 如何使用Python+OpenCV+yolov5实现行人目标检测?
如何使用Python+OpenCV+yolov5实现行人目标检测?
目标检测支持许多视觉任务,如实例分割、姿态估计、跟踪和动作识别,这些计算机视觉任务在监控、自动驾驶和视觉答疑等领域有着广泛的应用。随着这种广泛的实际应用,目标检测自然成为一个活跃的研究领域。 我们在Fynd的研究团队一直在训练一个行人检测模型来支持我们的目标跟踪模型。在本文中,我们将介绍如何选择一个模型架构,创建一个数据集,并为我们的特定用例进行行人检测模型的训练。
什么是目标检测
目标检测是一种计算机视觉技术,它允许我们识别和定位图像或视频中的物体。目标检测可以理解为两部分,目标定位和目标分类。定位可以理解为预测对象在图像中的确切位置(边界框),而分类则是定义它属于哪个类(人/车/狗等)。
目标检测方法
解决目标检测的方法有很多种,可以分为三类。
级联检测器:该模型有两种网络类型,一种是RPN网络,另一种是检测网络。一些典型的例子是RCNN系列。
带锚框的单级检测器:这类的检测器没有单独的RPN网络,而是依赖于预定义的锚框。YOLO系列就是这种检测器。
无锚框的单级检测器:这是一种解决目标检测问题的新方法,这种网络是端到端可微的,不依赖于感兴趣区域(ROI),塑造了新研究的思路。要了解更多,可以阅读CornerNet或CenterNet论文。
什么是COCO数据集
为了比较这些模型,广泛使用了一个称为COCO(commonobjectsincontext)的公共数据集,这是一个具有挑战性的数据集,有80个类和150多万个对象实例,因此该数据集是初始模型选择的一个非常好的基准。
如何评估性能
评估性能我们需要评价目标检测任务的各种指标,包括:
PASCAL VOC挑战(Everingham等人。2010年)
COCO目标检测挑战(Lin等人。2014年)
开放图像挑战赛(Kuznetsova 2018)。
要理解这些指标,你需要先去理解一些基本概念,如精确度、召回率和IOU。以下是公式的简要定义。
平均精度
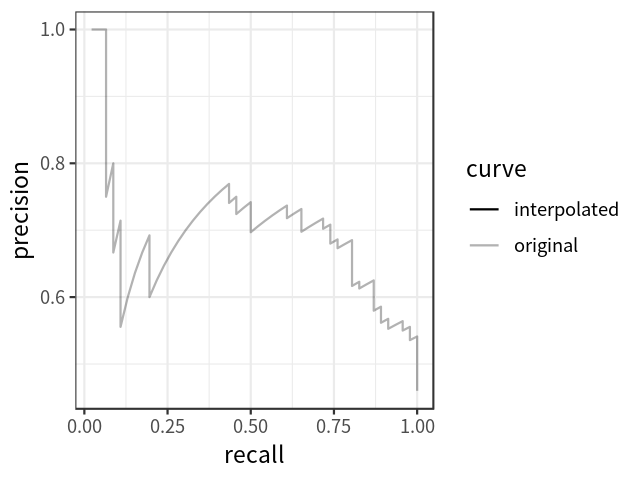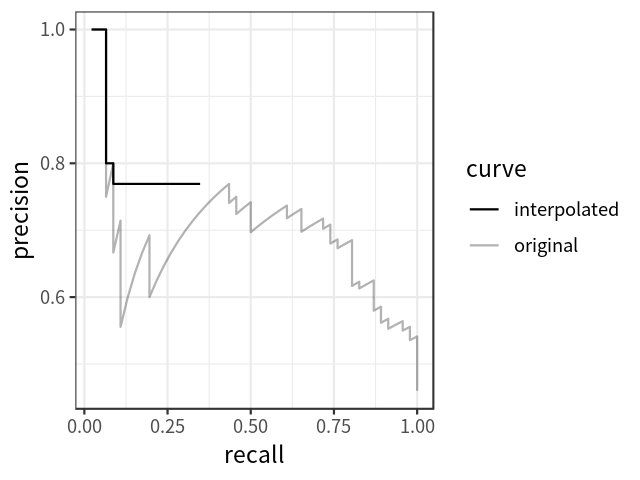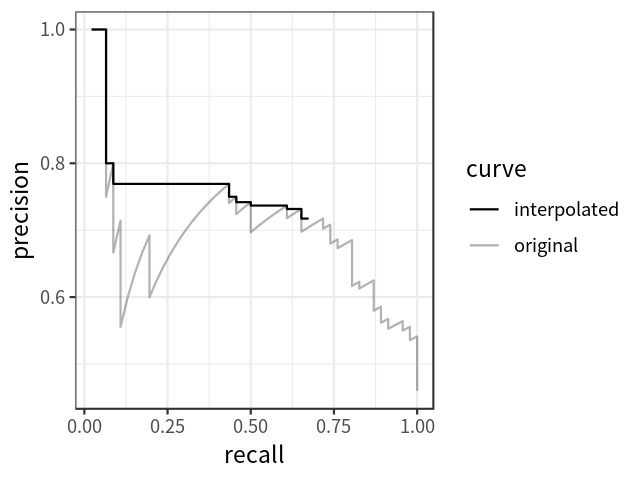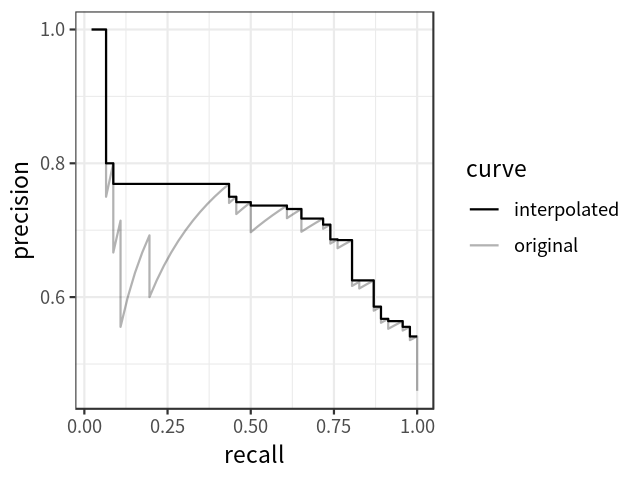
AP可定义为插值精度召回曲线下的面积,可使用以下公式计算:
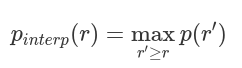
