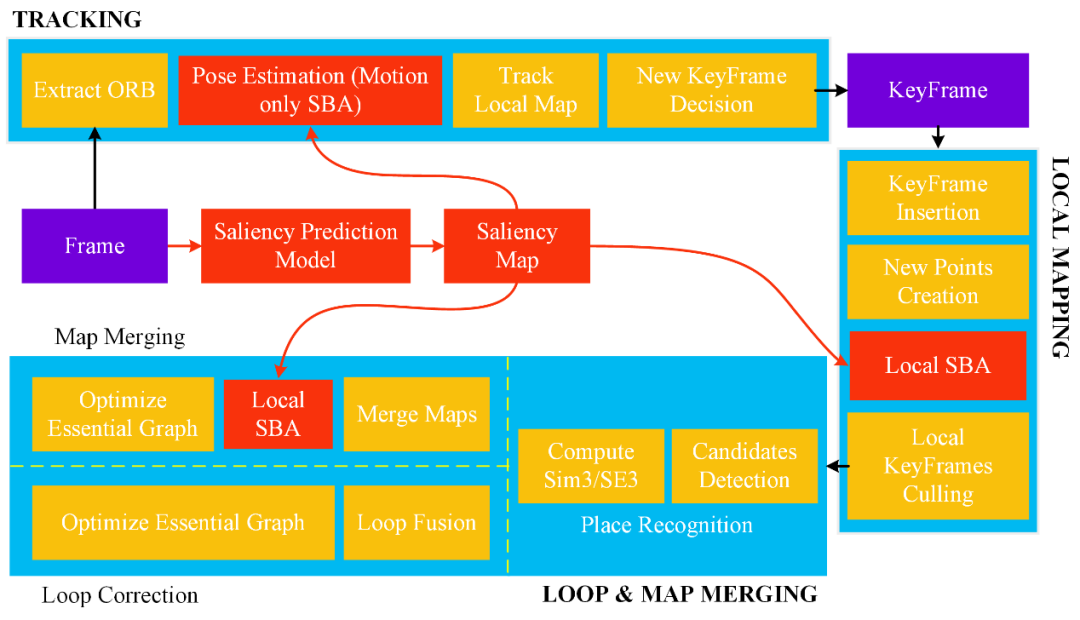
图 | 框架总览
为更好地解决现有 SLAM 框架的问题,作者提出了一个适用于室内和室外环境的 SLAM 框架,它可以应用于各种场景,具有较好的鲁棒性和准确性。
上图为整体框架的简化说明,它包括两个组件:基于几何法的 SLAM 管道和基于深度学习的显著性预测模块。显著性预测模块生成与 SLAM 数据集相对应的显著性图。然后,将显著性图作为输入,帮助 SLAM 选择显著的特征点,以提高定位的准确性和鲁棒性。
视觉显著性是指模仿人类视觉系统,从自然场景中选择出最显著、最感兴趣的区域或点,以便在不同的任务下进行进一步的处理。近年来,有许多基于深度学习的方法来预测自然场景中的显著性区域,并取得了很好的效果。然而,这些显著性预测方法并不能完全描述 SLAM 系统应该关注的特征,原因是这些方法只使用原始的人类注视信息,例如,在驾驶车辆行驶的过程中,人类的注视通常停留在车辆前方的道路上,因为这是车辆行驶的地方。但是,这还不够,因为 SLAM/VO 还需要聚焦在远离图像中心的区域,所以仅仅依靠人眼眼动跟踪器获得的凝视数据,并不能帮助 SLAM 系统捕捉所有这些重要线索。
