 如何使用Python+OpenCV为人脸生成口罩?
如何使用Python+OpenCV为人脸生成口罩?
口罩已经被证明是防止COVID-19传播的最好的防御措施之一,然而,这也导致了基于面部特征(包括鼻子、嘴和下巴线)的面部识别算法的失效。 在全球有传染病之前,面部识别系统通过对检测到的不同面部特征进行比较测量来验证两幅图像中的人脸。当一个人的鼻子、嘴和脸颊上戴上口罩,大大减少了通常用来识别他/她的身份的信息。 将需要重新训练或重新设计有效的识别系统,以识别受管制地区的口罩脸。为了做到这一点,需要一个大的口罩数据集来训练深度学习模型,以检测戴口罩的人和不戴口罩的人。 目前,可用于训练和评估人脸识别系统的图像数据集是有限的。据报道,美国国家标准与技术研究所(NIST)的研究通过将口罩(各种颜色、大小和位置)叠加在没有带口罩人脸的图像上来解决这个问题。
这篇文章试图用OpenCV和dlib库来实现这个过程,在这里我们综合生成5种类型的口罩来绘制人脸图像。图1显示了生成的5种口罩类型。
安装所需的软件包
使用Python3.7创建一个新的虚拟环境并安装依赖项。所需的库如下:
#requirements_facemask.txt numpy == 1.18.5 pip == 20.2.2 imutils == 0.5.3 python 》=3.7 dlib == 19.21.0 cmake == 3.18.0 opencv-python == 4.4.0 由于此脚本需要dlib库,因此在开始运行该脚本之前需要安装dlib,你可以通过以下链接了解如何使用Python绑定安装dlib:https://www.pyimagesearch.com/2017/03/27/how-to-install-dlib/ Dlib是一个高级的机器学习库,它是为解决复杂的现实世界问题而创建的。这个库是用C++编程语言创建的,它可以使用C/C++、Python和java等语言。
导入库
我们从导入所需的库开始:OpenCV、dlib、numpy、os和imutils。
# 必要的导入 import cv2 import dlib import numpy as np import os import imutils 下一步是设置口罩的颜色,并设置要从中导入图像的目录和路径,OpenCV的颜色空间按BGR顺序而不是RGB。# 设置目录 os.chdir(‘PATH_TO_DIR’) path = ‘IMAGE_PATH’ # 初始化颜色 [color_type] = (Blue, Green, Red) color_blue = (239,207,137) color_cyan = (255,200,0) color_black = (0, 0, 0) 下面的链接让你可以立即从视觉上探索颜色,它可以用于将颜色从十六进制转换为RGB,反之亦然:https://www.rgbtohex.net/rgb/
图像预处理
接下来,我们通过OpenCV加载我们的输入图像,然后通过调整大小使其具有500像素的宽度并将其转换为灰度来预处理图像。
# 加载图像并调整大小,将其转换为灰度 img= cv2.imread(‘image_path’) img = imutils.resize(img, width = 500) gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
使用dlib、OpenCV和Python检测和提取人脸关键点
为了覆盖口罩,我们需要进行人脸检测,有许多方法可用于执行此任务我们可以使用OpenCV内置的Haar Cascade XML文件,甚至TensorFlow或使用Keras。在这篇文章中,我们使用的是dlib的人脸检测器。 dlib中的正面人脸检测器是基于方向梯度直方图(HOG)和线性SVM的。
我们使用dlib的正面人脸检测来首先检测人脸,然后使用面部标志点预测器dlib.shape_predictor检测人脸关键点。
人脸关键点检测被定义为检测脸上的关键标志点并跟踪它们(对由于头部运动和面部表情而导致的刚性和非刚性面部变形具有鲁棒性)[来源]
什么是人脸关键点?
