 深度过滤电子邮件里的“垃圾”的AI算法
深度过滤电子邮件里的“垃圾”的AI算法
目前,全球每天发出的3000亿封电子邮件中,至少有半数属于垃圾邮件。邮件服务供应商的首要任务自然是过滤掉这些垃圾邮件,以确保用户能够快速找到真正具有价值的重要邮件。
但垃圾邮件的检测本身相当复杂。首先,垃圾邮件与正常邮件之间的界限非常模糊,而且评判标准往往会随时间推移而有所变化。截至目前,各家邮件服务商普遍采用自动化垃圾邮件检测方法,而机器学习已经成为其中最有效、也最受青睐的核心选项。虽然我们或多或少还是会看到垃圾邮件,但在机器学习算法的强大支持之下,大多数垃圾邮件已经被从收件箱中直接清除。
那么,机器学习技术是怎么确定哪些是垃圾邮件、而哪些属于正常邮件的?在本文中,我们将具体聊聊其中的工作原理。
挑战所在
垃圾邮件有着多种不同风格。有些只是些市场调研的信息,只是想引诱收件人打开邮件或者传播虚假信息。但也有一些属于伪造型邮件,目标是引导收件者点击恶意链接或下载恶意软件。
但二者的共同点在于,它们都跟收件人的实际需求没有半毛钱关系。垃圾邮件检测算法需要找到可靠的垃圾邮件过滤方法,在屏蔽不必要内容的同时,避免清理掉那些用户希望接收并查看的真实邮件。此外,算法本身还得持续适应新的趋势性动态——例如由新冠疫情引发的群体恐慌、选举消息以及加密货币社区的迅速升温等等。
静态规则适合解决这类需求。例如,如果邮件包含大量抄送方、正文部分极短以及主题部分全部大写,那么其很可能属于垃圾邮件。同样,某些发送方的域名可能已经被列入垃圾邮件黑名单。但在大多数情况下,垃圾邮件检测主要还是依赖于对邮件内容的具体分析。
朴素贝叶斯机器学习
机器学习算法使用统计模型对数据进行分类。在检测垃圾邮件这一使用场景下,经过训练的机器学习模型必须能够根据邮件中的词汇顺序,判断其可能属于垃圾邮件抑或是正常邮件。
不同的机器学习算法都具备一定的垃圾邮件检测能力,但目前最受关注的仍然是“朴素贝叶斯”算法。顾名思义,朴素贝叶斯算法以“贝叶斯定理”为基础,即基于先验知识对事件的概率做出描述。
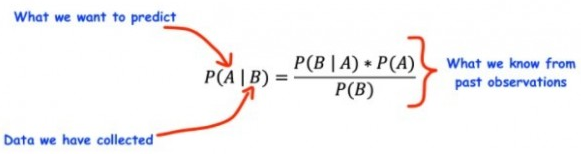
之所以被冠名以“朴素”,是因为它首先假设观测的特征只独立存在。例如,如果使用朴素贝叶斯机器学习方法来预测是否会下雨,那么只需要湿度及温度等少数特征,即可对是否降雨这个事件做出预测。
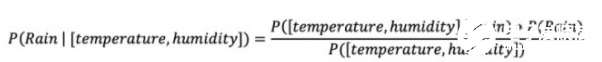
在检测垃圾邮件时,情况无疑更为复杂。我们的目标变量为给定电子邮件属于“垃圾”或者“非垃圾”。其特征则为电子邮件正文中包含的单词或单词组合。简而言之,我们希望根据文本内容判断出当前邮件属于垃圾邮件的可能性。
这里需要强调的是,检测垃圾邮件时使用的各项特征不一定彼此独立。例如,我们可以将词汇“烤”、“奶酪”和“三明治”结合起来,其在邮件语境下是否连续存在将表达出完全不同的含义。另一个更明确的例子就是“不”和“好玩”,独立与非独立分析将带来彻底相反的结论。但好消息是,虽然文本数据内的特征独立性往往非常复杂,但只要正确加以配置,朴素贝叶斯分类器同样能够有效处理大部分自然语言处理任务。
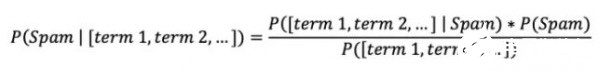
关于数据
垃圾邮件检测属于有监督机器学习问题。这意味着您需要为机器学习模型提供大量垃圾邮件与正常消息示例,帮助其从中找出相应模式以准确将二者区分开来。
大多数电子邮件服务商都拥有自己的标记邮件数据集。例如,每当您在Gmail账户内将一封电子邮件标记为垃圾邮件,谷歌方面就会使用这部分数据训练自己的机器学习算法。(请注意,谷歌使用的垃圾邮件检测算法要比本文示例复杂得多,而且他们还拥有一套用于防止「报告垃圾邮件」功能遭到滥用的完善机制。)

目前也有不少值得一试的开源数据集,例如加利福尼亚大学欧文分校的垃圾邮件数据库数据集以及安然垃圾邮件数据集。但请注意,这些数据集仅供教育及测试使用,对于生产级机器学习模型的创建没有太大实际意义。
自行托管电子邮件服务器的供应商可以创建起专门的数据集,并根据具体行业及用语对机器学习模型加以调整。例如,金融服务类企业的数据集在内容上将与建筑类企业存在巨大差异。
训练机器学习模型