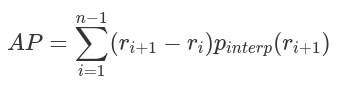
mAP
AP的计算只涉及一个类,然而,在目标检测中,通常存在K>1类。平均精度(Mean average precision,mAP)定义为所有K类中AP的平均值:
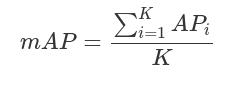
TIDE
TIDE是一个易于使用的通用工具箱,用于计算和评估对象检测和实例分割对整体性能的影响。TIDE有助于更详细地了解模型错误,仅使用mAP值是不可能找出哪个错误段导致的。TIDE可以绘制简单的图表,使分析变得轻松。https://youtu.be/McYFYU3PXcU
实际问题陈述
我们的任务是检测零售店闭路电视视频源中的人体边界框,这是跟踪模型的一个基础模型,且其检测所产生的所有误差都会传递到跟踪模型中。以下是在这类视频中检测的一些主要挑战。
挑战
视角:CCTV是顶装式的,与普通照片的前视图不同,它有一个角度
人群:商店/商店有时会有非常拥挤的场景
背景杂乱:零售店有更多的分散注意力或杂乱的东西(对于我们的模特来说),比如衣服、架子、人体模型等等,这些都会导致误报。
照明条件:店内照明条件与室外摄影不同
图像质量:来自CCTVs的视频帧有时会非常差,并且可能会出现运动模糊
测试集创建
我们创建了一个验证集,其中包含来自零售闭路电视视频的视频帧。我们使用行人边界框对框架进行注释,并使用mAP@0.50 iou阈值在整个训练迭代中测试模型。
第一个人体检测模型
我们的第一个模型是一个COCO预训练的模型,它将“person”作为其中的一个类。我们在每种方法中列出了2个模型,并基于COCO-mAP-val和推理时间对它们进行了评估。
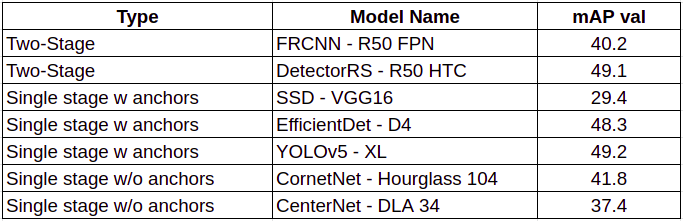
我们选择YOLOv5是因为它的单级特性(快速推理)和在COCO mAP val上的良好性能,它还有YOLOv5m和YOLOv5s等更快的版本。
YOLOv5
YOLO系列属于单阶段目标探测器,与RCNN不同,它没有单独的区域建议网络(RPN),并且依赖于不同尺度的锚框。架构可分为三个部分:骨架、颈部和头部。利用CSP(Cross-Stage Partial Networks)作为主干,从输入图像中提取特征。PANet被用作收集特征金字塔的主干,头部是最终的检测层,它使用特征上的锚框来检测对象。 YOLO架构使用的激活函数是Google Brains在2017年提出的Swish的变体,它看起来与ReLU非常相同,但与ReLU不同,它在x=0附近是平滑的。