人脸关键点是用于定位和表示面部的显著区域,如眼睛、眉毛、鼻子、下颚线、嘴巴等,应用于人脸对齐、头部姿态估计、换脸、眨眼检测、困倦检测等领域。 在人脸关键点下,利用形状预测方法对人脸上重要的面部结构进行检测是非常必要的。面部标志点检测包括两个步骤:
定位图像中检测到的人脸。
面部关键点的检测
如前所述,我们可以通过多种方式执行人脸检测,但每种方法都试图定位和标记以下面部区域:
鼻子
下颚线
左眼和右眼
左右眉
嘴
在这篇文章中,我们使用了基于深度学习的人脸定位算法,该算法还用于图像中人脸的检测。我们将通过某种方法获得面边界框,其中我们分别使用图像中人脸的(x,y)坐标。一旦人脸区域被检测到并被限定,我们进入下一步检测脸部区域中的关键点。 我们正在使用的dlib库中包含的预训练人脸关键点探测器,这是Kazemi和Sullivan(2014)用回归树集合论文实现的1毫秒人脸对齐算法,其中估计了映射到人脸结构的68个(x,y)坐标的位置。我们可以使用下图显示68个坐标或点的索引:

从图3可以通过不同的点集[起点,终点]来评估面部特征的位置:
左眼:点[42,47]
嘴:点[48,67]
左眉:点[22,26]
鼻子:点[27,34]
右眉:点[17,21]
右眼:点[36,41]
下颚线:点[0,16]
请注意,标志点从0开始 dlib人脸关键点检测器就是在这个数据集上训练的:https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
人脸检测与人脸关键点检测
下一步是对dlib的预训练人脸检测器进行初始化,该检测器是基于Histogram of Oriented Gradients + Linear SVM method](https://pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/) 。此检测器会进行图像中人脸边界框的检测。 检测器的第一个参数是我们的灰度图像。(此方法也适用于彩色图像)。 第二个参数是在应用检测器之前对图像进行放大时要应用的图像金字塔层的数量。在人脸检测之前增加输入图像的分辨率的好处是可以让我们在图像中检测到更多的人脸,但其缺点是,输入图像越大,计算开销越大,检测速度越慢。 我们还打印出边界框的坐标以及检测到的人脸数。我们也可以使用cv2在检测到的面部周围使用for循环绘制边界框。
# 初始化dlib的人脸检测器 detector = dlib.get_frontal_face_detector() “”“ 在灰度图像中检测人脸并创建一个对象-存储边界矩形的坐标列表 第二个参数中的“1”表示应该向上采样图像1次。 这会使图像变得更大,并允许我们检测更多的面孔 ”“” faces = detector(gray, 1) # 打印边界矩形的坐标 print(faces) print(“Number of faces detected: ”, len(faces)) “”“ # 使用for循环来提取特定坐标(x1,x2,y1,y2) for face in faces: x1 = face.left() y1 = face.top() x2 = face.right() y2 = face.bottom() # 在检测到的脸部周围画一个矩形 cv2.rectangle(img, (x1,y1), (x2,y2),(0,255,0),3) cv2.imshow(”image“, img) cv2.waitKey(0) cv2.destroyAllWindows() ”“” 为了检测人脸关键点,我们需要从dlib库下载人脸关键点预测器dlib.shape_predictor。 我们的预测方法需要一个名为“shape_predictor_68_face_landmarks.dat”的文件,可从以下链接
需要强调的是,这个模型文件是专为dlib的HOG人脸检测器设计的,不应该用于dlib的基于CNN的人脸检测器,原因是它期望人脸检测器的边界框按照dlib的HOG人脸检测器的方式对齐。 当与另一个产生不同对齐框的人脸检测器(如基于CNN的mmod_human_face_detector.dat )一起使用时,结果不会很好。