为解决这一问题,作者通过结合几何信息和语义信息,在 KITTI 数据集的基础上,构造一个显著性数据集 Salient-KITTI 来训练显著性模型,用语义注视代替人类注视。具体来说,作者首先提取图像几何信息如特征点、线和平面等。然后使用语义分割网络 SDC Net 在感兴趣对象周围生成分割掩码。
然后,作者选取了 13 个类别作为 SLAM 应该重点关注的对象(红绿灯、交通标志、道路、建筑物、人行道、停车场、轨道、围栏、桥梁、电线杆、杆群、植被、地形)来过滤几何信息,因为这些类别中的区域通常包含显著的、稳定和鲁棒的特征。如下图,其显示了语义注视和人类注视地面真值的比较。

最后,基于该显著性数据集,作者使用 DI-Net 获得显著性模型,并用它来预测初始显著性图,随后根据图像的深度信息得到最终的显著性图。
为了验证显著性模型的可行性,作者做了三个实验:
a) 1、显著性模型的有效性验证。使用分别在 Saleint-KITTI 数据集和 SALICON 数据集上训练的显著性模型,验证所提出的显著性模型相对于其它显著性模型的有效性。
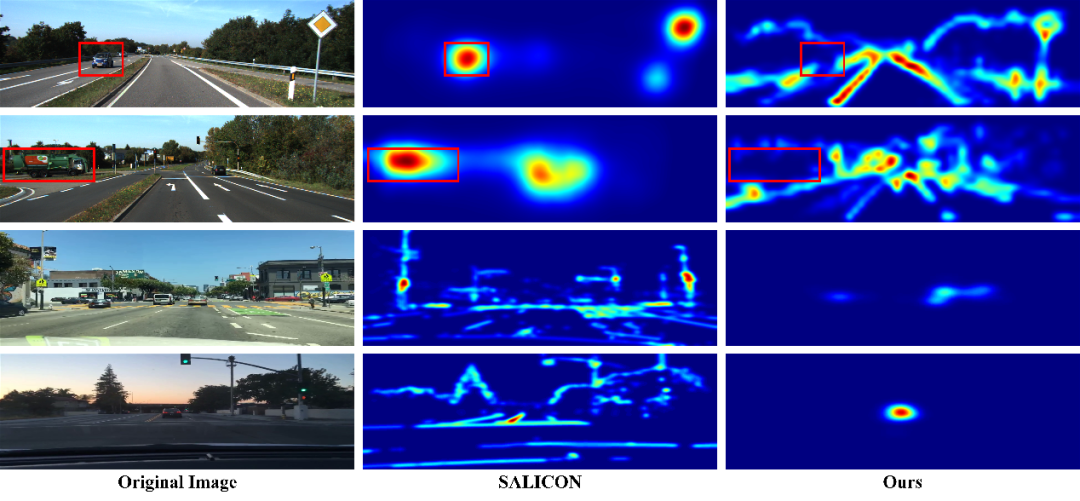
图 | SALICON 和 KITTI 数据集训练的显著性模型的比较