尽管近年来,自然语言处理技术取得了令人振奋的进步,但人工智能算法本身仍然无法像人类那样顺畅理解语言内容。
因此,开发垃圾邮件检测类机器学习模型的一大关键步骤,在于准备数据以进行统计处理。在训练朴素贝叶斯分类器之前,必须通过特定步骤整理出垃圾邮件与正常邮件的语料库。
考虑一套包含以下语句的数据集:
Steve想为聚会买点烤芝士三明治
Sally正为晚饭烧烤鸡肉
我买了奶油芝士做蛋糕
在训练模型以及随后对新数据进行预测时,我们首先需要对文本数据进行“令牌化”,而后将其添加到机器学习算法当中。在本质上,令牌化是指将文本数据拆分成较小的部分。如果您将上述数据集按用词进行拆分,那么将获得以下词汇。请注意,每个词只出现一次。
Steve、想为、聚会、买、烤、芝士、三明治、Sally、正、晚饭、烧烤、鸡肉、我、买了、奶油、蛋糕
我们可以删除掉那些垃圾邮件和正常邮件中都会出现的词汇,因为这些词汇没法帮我们区分出邮件本身的性质。这些被称为“停用词”,常见的例子包括这、那、是、要、某等。在以上数据集中,删除停用词之后,我们的词汇量将快速缩减为5个。
我们还可以使用其他技术,例如“词干提取”与“词条化”等,借此将词汇转换为更基础的形式。继续来看我们的示例数据集,其中的“买了”和“买”有着相同的词根,“烤”和“烧烤”也有相同的词根。通过这样的处理,我们可以进一步简化机器模型。
在某些情况下,大家还可以考虑使用双词(包含两个词的令牌)、三词(包含三个词的令牌)或者更长的N字令牌。例如,使用双词形式对上述数据集进行标记,将得到“芝士蛋糕”表达;三词形式则会带来“烤芝士三明治”表达。
在数据处理完成之后,您将获得一份术语表,这些术语定义了机器学习模型中的各项特征。接下来,您需要确定哪些词汇或者词汇序列(如果使用N词表达)与垃圾邮件及正常邮件相关。
在训练数据集上训练机器学习模型时,需要根据不同术语在垃圾邮件及正常邮件中出现的次数为其分配权重。例如,如果“赢大奖”属于其中一项特征,而且只出现在垃圾邮件当中,那么任何具有此特征的邮件都很可能被归类为垃圾邮件。与之对应,如果“重要会议”只出现在正常电子邮件中,那么任何具有此特征的邮件都很可能被归类为正常邮件。
在数据处理完成,并对各特征分配了权重之后,您的机器学习模型即可过滤垃圾邮件。在收到一封新邮件之后,其中的文本将接受标记并按照贝叶斯公式运行。邮件正文中的每个术语均将乘以其权重,权重的总和即代表该电子邮件属于垃圾邮件的可能性。(实际计算过程要更为复杂,但这里为了简便起见,我们直接求取所有权重之和。)
使用机器学习技术实现高级垃圾邮件检测
听起来很简单,但朴素贝叶斯机器学习算法在处理大部分文本分类任务(包括垃圾邮件检测)时都取得了不错的效果。
但它仍然不够完美,这是肯定的。
与其他机器学习算法一样,朴素贝叶斯算法无法理解语言的上下文,只能依靠词汇之间的统计关系来判断一段文本是否属于某个类别。这意味着,如果发件人在邮件末尾添加一些符合正常邮件条件的词汇,或者将符合垃圾邮件特征的某些术语替换为其他同义词或相关词,那么朴素贝叶斯算法很可能将垃圾邮件错误判断为正常邮件。
朴素贝叶斯方法当然不是唯一能够检测出垃圾邮件的机器学习算法。其他流行的算法选项还包括递归神经网络(RNN)与transformers,它们都能高效处理电子邮件及文本消息等有序数据。
最后需要注意的是,垃圾邮件检测一直在不断发展。就在开发者利用AI乃至其他技术检测并过滤电子邮件中的有害消息时,垃圾邮件发送者也在寻求新的方法,希望骗过检测系统、将垃圾邮件发送到收件者手中。也正因为如此,电子邮件服务商才需要持续运用用户的数据改进并更新其垃圾邮件检测器。
责编AJX
-
算法
+关注
关注
23文章
4645浏览量
93682 -
AI
+关注
关注
87文章
32370浏览量
271475 -
电子邮件
+关注
关注
0文章
110浏览量
15415
发布评论请先 登录
相关推荐
代价敏感支持向量机在垃圾邮件过滤中的应用
基于Bayes的一种改良垃圾邮件过滤模型
垃圾邮件(Spam)与邮件过滤技术
电子邮件使用模拟实验
病毒和蠕虫如何在电子邮件中传播?
垃圾邮件详解
CCERT中文垃圾邮件过滤解决方案
如何向您选择的某人发送电子邮件





 工商网监
工商网监
评论