# 文件路径 p = “shape_predictor_68_face_landmarks.dat” # 初始化dlib的预测器 predictor = dlib.shape_predictor(p) # 使用预测器获取外形 for face in faces: landmarks = predictor(gray, face) # for n in range(0,68): # x = landmarks.part(n).x # y = landmarks.part(n).y # img_landmark = cv2.circle(img, (x, y), 4, (0, 0, 255), -1) 下载检测器后,我们可以初始化检测器,以便在输入图像中检测到的每个人脸上检测到人脸关键点。 一旦检测到人脸关键点,我们就可以开始“绘图”了,通过使用OpenCV中的绘图功能连接所需的点,将口罩覆盖在脸上:https://docs.opencv.org/master/dc/da5/tutorial_py_drawing_functions.html
Dlib口罩方法
下面的步骤包括识别绘制不同类型口罩所需的点。我们复制的口罩类型由NIST研究报告附录A中提到的不同点集定义:https://doi.org/10.6028/NIST.IR.8311。视觉效果见图。
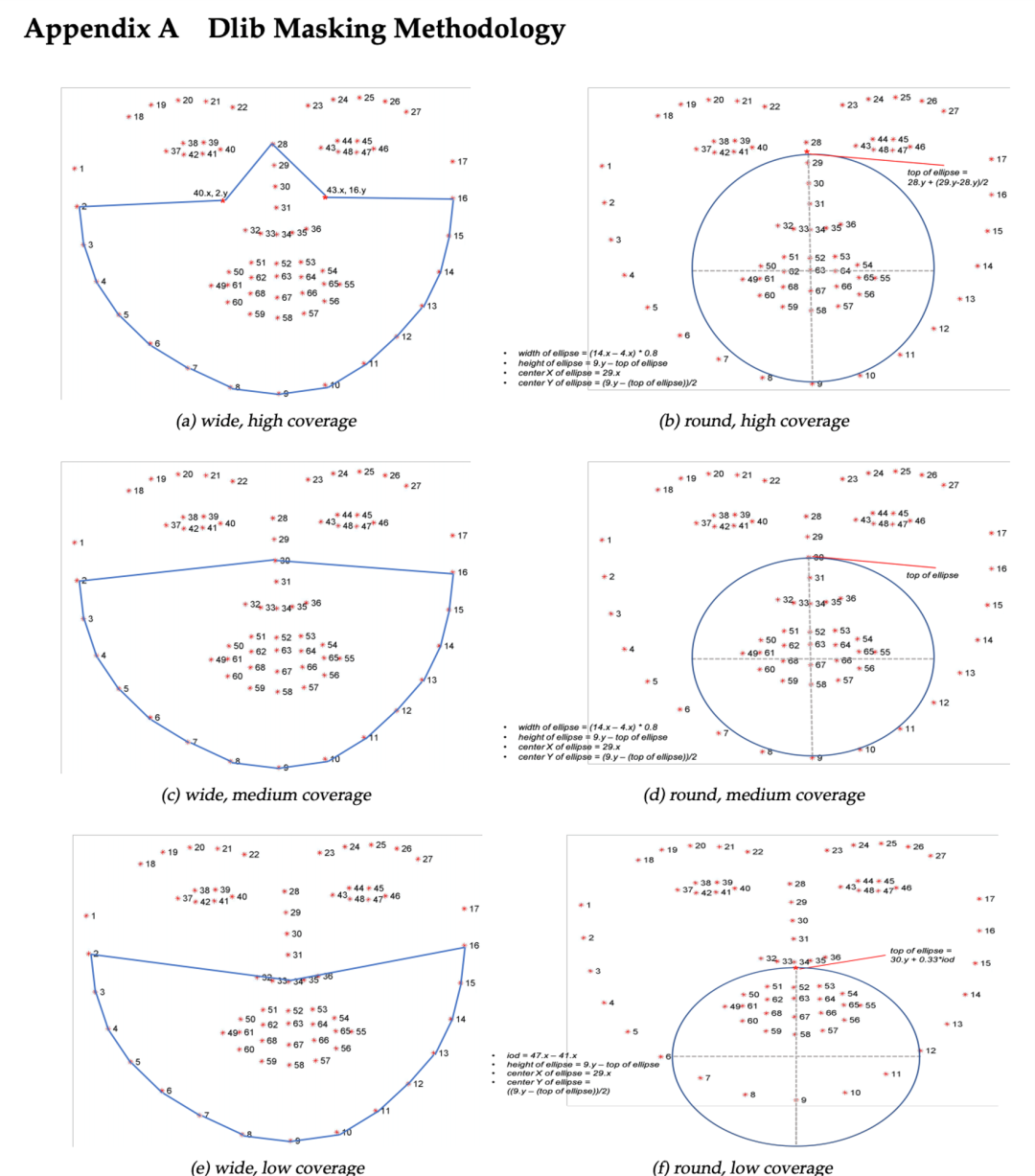
我们将通过连接附录A中定义的标志点来定义口罩的形状。例如,为了形成宽覆盖和中覆盖口罩,我们将用29点的标志点坐标连接(绘制)下颚线[0,16]的标志点。 可以使用OpenCV中椭圆和其他三种规则形状函数绘制口罩轮廓。然后我们可以使用cv2.fillpoly函数将绘制的口罩填充颜色。
points = [] for i in range(1, 16): point = [landmarks.part(i).x, landmarks.part(i).y] points.append(point) # print(points) # 宽,高覆盖口罩 mask_a = [((landmarks.part(42).x), (landmarks.part(15).y)), ((landmarks.part(27).x), (landmarks.part(27).y)), ((landmarks.part(39).x), (landmarks.part(1).y))] # 宽,中覆盖口罩 mask_c = [((landmarks.part(29).x), (landmarks.part(29).y))] # 宽、低覆盖口罩 mask_e = [((landmarks.part(35).x), (landmarks.part(35).y)), ((landmarks.part(34).x), (landmarks.part(34).y)), ((landmarks.part(33).x), (landmarks.part(33).y)), ((landmarks.part(32).x), (landmarks.part(32).y)), ((landmarks.part(31).x), (landmarks.part(31).y))] fmask_a = points + mask_a fmask_c = points + mask_c fmask_e = points + mask_e # mask_type = {1: fmask_a, 2: fmask_c, 3: fmask_e} # mask_type[choice2] # 使用Python OpenCV - cv2.polylines()方法为[mask_type]绘制口罩轮廓: # fmask_a = wide, high coverage mask, # fmask_c = wide, medium coverage mask, # fmask_e = wide, low coverage mask fmask_a = np.array(fmask_a, dtype=np.int32) fmask_c = np.array(fmask_c, dtype=np.int32) fmask_e = np.array(fmask_e, dtype=np.int32) mask_type = {1: fmask_a, 2: fmask_c, 3: fmask_e} mask_type[choice2] # 更改参数[mask_type]和color_type用于各种组合 img2 = cv2.polylines(img, [mask_type[choice2]], True, choice1, thickness=2, lineType=cv2.LINE_8) # 使用Python OpenCV - cv2.fillPoly()
