 NLP:关系抽取到底在乎什么
NLP:关系抽取到底在乎什么
关系抽取到底在乎什么?这是来自EMNLP20上清华大学刘知远团队的“灵魂发问”~ 关系抽取是每一位NLPer都很熟知的任务,特别是基于BERT的神经关系抽取模型已经登顶各大榜单SOTA,某些甚至直逼人类表现。但也许你和JayJay一样,可能只是调个包、从不过问关系抽取的核心要素是啥吧~ 在刘知远老师的EMNLP20论文《Learning from Context or Names? An Empirical Study on Neural Relation Extraction》中,就「关系抽取到底在乎什么」这一问题进行深入全面的探究,是难得的好文!
注意:本文所称的关系抽取也称关系分类,即判断两个实体
论文下载:https://arxiv.org/pdf/2010.01923.pdfgithub开源:https://github.com/thunlp/RE-Context-or-Names 为具备更好的阅读体验,本文以QA形式进行组织:
我们废话不说,先po结论(划重点): 1、对关系抽取的两个主要特征(上下文信息和实体信息),进行了对比分析发现:
上下文信息 和 实体信息 对于关系模型都很关键;
上下文信息是关系模型的主要信息来源;
实体信息中最重要的实体类型信息,但模型会存在对实体信息的过度依赖问题;
现有的数据集可能会通过实体泄漏浅层的启发式信息,导致当前关系任务的指标虚高!
2、构建了关系预训练模型,基于关系抽取的实体遮蔽的对比学习框架:
能帮助模型更好地的借助上下文信息和实体类型信息,避免“死记硬背”实体表面表述;
提高了多个场景下神经关系抽取模型的有效性和鲁棒性,特别是在低资源场景下;
Q1: 关系抽取为什么主要利用「上下文信息」和「实体信息」?

为什么本篇论文会选取上下文和实体信息进行对比研究呢?作者认为:
上下文信息:从人的直觉来看,文本上下文是主要的信息来源;最为简单的一种方式,就是可以用关系模板进行归纳。如上图所示,「... be founded ... by ...」模板就可以很好地映射到某一类关系上。因此,上下文关系肯定会对关系预测结构起着某种作用。
实体信息:实体信息主要包括实体类型、实体ID、实体属性信息等,如果实体可以被链接到知识图谱上,那么相关信息也可以被模型所利用。既然关系抽取基于实体pair进行的分类预测,那么实体信息就必不可少了。
Q2: 关系抽取的baseline模型选择哪些?
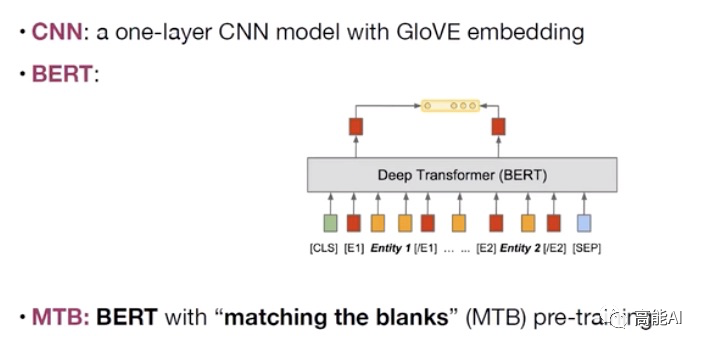
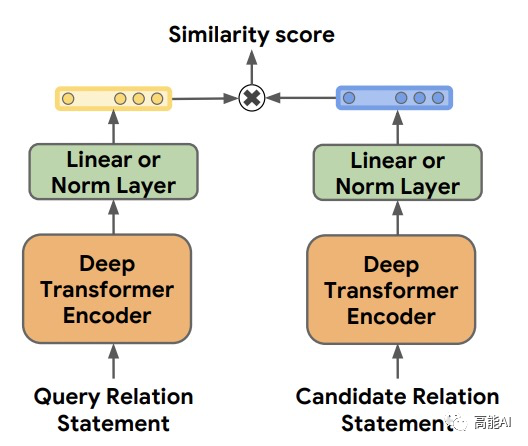
为了更好地进行分析验证,本文主要主要采取CNN、BERT、MTB三种模型进行实验(如上图所示):采取BERT时主要是提取实体pair的相关标识符对应的表示进行关系分类。 MTB是由Google在2019年提出预训练关系模型 ,其只在获得更好的适配于关系抽取的特征表示,其具体的预训练方式为:认为包含相同实体pair的句子表示相同的关系,将相似度得分作为预训练目标,如下图示意。
Q3: 「上下文信息」和「实体信息」到底哪家强?

