 NLP:如何在只有词典的情况下提升NER落地效果
NLP:如何在只有词典的情况下提升NER落地效果
今天介绍一个论文autoner[1],主要是为了探索如何在只有词典的情况下,提升NER实际落地效果;
首先,如果手中含有词典,常规操作就是远程监督打标数据,然后做NER;
远程监督一个比较常见的操作就是使用我们手中的字典,通过字符匹配的形式对文本中可能存在的实体打标。
但是对于这种远程监督的形式,存在比较多的问题,这个论文主要探讨两种:多标签(multi-label tokens) 和标签不完善的问题;
针对multi-label tokens,论文提出的是Fuzzy-LSTM-CRF,简单讲就是讲LSTM后面的CRF层变为了Fuzzy CRF层,可以在处理tokens对应多标签的情况下,不牺牲计算效率;
第二个问题标签不完善,是因为字典毕竟是有限的,不可能把所有的实体都覆盖到,那么句子中没有被字典打标成功的词组很有可能也是某种实体,但是远程监督并没有对此做处理。
针对这个问题,本文提出了一种比较新的标注框架,简单来讲就是在这新的框架中,不去预测单个的token的类别,而是去判断两个相邻的tokens是不是在同一个实体中被tied;
上面只是我自己简单的分类,其实存在的两个问题和两种解决架构是相互融合在一起的,具体的我们下面谈。
0. 词典形式简单介绍
首先定义一下词典形式,包含两个部分,第一部分是实体的表面名称,这个包括规范名称和对应的同义词列表;第二个部分就是实体的类型;
其次,词典的标注肯定是有限的,肯定存在不在词典中的某些词组但是也属于某种类型的实体;
对于这部分实体,我自己的理解大体可以包含两个大部分;第一个大部分就是比如说【科技】这个领域覆盖的【科技】实体有有限的,所以有漏网之鱼;第二部分就是词典的实体类型是有限的,比如词典总共包含2个实体类型,但是你真实的文本包含更多的实体类型,存在漏网之鱼。
对于这些漏网之鱼的实体,我们的策略是这样的。
首先通过AutoPhrase从文中挖掘出来高质量短语,然后统一赋值为unknown type,也就是未知类型。
1. Fuzzy-LSTM-CRF
1.1 标注策略
梳理一下,我们现在手上有词典;
词典包含两个部分,一部分是已知实体类型(假设是2个,当然可能更多或者更少);另一个部分就是我们通过某种方式挖掘出来的高质量实体对应的未知类型;
然后我们通过手中的词典对原始无标注文本进行打标;
那么现在对于句子中的某个token,它存在三种可能性;第一它可能是已知实体类型中的一种或者多种;第二它属于未知类型;第三是属于O这种情况,就是non-entity;
基于传统架构BIlstm-CRF如何解决多标签的问题?
其实本质解决的思路很简单。对于原来的每个token,只是预测一个类别,现在是预测多个类别就可以了。
详细点讲就是,首先对于远程监督标注的过程,我们会使用三种策略。
我们先假设我们使用{I;O;B;E;S}的标注形式;
第一,对于某个token,如果它对应到了已知类型中的某一个或者多个实体,那么按照对应的位置直接标记上,不要漏掉;也就是说{I;B;E;S}和对应的一个或者多个实体类型对上标;
第二对于对于某个token,如果属于未知类型,那么对应的这个token就需要把所有已知实体类型(区别于上面的一个或者多个已知实体类型)和 {I,O, B, E, S}对应的打标上;
注意,这里并没有使用未知实体类型,而是使用的所有的已知实体类型;
第三个对于既不属于已知类型的,也不属于未知类型的,全部打上O;