方法填充口罩 # 更改参数[mask_type]和color_type用于各种组合 img3 = cv2.fillPoly(img2, [mask_type[choice2]], choice1, lineType=cv2.LINE_AA) # cv2.imshow(“image with mask outline”, img2) cv2.imshow(“image with mask”, img3) # 为测试保存输出文件 outputNameofImage = “output/imagetest.jpg” print(“Saving output image to”, outputNameofImage) cv2.imwrite(outputNameofImage, img3) points = [] for i in range(1, 16): point = [landmarks.part(i).x, landmarks.part(i).y] points.append(point) # print(points) # 椭圆参数为高,圆形是覆盖口罩 top_ellipse = landmarks.part(27).y + (landmarks.part(28).y - landmarks.part(27).y) / 2 centre_x = landmarks.part(28).x centre_y = landmarks.part(8).y - ((landmarks.part(8).y - (top_ellipse)) / 2) # 椭圆高度 axis_major = (landmarks.part(8).y - top_ellipse) / 2 # 椭圆宽度 axis_minor = ((landmarks.part(13).x - landmarks.part(3).x) * 0.8) / 2 centre_x = int(round(centre_x)) centre_y = int(round(centre_y)) axis_major = int(round(axis_major)) axis_minor = int(round(axis_minor)) centre = (centre_x, centre_y) axes = (axis_major, axis_minor) # 使用Python OpenCV - cv2.ellipse()
方法绘制口罩轮廓 # 更改最后一个参数- line thickness和color_type为各种组合 img_2 = cv2.ellipse(img, centre, axes, 0, 0, 360, color_type, thickness=2) # 使用Python OpenCV - cv2.ellipse()方法绘制口罩轮廓 # 更改最后一个参数-line thickness为负数用于填充,color_type用于各种组合 img_3 = cv2.ellipse(img, centre, axes, 0, 0, 360, color_type, thickness=-1) # cv2.imshow(“image with mask outline”, img_2) cv2.imshow(“image with mask”, img_3) 在图像检测开始之前,用户可以选择预先确定口罩的颜色和类型。