为了分析「上下文信息」和「实体信息」对于关系模型的内在影响,论文设置众多输入格式(如上图所示):
Context+Mention (C+M) :即最为广泛的使用方式,在原句子输入的同时,强调实体mention:对于BERT模型,采用位置向量和特殊的实体标识符来强化metion。
Context+Type (C+T) :将实体mention用其实体类型Type代替,如上图,「SpaceX」用「organization」代替,「Elon Musk」用「person」代替。
Only Context (OnlyC) :即只利用上下文信息,将实体mention用「subject」或「object」代替,通过这种方式可以将实体信息源完全阻挡。
Only Mention (OnlyM) :即只利用实体提及,忽略其他文本上下文的输入。
Only Type (OnlyT) :即只利用实体类型信息,如「organization」「SEP」「person」。
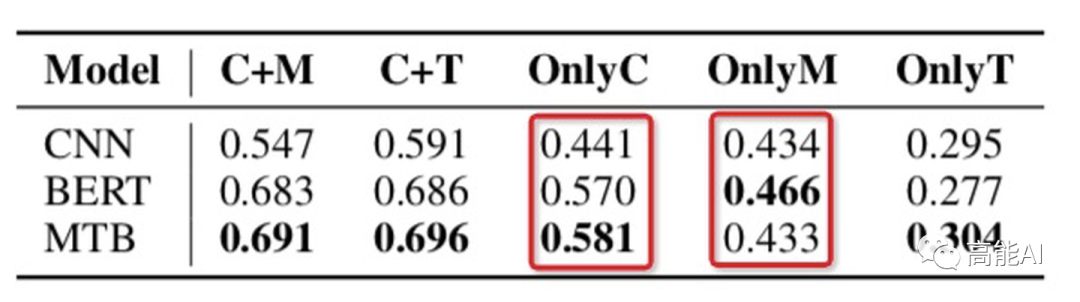
论文通过上述设置在最大的有监督关系数据集TACRED上(共42种关系,10w+实例)进行了相关实验,结果如下(指标为micro F1值):
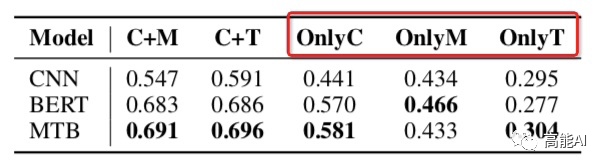
由上图的红框(OnlyC、OnlyM、OnlyT)可以看出,只利用上下文信息或实体信息指标都大幅下降,这表明:上下文信息 和 实体信息 对于关系模型都很关键;
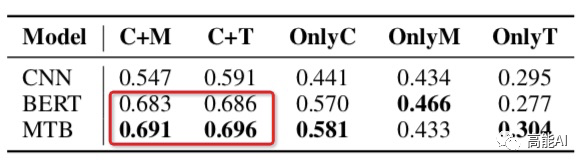
由上图的红框可以看出,C+M和C+T表现一致,这表明:实体提及中的类型Type信息很重要!这与之前女神的SOTA《反直觉!陈丹琦用pipeline方式刷新关系抽取SOTA》中关于「类型信息」的重要性相互佐证~
由上图的红框可以看出:
OnlyC总体高于OnlyM,可以看出:上下文信息比实体信息更重要~(PS:CNN中OnlyC没有明显高于OnlyM,也说明其上下文的捕捉能力不如BERT吧)
OnlyM也有较高指标,这表明:现有的数据集可能会通过实体泄漏浅层的启发式信息,导致当前关系任务的指标虚高!