1.2 Fuzzy-LSTM-CRF 模型架构
其实很好理解,传统的CRF最大化唯一一条有效的标注序列。在这里,我们最大化所有有可能的标注序列。
公式如下:
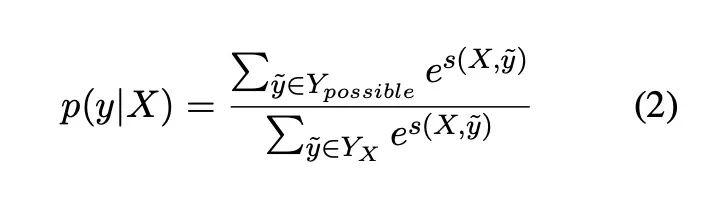
Fuzzy-LSTM-CRF优化公式
看架构图:
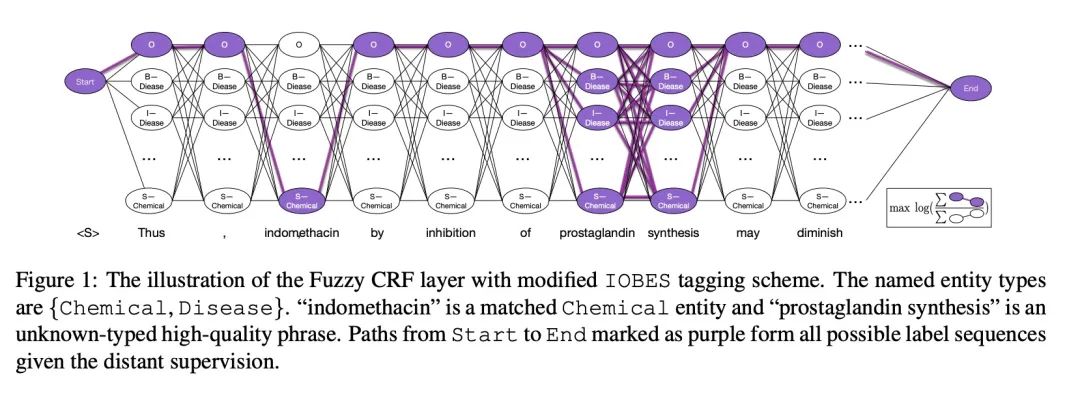
Fuzzy-LSTM-CRF
2. AutoNER
区别于Fuzzy-LSTM-CRF 模型沿用传统架构,在这里论文提出一种新的标注架构-Tie or Break;
这个标注框架更加关注的是当前token和上一个token是否在同一个实体里面;如果在同一个实体里面,那么就标注为Tie;
如果当前单词和上一个单词至少有一个在unkonw类型的高质量短语,那么标注为unkonw,其他情况标注为Break;
优化过程:把实体识别和实体类型判定分离开。
原论文中描述的是先做实体识别,两个Break之间作为一个span,然后做实体类型判定;
实体识别中,对于当前单词和上一个单词之间类别的的输出,对Tie和Break做二分类损失,如果类别是unkown类别,直接跳过,不计算损失。
概率公式如下:
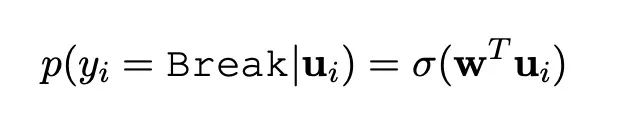
tie_break_loss
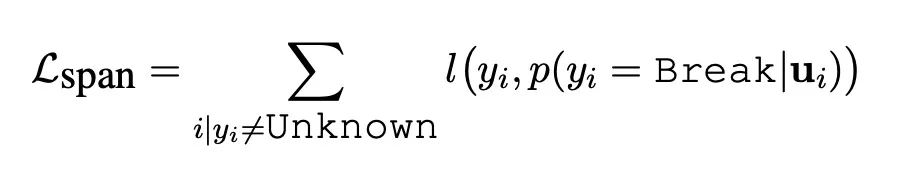
tie_break_loss
第二步预测实体类型,包含None实体类型
unkonw这种,知道这属于实体,在高质量短语词典中,但是不知道短语类型,所在这里我们会标注为None实体类型。
其他的不在词典中的,当然也就会被标注为None实体类型。
为了应对多标签,也就是同一个实体对应不同的类别,这里修改了最后的CE损失函数:
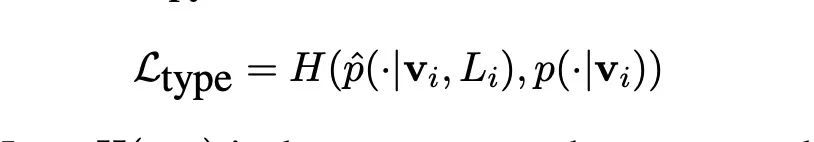
CE_总
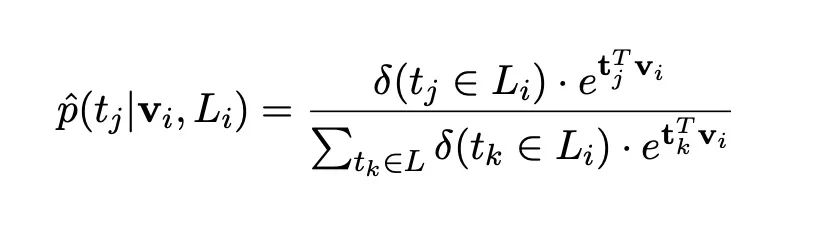
CE_Soft
使用的是软标签的进行的CE的计算,并没有使用硬标签。
对应的是在远程监督中,当前实体真实类型标签集合。从公式我们可以知道,尤其是看分母,在不属于这个集合的标签概率我们并没有计算在内。
总结
多提一个小细节,就是高质量短语的挖掘使用的是AutoPhrase,大家可以去试一下;
论文提出两种结构解决多标签和标签不完善的问题。
首先对于标签不完善,使用上面提到的AutoPhrase去挖掘文本中的高质量短语,作为词典中的未知类型。
在Fuzzy-LSTM-CRF,需要注意的细节是,对于未知类型的标注,我们使用的策略是标注所有已知类型;
对于AutoNER,有两个细节需要注意,一个是新的标注框架tie or break,重点在于去看两个相邻单词是否属于同一个实体;第二个细节就是为了解决多标签问题,修改了损失函数,使用的软标签;
责任编辑:xj
原文标题:【论文解读】如何在只有词典的情况下提升NER落地效果
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言
+关注
关注
1文章
288浏览量
13347 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:【论文解读】如何在只有词典的情况下提升NER落地效果
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论