我们预先选择了两种颜色的口罩-蓝色和黑色# 使用input()函数根据用户需求获取口罩类型和口罩颜色 choice1 = input(“Please select the choice of mask color Enter 1 for blue Enter 2 for black: ”) choice1 = int(choice1) if choice1 == 1: choice1 = color_blue print(‘You selected mask color = blue’) elif choice1 == 2: choice1 = color_black print(‘You selected mask color = black’) else: print(“invalid selection, please select again.”) input(“Please select the choice of mask color Enter 1 for blue Enter 2 for black : ”) choice2 = input(“Please enter choice of mask type coverage Enter 1 for high Enter 2 for medium Enter 3 for low : ”) choice2 = int(choice2) if choice2 == 1: # choice2 = fmask_a print(f‘You chosen wide, high coverage mask’) elif choice2 == 2: # choice2 = fmask_c print(f‘You chosen wide, medium coverage mask’) elif choice2 == 3: # choice2 = fmask_e print(f‘You chosen wide, low coverage mask’) else: print(“invalid selection, please select again.”) input(“Please enter choice of mask type coverage Enter 1 for high Enter 2 for medium Enter 3 for low : ”) # print(choice2)
结果
图5显示了原始输入图像(Barack Obama的图像)与使用脚本生成了口罩的输出图像之间的比较。我们也可以在人群镜头使用这个脚本。如图6所示,在著名的Ellen‘s wefie拍摄中,在检测到的人脸上叠加口罩的结果。 我们能够成功地复制生成5种不同类型的口罩的过程(详见附录A),这些口罩可以使用dlib和OpenCV叠加在未带口罩的人脸的图像上。 图7到图9显示了在不直接看相机的脸上的更多示例。
结论
该脚本能够在检测到的人脸上生成合成口罩脸,输出图像可用于测试或验证其他面向应用的ML网络,如室内考勤系统的人脸识别、口罩检测等。
原文标题:使用Python+OpenCV+dlib为人脸生成口罩
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
OpenCV
+关注
关注
31文章
635浏览量
41355 -
python
+关注
关注
56文章
4797浏览量
84694
原文标题:使用Python+OpenCV+dlib为人脸生成口罩
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用Python+OpenCV处理图片
【AI实战项目】基于OpenCV的“颜色识别项目”完整操作过程

RK3568 + OpenCV 会碰撞出什么火花?案例详解:2-1 基于OpenCV的画线实验
一个月速成python+OpenCV图像处理

《DNK210使用指南 -CanMV版 V1.0》第四十二章 人脸口罩佩戴检测实验
如何用OpenCV的相机捕捉视频进行人脸检测--基于米尔NXP i.MX93开发板
基于OPENCV的相机捕捉视频进行人脸检测--米尔NXP i.MX93开发板

opencv-python和opencv一样吗
基于Python的深度学习人脸识别方法
基于OpenCV的人脸识别系统设计
人脸检测模型的精确度怎么算
口罩佩戴检测算法







 工商网监
工商网监
评论