 提高数据分析的科学性与透明度,用统计学“反转”中心法则
提高数据分析的科学性与透明度,用统计学“反转”中心法则
“对我而言,回答了自己心中的问题或者做出一个新的发现,这种成就感要远高于生活中的其他快乐。”李婧翌对《麻省理工科技评论》中国这样说道。
而她的研究内容在很多人眼里或许稍显枯燥:针对前沿的生物学问题开发新的统计学方法,尤其着重于对大规模基因组和转录组数据进行分析方法的开发。
由于高通量实验技术的发展,生命科学从一个靠观察实验为主的学科逐渐变得更加需要定量化,而这些大规模数据的产生也需要算法才能够进行分析,从而总结出数学规律并用规律来刻画事物的本质。
加州大学洛杉矶分校(UCLA)统计系(已获得终身教职)副教授和博士生导师,生物统计系、人类遗传学系和计算医学系博士生导师李婧翌认为,生命科学作为一个“宏科学”,尽管问题的本质与生命强相关,但研究手段需要各个学科一起合作,计算则是其中非常重要的一部分,大数据也需要有非常适合的挖掘工具,这对于从小对数学与科学有强烈兴趣、并在本科与博士阶段分别接受了生命科学与生物统计学系统教育的李婧翌有强大的吸引。
李婧翌的研究专注于统计学与生命科学的交叉问题,她首创性地使用严格的统计学来分析已发表的转录组学和蛋白组学数据,发现在过往研究中,由于研究人员对测量误差的忽略,转录的重要性被严重低估,该分析挑战了“翻译比转录重要”的观点却支持了之前大量在 mRNA 转录水平的科学发现。因其重要性,李婧翌的研究结果被发表在 Science 杂志并收录于本科教材 Molecular Cell Biology 中。
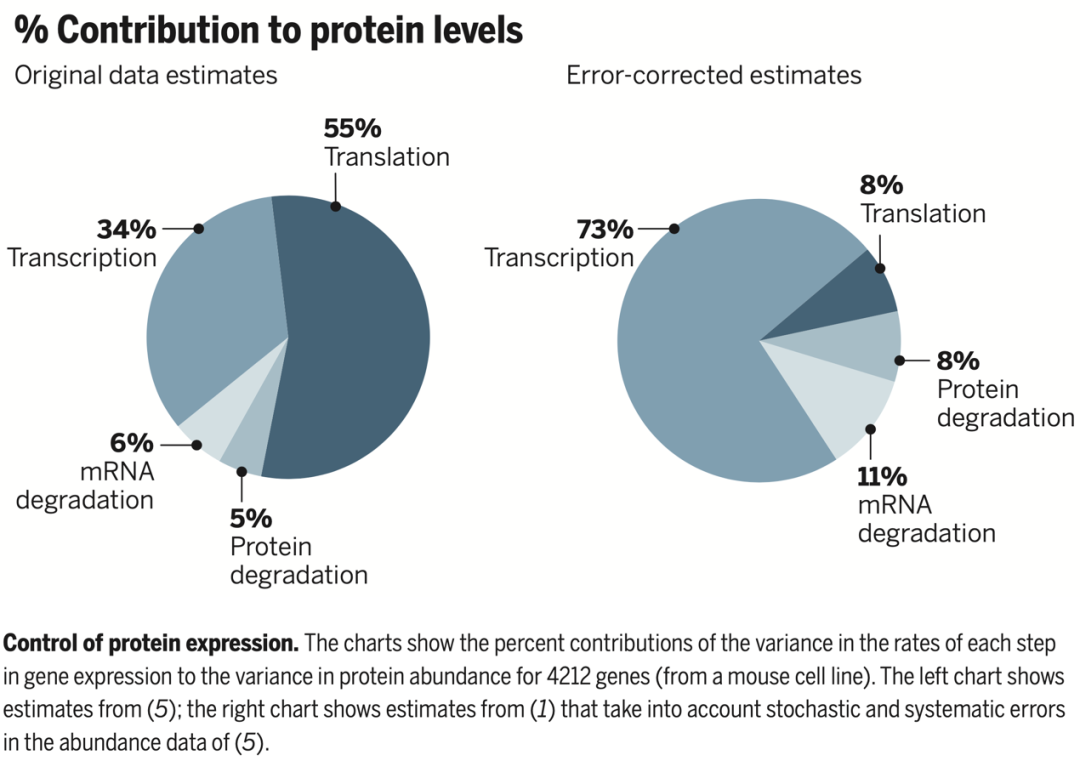
图 | 左图是论文 B.Schwanhäusseretal.,Nature473,337(2011) 中在不考虑实验数据误差的情况下对转录、翻译、mRNA 降解和蛋白质降解这四个步骤对于蛋白质含量的贡献的估计;右图是在校正了实验数据误差之后的估计。(来源:李婧翌的论文 Li et al. (2015). Statistics requantitates the central dogma. Science347(6226):1066-1067.)