结果显示,对于基于 SALICON 数据集训练的模型,当图像中没有显著对象时,注意力集中在图像的中心,从而忽略了其他重要信息,即我们所说的存在中心偏差。相反,在 Salient-KITTI 数据集上训练的模型可成功地捕捉到这些重要信息。此外,该模型还可以减少动态对象的影响,因此具有显著性值高的点通常是更稳定和鲁棒的点。
2、基于 KITTI 数据集的室外场景验证。在单目和立体视觉配置中,作者提出的系统比 ORB-SLAM3 更精确,因为 SBA 使显著特征点充分发挥其作用。同时,本实验也证明利用显著图可以使算法在姿态估计方面有更多的优势,具体效果如下图所示。
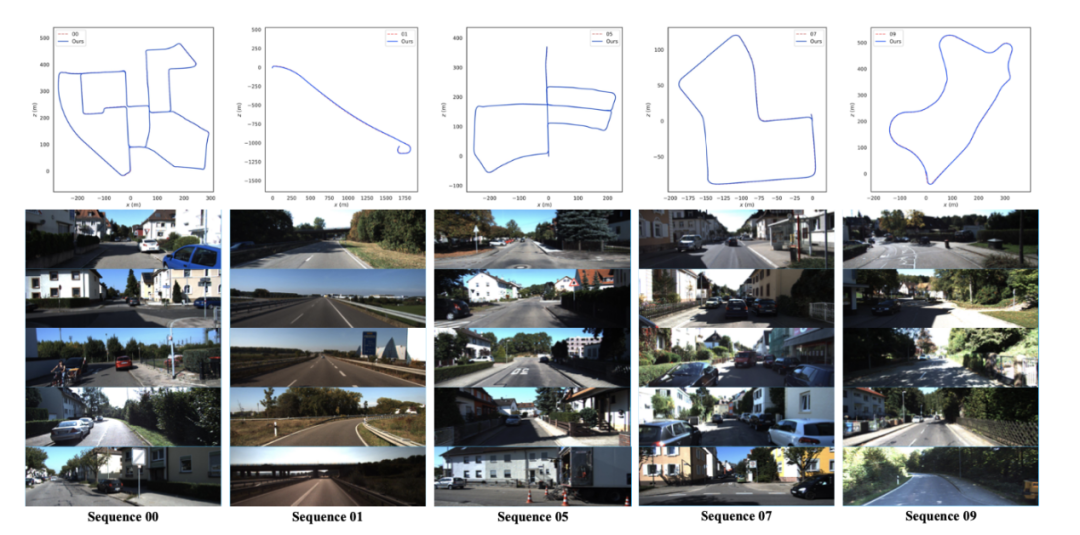
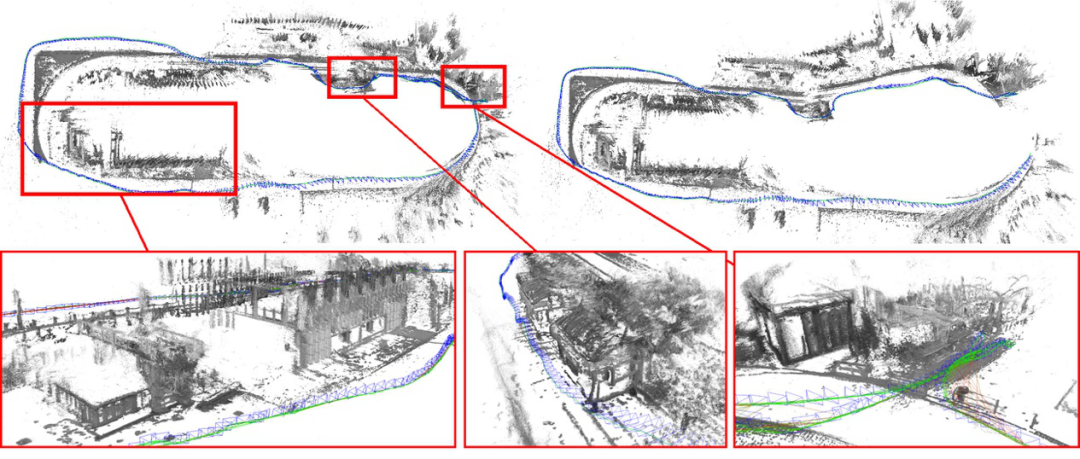
3、基于 EuRoc 数据集的室内场景验证。在第三个实验中,作者将算法与其他最先进的算法进行了比较,如 ORB-SLAM、DSM、DSO、突出 DSO 和 ORB-SLAM3。
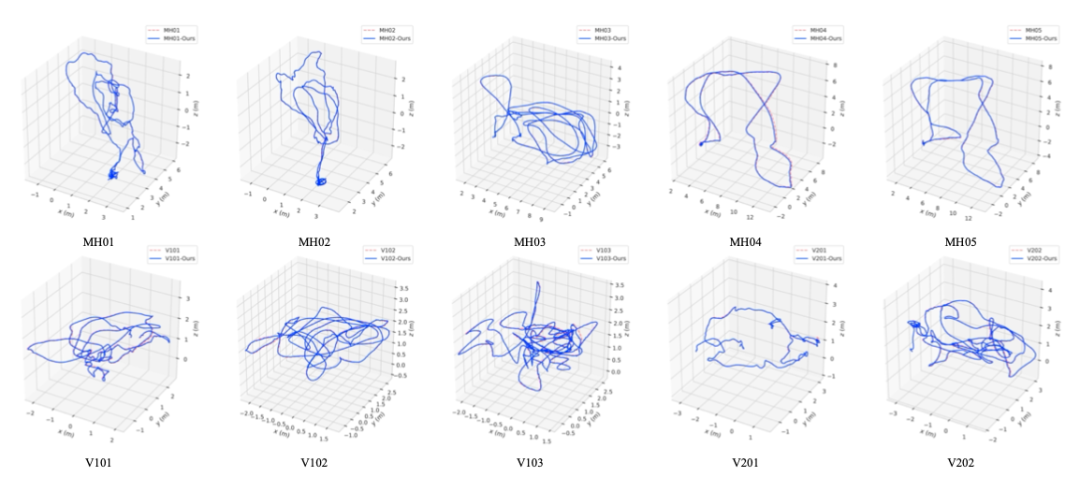
图 | EuRoc 数据集的一些轨迹结果和地面真实情况
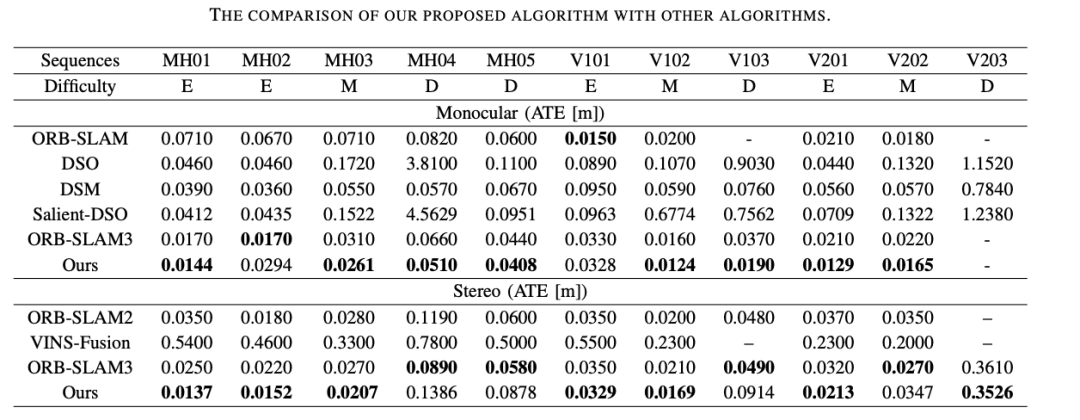
结果显示,在大多数序列中,作者提出的模型在室内和室外环境下都能很好地工作,同时也比文献中的最新技术获得更精确的结果。