此外,本篇论文也通过Case Study进一步证明了上述结果、并有了新的发现:
C+M与C+T类似,共享95.7%的正确预测和68.1%的错误预测,充分说明了实体提及的主要的信息来源是其类型Type信息。
C+M容易对实体提及产生过高的偏置依赖,特别是容易对训练集中的实体提及进行“死记硬背”,如下图:模型容易死记住训练集中「Washington」的实体提及只存在于「stateorprovinceofresidence 」关系中,从而导致关系预测错误。

C+T不容易捕捉共指信息和语义信息,如下图所示,「Natalie」和「she」两个实体如果被实体Type替代后,不容易捕捉到原有的共指关系:

再通过对OnlyC的case分析中发现:人类可以本能地从上下文中判断关系,但模型似乎在捕捉上下文信息的能力上还有很大缺失。如下图所示,具体体现在3个方面:
Wrong:对于那些很清晰的关系模式仍然会预测错误。
No pattern:对于那些不具备pattern的关系会预测错误。
Confusing:对于困惑的关系类型缺乏鲁棒能力。

Q4: 如何提升关系模型的预测性能? 从上文的分析中,我们可以发现:上下文信息和实体信息对于关系模型都很重要,但在一些情况下,关系模型并不能很好地理解关系模式、会过度依赖于实体mention的浅层提示信息。 为了更好地捕捉上下文信息和实体类型Type信息,论文提出了一种基于实体遮蔽的对比学习框架,来进行关系预训练。 1、对比学习数据生成方法
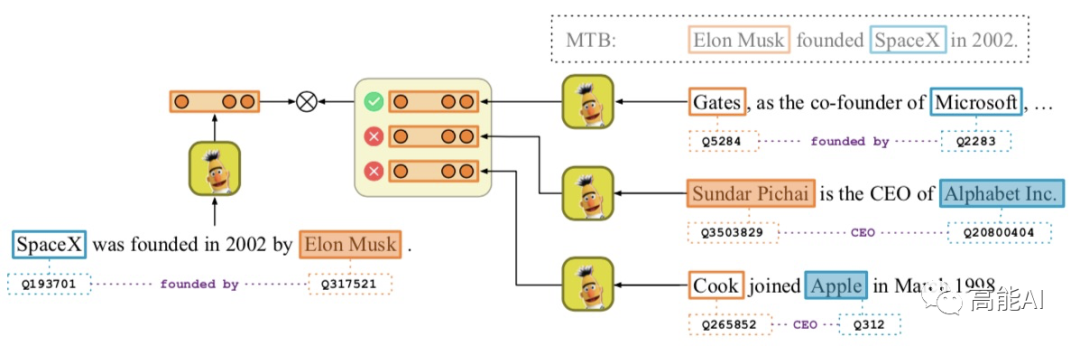
对比学习预训练框架如上图所示,论文借鉴了「对比学习」的思想,通过聚合“neighbors”、分离“non-neighbors”来学习特征表示;通过这种模式,“neighbors”具备相似的表示。因此,定义“neighbors”对于对比学习至关重要。
本文定义:实体pair共享同种关系的句子是“neighbors”。
为了防止模型在预训练过程中对实体mention死记硬背、或者抽取比较浅层的表面特征,作者采取了随机mask实体的办法,将实体mention替换为「BLANK」,替换率为0.7. 事实上,生成预训练数据是通过远程监督的方法进行,这虽然会造成噪声;但作者认为噪声问题对于预训练框架不是关键的,因为:预训练目标是相对于像BERT这样的原始预训练模型,获得相对更好的关系表示,而不是直接训练关系模型对于下游任务,因此数据中的噪声是可以接受的。 通过上述的对比学习生成方法,预训练模型可以学习更好地从实体metion中掌握类型Type信息,并从文本上下文中提取关系语义:
成对的两个句子虽然包含不同的实体pair,但共享相同的关系,提示模型发现这些实体mention之间的联系。此外,实体mask策略可以有效地避免简单的记忆实体mention。这最终鼓励模型利用实体类型Type信息。
生成策略提供了相同关系类型下的多种上下文集合,这有利于模型学习从多种表达方式中提取关系pattern。
2、对比学习训练目标 上述预训练的目标函数共包含两部分:对比学习目标( Contrastive Pre-training,CP)和遮蔽语言模型(MLM):
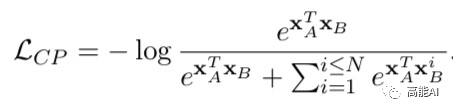
对比损失CP采取随机负样本采样,加速训练过程。 3、对比学习实验结果
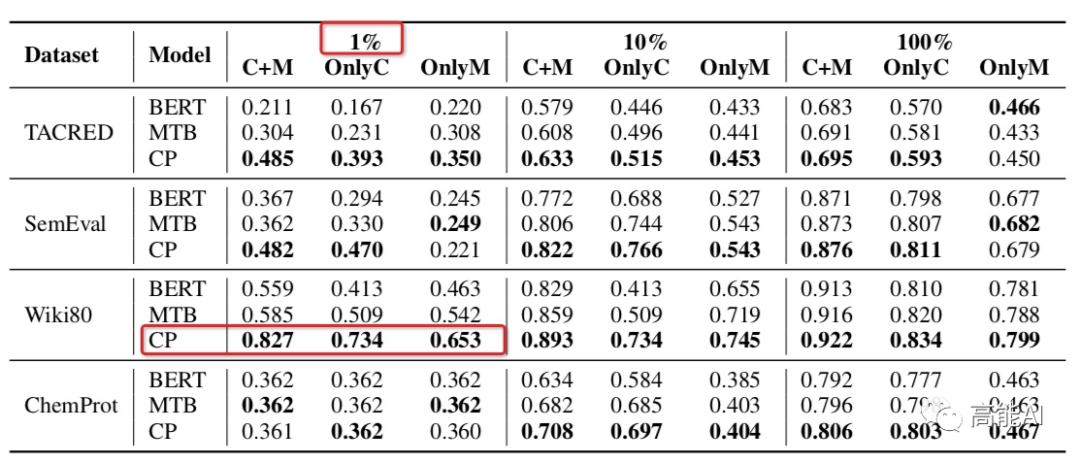
基于对比学习的预训练框架的关系模型最终表现如何?作者在不同的数据集上设置不同数据使用量(1%、10%、100%)进行了对比分析,发现:对比学习模型CP在不同数据集上均超过了BERT和MTB,特别是在低资源(1%数据量)条件下也能呈现较高指标,如上图红框所示。 可见,对比学习机制相比于Google的MTB模型更具备多样性的数据特征、能更充分的学习实体类型Type信息。
总结 本文主要基于「关系抽取到底在乎什么」、「上下文和实体mention如何影响关系模型」进行了讨论,发现:
文本上下文和实体mention都给关系模型提供了关键信息;
关系抽取数据集可能会通过实体泄漏浅层的启发式信息,导致当前关系任务的指标虚高!
关系模型并不能很好地理解关系模式、会过度依赖于实体mention的浅层提示信息
基于上述几点,论文提出了一种基于实体遮蔽的对比学习框架来改进关系模型的表现,最终提高了多个场景下神经关系抽取模型的有效性和鲁棒性(特别是在低资源条件下)。 有了本文全面的实验分析,或许未来我们可以进一步研究开放关系抽取和关系发现问题,这些需要我们考虑zero-shot问题,但可以确信:预训练关系模型将对这些领域产生积极影响。
责任编辑:xj
原文标题:刘知远老师的“灵魂发问”:关系抽取到底在乎什么?
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言
+关注
关注
1文章
291浏览量
13414 -
nlp
+关注
关注
1文章
489浏览量
22142 -
知识图谱
+关注
关注
2文章
132浏览量
7756
原文标题:刘知远老师的“灵魂发问”:关系抽取到底在乎什么?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论