此外,李婧翌团队还开发了大量生物信息学工具在组织和单细胞水平上对 mRNA 分子进行全系统测量,并正在开发一项能够寻找到人群亚型中和疾病相关的基因变异的新的统计度量。
凭借上述优异的研究成果,李婧翌成功入选 《麻省理工科技评论》“35 岁以下科技创新 35 人”(Innovators Under 35)2020 年中国区榜单。
图 |《麻省理工科技评论》“35 岁以下科技创新 35 人”2020 年中国区榜单入选者李婧翌
无心插柳,却颠覆固有认知
早在 1958 年,中心转录法则便被提出,它指的是遗传信息被编码在 DNA 中,通过转录会变成 mRNA,再通过翻译的过程变成蛋白质,这是所有有细胞结构的生物所遵循的法则。 在这个过程中,除了转录和翻译生成了 mRNA 和蛋白质这两个步骤,还存在 mRNA 和蛋白质的降解,这四个步骤共同决定了每一个基因所对应的蛋白质到底在我们细胞中存在多少量。不过,此前中心转录法则是一个定性表述,“没有人知道每一步的速率是多少,也没有人知道对最后蛋白质含量的影响有多少。” 在李婧翌博士即将毕业之时,她与合作者 Mark Biggin 博士共同研究中心转录法则的定量工作。偶然的一次机会,李婧翌和合作者发现,2011 年发表在Nature上的一篇文章首次在小鼠的全基因组的基因中进行了 4 项步骤的测量,其得出的结论是每个基因的 mRNA 的含量对于蛋白质含量的预测效果比较差,也就是说一个基因内 mRNA 的高或低并不太能代表它的蛋白质含量的高或低。 “这在当时是个非常让人震惊的结论。因为我们有很多实验手段可以用来研究 mRNA,但是研究蛋白质相对困难很多,所以大量生物学的发现成果都围绕 mRNA 的含量水平。如果这篇文章的结果为真,那么之前很多 mRNA 的结果可能都没有什么意义了。”李婧翌解释道。 当李婧翌与合作伙伴看到这篇文章时,他们观察到这项工作是将高通量质谱转化为蛋白质含量,但在转化过程中,它的标准实际上只基于高表达蛋白,并假设同样的转换方式也适用于低表达蛋白,由此导致了研究里面很多低表达蛋白的表达指征是很不准的,也就意味着高通量蛋白质测量很有可能存在误差。 为了解决这一疑惑,李婧翌将实验误差考虑进建模后发现,实际上 mRNA 和蛋白质含量的相关性比 Nature 的文章报道的要高很多,转录的重要性被严重低估。这项“无心插柳”的研究结果被发表在 Science 杂志并收录于本科教材 Molecular Cell Biology 中。 李婧翌对《麻省理工科技评论》中国回忆道:“我觉得很有趣的一点是,我们将很基本的统计方法用到了正确的问题上,从而发现了非常意想不到的结果。这也说明了考虑数据测量的随机性和数据噪音对科学结论十分重要。”这一年,李婧翌还不到 30 岁。科研与教育同样重要 作为一个青年科学家,李婧翌认为,保持对未知问题的好奇心,用研究拓宽人类的知识边界,是支撑她科研工作的重要推动力。 作为一个科研人员,李婧翌认为目前的统计分析还远远谈不上科学,“如果一个分析人员在写研究报告时没有记录分析的每一步,而只是简略地记录一个结果,那最终结果就不太透明,并且可能也不能被重复,可信度就要大打折扣。” 此外,李婧翌提到,如果要将最新研究的统计学方法发表在比较好的学术杂志上,通常情况下做的越复杂越容易发表,这就导致统计学领域出现一个通病:很多统计方法都比较像“黑箱”,它们过于复杂,也没有给实际应用的人员讲授清楚优缺点到底在哪里。