王科表示,该研究不仅仅针对自动驾驶,基于图像处理的都可以用,它是一个基础的算法,而非纯应用的提升,只不过最初是在自动驾驶平台做起来的。
而随着 SLAM 技术的不断发展,它们将被应用到越来越多的领域中,小到扫地机器人,大到无人驾驶技术、AR、VR 等,未来将为人类生活带来极大的便利。
责任编辑:lq
-
算法
+关注
关注
23文章
4599浏览量
92621 -
SLAM
+关注
关注
23文章
419浏览量
31783 -
机器人视觉
+关注
关注
0文章
48浏览量
10016
原文标题:重庆大学研发定位与建图技术,可让机器人视觉更智能
文章出处:【微信号:deeptechchina,微信公众号:deeptechchina】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何提升ASR模型的准确性
深度学习模型的鲁棒性优化
鲁棒性在机器学习中的重要性
如何提高系统的鲁棒性
如何维护电流互感器的准确性
如何评估 ChatGPT 输出内容的准确性
如何保证测长机测量的准确性?

倾斜光栅的鲁棒性优化
影响电源纹波测试准确性的因素

基于计算设计的超鲁棒性应变传感器,实现软体机器人的感知和自主性

怎样测试电流探头的准确性以及保证其精准性






 工商网监
工商网监
评论