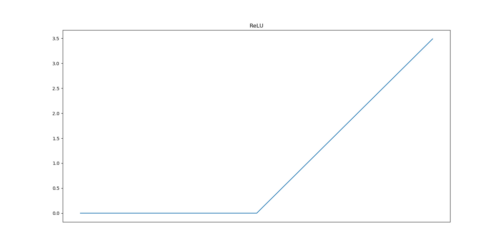
损失函数是具有Logits损失的二元交叉熵
性能
0.48 mAP@0.50 IOU(在我们的测试集上)
分析
这个现成的模型不能很好地执行,因为模型是在COCO数据集上训练的,而COCO数据集包含一些不必要的类,包含人体实例的图像数量较少,人群密度也较小。此外,包含人体实例的图像分布与闭路电视视频帧中的图像分布有很大不同。
结论
我们需要更多的数据来训练包含更多拥挤场景和摄像机视角介于45⁰-60⁰(类似于CCTV)的模型。
收集公共数据
我们的下一步是收集包含行人/行人边界框的公共可用数据集。有很多数据集可用于人体检测,但我们需要一些关于数据集的附加信息,如视角、图像质量、人体密度和背景等,以获取数据集的分布信息。 我们可以看到,满足我们确切需求的数据集并不多,但我们仍然可以使用这些数据集,因为人体边界框的基本要求已经得到满足。在下载了所有的数据集之后,我们把它转换成一个通用的COCO格式进行检测。
第二个人体检测模型
我们用收集到的所有公共数据集训练模型。
训练迭代2:
主干网络:YOLOv5x
模型初始化:COCO预训练的权重
epoch:10个epoch
性能
0.65 mAP @ 0.50 IOU
分析
随着数据集的增加,模型性能急剧提高。有些数据集具有满足我们的一个要求的高拥挤场景,有些包含满足另一个需求的顶角摄影机视图。
结论
虽然模型的性能有所提高,但有些数据集是视频序列,而且在某些情况下背景仍然是静态的,可能会导致过拟合。很少有数据集有非常小的人体,这使得任务很难学习。
清理数据
下一步是清理数据。我们从训练和验证集中筛选出损失最大的图像,或者我们可以说这些图像具有非常少的mAP度量。我们选择了一个0.3的阈值并将图像可视化。我们从数据集中筛选出三种类型的错误。
错误标记的边界框
包含非常小的边界框或太多人群的图像
重复帧的附近
为了去除重复帧,我们只从视频序列中选择稀疏帧。
第三个人体检测模型
有了经过清理和整理的数据集,我们就可以进行第三次迭代了 训练迭代3:
主干网络:YOLOv5x
模型初始化:COCO预训练的权重
epoch:~100个epoch
性能
0.69 mAP @ 0.50 IOU
分析
当未清理的数据从训练和验证集中移除时,模型性能略有改善。
结论
数据集被清理,性能得到改善。我们可以得出结论,进一步改进数据集可以提高模型性能。为了提高性能,我们需要确保数据集包含与测试用例相似的图像。我们处理了人群情况和一些视角的情况,但大多数数据仍然有一个前视角。
数据增强