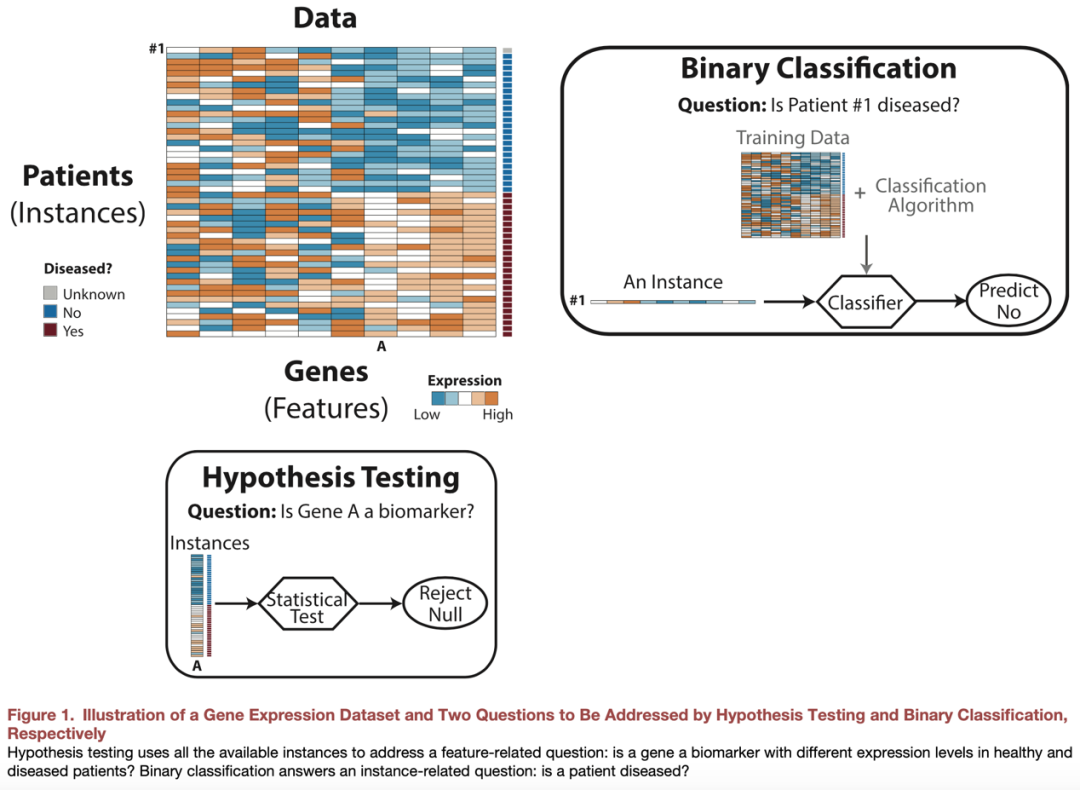
图 | 对于同样的一套多个病人样本中的基因表达数据,病人是观测值,而基因是特征。大部分的病人已知得病或未得病。如果研究问题是:基因A是否为一个有效的疾病标志物,那么假设检验是合适的统计方法。而如果研究问题是:1号病人是否得病,那么二元分类是合适的统计方法。(来源:李婧翌的论文Li et al. (2020). Statistical hypothesis testing versus machine-learning binary classification: distinctions and guidelines. Patterns 1(7):110115.)
作为一个有交叉学科背景的研究人员,李婧翌充分利用了这一点:能够更好地让生命科学领域的数据分析人员去理解现有的一些经典方法的优缺点和适用范围,同时,李婧翌自己发展新方法也将以此为目标,创造出更透明、更稳定的统计学方法。举例而言,李婧翌在最近发表的一篇文章中就尝试对两种常用但经常被混淆的统计方法:假设检验和二元分类,进行解释并阐述这两种方法各自适用的数据分析问题。譬如对致癌基因和抑癌基因的预测问题,李婧翌解释了为什么基于现有的大数据,二元分类是一个更加适用的统计方法。 作为教师,李婧翌致力于将统计方法开发和实际应用的重要性更紧密的结合。 李婧翌认为,无论中美,目前统计学的基础教育中都有很多过时的教学内容,因为很多计算都已经可以依靠计算机的程序包来进行自动化运算。统计学教育更重要的应该是去教授学生为什么需要统计学,数据背后的随机性应该怎么去理解,以及数据分析到底想解决什么问题,“我觉得这些其实是统计教育需要改变的的东西,我希望我能够发挥一些作用。”
责任编辑:lq
-
自动化
+关注
关注
29文章
5654浏览量
79801 -
统计
+关注
关注
1文章
19浏览量
13538 -
数据分析
+关注
关注
2文章
1462浏览量
34203
原文标题:提高数据分析的科学性与透明度,UCLA教授用统计学“反转”中心法则
文章出处:【微信号:deeptechchina,微信公众号:deeptechchina】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI模型思维链功能升级,提升透明度与可信度
Mathematica 在数据分析中的应用
首个科学计算基座大模型BBT-Neutron开源,助力突破大科学装置数据分析瓶颈
葡萄酒俱乐部计划部署RFID技术以提高供应链的透明度
raid 在大数据分析中的应用
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
动态代理IP的匿名性和透明度,为主要考虑关键!






 工商网监
工商网监
评论