我们列出了在实际情况下检测时将面临的一些挑战,但是收集到的数据集分布不同,因此,我们采用了一些数据扩充技术,使训练分布更接近实际用例或测试分布。 下面是我们对数据集进行的扩展。
视角
视角改变
照明条件
亮度
对比度
图像质量
噪音
图像压缩
运动模糊
通过将所有这些扩展汇总,我们可以将公共数据分布更接近实际分布,我们将原始图像和转换后的图像进行比较,可以从下面的图像中看到。
所有这些扩展都是通过使用“albumentation”来应用的,这是一个易于与PyTorch数据转换集成的python库,他们还有一个演示应用程序,我们用来设置不同方法的增强参数。库中还有很多可以与其他用例一起使用的扩展包。 我们使用albumentation方法来实现这一点。
第四个人体检测模型
现在有了转换后的数据集,我们就可以进行第四次迭代了 训练迭代4: 主干网络:YOLOv5x 模型初始化:迭代3中的模型 epoch:~100个epoch
性能
0.77 mAP @ 0.50 IOU
分析
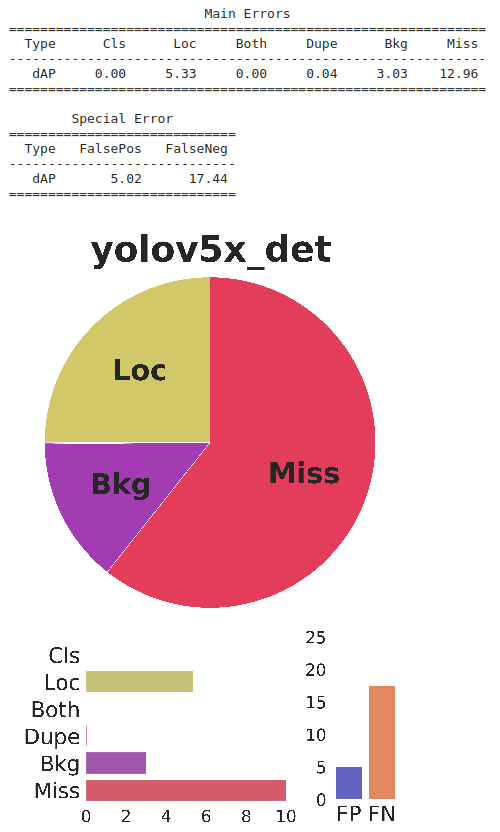
性能提高了近8%,该模型能够预测大多数情况,并在摄像机视角下进行了泛化。由于视频序列中的背景杂波和遮挡,仍有一些误报和漏报。
结论
我们试图收集数据集并覆盖任务中几乎所有的挑战,但是仍然有一个问题仍然存在,并阻碍了我们的模型性能,我们需要收集包含此类场景下的数据。
创建自定义批注
通过数据增强,我们创建了一些真实世界的样本,但是我们的数据在图像背景上仍然缺乏多样性。对于零售商店来说,框架背景充满了杂乱的东西,人体模型或衣服架子会导致假正例,而大面积的遮挡则会导致假反例。为了增加这种多样性,我们取消了谷歌搜索,从商店收集闭路电视视频,并对图片进行了手工注释。 首先,我们通过迭代4中的模型传递所有的图像并创建自动标签,然后使用开源注释工具CVAT(computervision and annotation tool)进一步修正注释。
最终人体检测模型
我们将定制存储图像添加到之前的数据集中,并为最终迭代训练模型。我们的最终数据集分布如下所示。
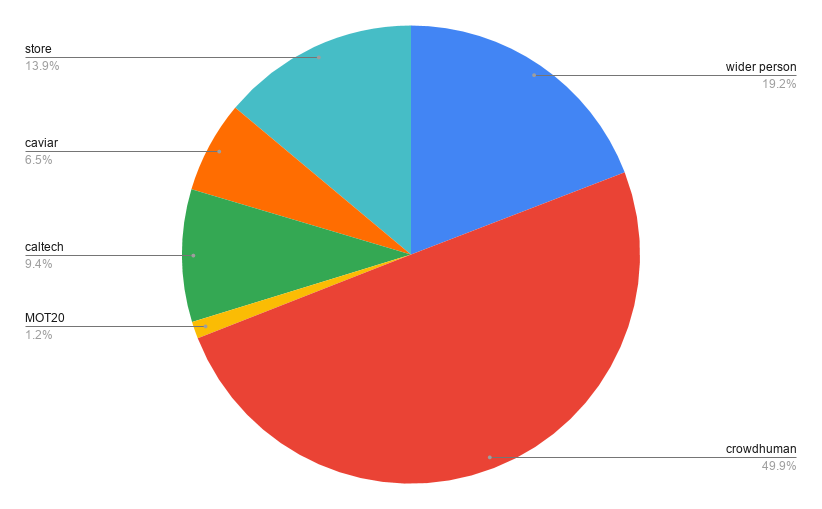
训练迭代5: 主干网络:YOLOv5x 模型初始化:迭代4中的模型 epoch:~100个epoch
性能
0.79 mAP @ 0.50 IOU
分析
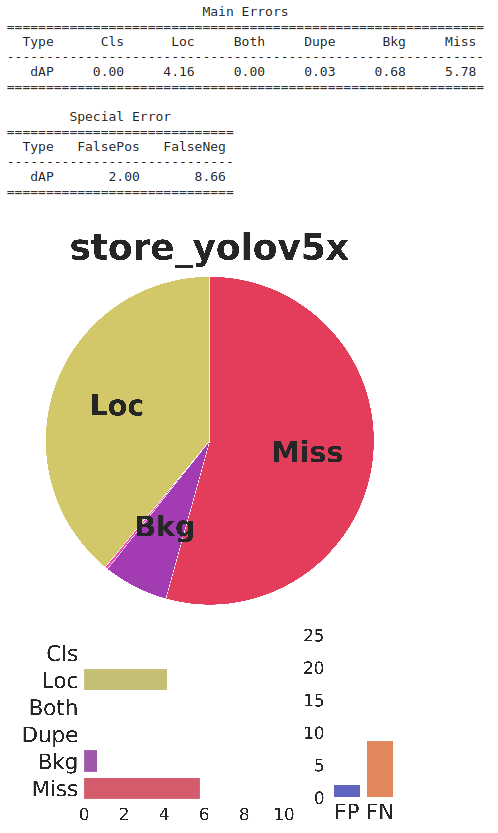
我们的模型的性能显示了大约0.2%的正增长,同时,从TIDE分析可以看出,假正例在误差中的贡献也有所降低。
结论
额外的数据有助于使模型对背景干扰更加稳健,但是收集到的数据量与总体数据集大小相比仍然非常少,并且模型仍然存在一些误报。当在随机图像上进行测试时,该模型能够很好地泛化。
总结
我们从模型选择开始,以COCO作为基准,我们实现一系列的模型。此外,我们考虑了推理时间和模型架构,并选择了yolov5。我们收集并清理了各种公开可用的数据集,并使用各种数据扩充技术来转换这些数据集,以适应我们的用例。最后,我们收集存储图像,并在手工注释后将其添加到数据集中。我们的最终模型是在这个精心设计的数据集上训练的,能够从0.46map@IOU0.5提高到0.79map@IOU0.5。
结论
通过根据用例对数据集进行处理,我们改进了大约20%的对象检测模型,该模型在映射和延迟方面仍有改进的余地,所选的超参数是yolov5默认给出的,我们可以使用optuna等超参数搜索库对它们进行优化。当训练分布和测试分布之间存在差异时,域适应是另一种可以使用的技术,同样,这种情况可能需要一个持续的训练循环,其中包含额外的数据集,以确保模型的持续改进。
原文标题:使用Python+OpenCV+yolov5实现行人目标检测
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
机器视觉
+关注
关注
163文章
4437浏览量
121144 -
OpenCV
+关注
关注
31文章
636浏览量
41783 -
python
+关注
关注
56文章
4813浏览量
85299
原文标题:使用Python+OpenCV+yolov5实现行人目标检测
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用OpenVINO™模型的OpenCV进行人脸检测,检测到多张人脸时,伺服电机和步入器电机都发生移动是为什么?
【米尔RK3576开发板评测】+项目名称YOLOV5目标检测
采用华为云 Flexus 云服务器 X 实例部署 YOLOv3 算法完成目标检测

在RK3568教学实验箱上实现基于YOLOV5的算法物体识别案例详解
YOLOv10自定义目标检测之理论+实践
如何用OpenCV的相机捕捉视频进行人脸检测--基于米尔NXP i.MX93开发板
在树莓派上部署YOLOv5进行动物目标检测的完整流程
YOLOv6在LabVIEW中的推理部署(含源码)

【飞凌嵌入式OK3576-C开发板体验】rknn实现yolo5目标检测
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测-迅为电子






 工商网监
工商网监
评论