 嵌入式代码覆盖率如何进行统计有哪些方法和经验
嵌入式代码覆盖率如何进行统计有哪些方法和经验

代码覆盖率是衡量软件测试完成情况的指标,通常基于测试过程中已检查的程序源代码比例 计算得出。代码覆盖率可以有效避免包含未测试代码的程序被发布。
代码覆盖率能不能提高软件的可靠性?答案是肯定的,代码的覆盖率分析是保证软件质量最简 便易行的方法。
代码覆盖率等级
代码覆盖率可以通过多种方法测量。最常用的是测量以下一个或多个指标:语句覆盖率,分支 覆盖率,修订的条件/判定覆盖率(MC/DC)。以下章节中将逐一详解这些代码覆盖率。
语句覆盖率
语句覆盖率用来度量被测代码中的可执行语句是否被执行到,它并不考虑循环或者条件语句, 只针对语句度量可执行代码。应当特别注意的是:“语句”并不等同于代码行。
一般情况下,对于 C,C++,Java或Ada,分号代表语句结束。在某些情况下,一条语句会跨越多 行代码。语句覆盖率可以有效度量可执行代码是否被执行,但同时也有一定的局限性。
语句覆盖率的局限
考虑如下图1的代码段:
int* p = NULL;
if (condition)
p = &variable;
*p = 123;
图 1 – 语句覆盖局限代码示例
如果“condition”为true,那么就有可能达到100%的语句覆盖,然而这个测试用例忽略了另 一种情况:如果“condition”为假,程序将引用空指针,因此,虽然语句覆盖率是一个很好 的度量指标,它仍旧是入门级的代码覆盖率。理想情况下,即使“condition”为false,测试 用例也应当被计算。
分支覆盖率
分支覆盖率用来度量程序中所有的判定和分支以及相应的输出是否都被测试执行到,例如 “if”语句必须将“true”和“false”都考虑到以覆盖所有的输出。如果只有一个路径被执行,那么覆盖率将被标记为部分执行。
和语句覆盖率类似,分支覆盖浪费也有一些需要注意的细节,尤其在针对“惰性求值”的编程语言时,惰性求值是将代码的求值操作延迟到需要结果值时再进行的一项技术。
分支覆盖率的局限
典型的情况是当有复杂的布尔表达式的“惰性求值”出现时,如下图2的代码片段:
int* p = NULL;
if (condition1 && (condition2 || function1(*p)))
statement1;
else
图 2 – 分支覆盖率局限代码示例
考虑“condition1”为假的情况,惰性求值将不会度量“condition2”或,此种情况同样会导致 代码“if (condition1 && (condition2 || function1(*p)))”的分支覆盖率计算错误。
继续考虑“condition1”和“condition2”都为真的情况。惰性求值将再次导致“function1(*p)” 不会被度量,也同样会导致代码“if (condition1 && (condition2 || function1(*p)))”的分支覆盖率 计算错误。在此种情况下,有可能出现分支覆盖率为100%但软件中仍有潜在缺陷的情况。
修订条件/判定覆盖率(MC/DC)
MC/DC是一种特殊的分支覆盖率,它不但会使用分支覆盖率报告复杂条件下的true和false输出,同时也会报告复杂条件下的全部分支条件输出。
MC/DC最初由波音公司创建,用于航空软件中DO-178B的A级认证。通过对所有的子条件输出分支的独立证明,有效解决了惰性求值带来的问题。
继续讨论代码示例2,我们需要在“condition2”和“function1(*p)”固定的条件下验证“condition1” 的“true”和“false”判定分支,之后继续固定“condition1”和“function1(*p)”验证“condition2” 的判定分支。
同样的,让我们在固定“condition1”和“condition2”的条件下讨论 “function1(*p)”。在其他分支条件固定的情况下验证某个分支条件的“true”和“false”值称作“MC/DC对”。MC/DC对一般使用MC/DC真值表描述。表1就是一个MC/DC真值表示例。

在软件开发的不同阶段获取覆盖率
软件测试有很多种类,本文将其简要的分为三类:
》 系统/函数测试: 测试集成后的整个应用
》 集成测试::测试集成的子系统
》 单元测试:测试一个或多个文件或类
每个软件项目在系统测试的过程中都会模拟最终用户的操作对源代码做一些系统测试。导致软件发布后仍旧存在缺陷最重要的一个原因通常是程序在运行过程中遇到了非预期的,即没有测试的输入组合。
很多软件项目并不是没有做集成测试或者单元测试。只是在完成集成测试或单元测试后,开发团队可能苦于为隔离程序中的单个或多个文必须所需的大量测试代码量。
对于最严格的单元测试和集成测试来说,最终生成的测试代码量比待测代码量还要庞大是很经常出现的情况。因此,这两种级别的测试普遍适用于关键和高安全领域,例如:航空航天、医疗、交通运输、工业过程控制、高速汽车等。此类软件中包含大量的嵌入式应用软件。
关键领域的结构化测试流程一般会将需求的级别高低作为重点,代码覆盖率因而会在这种“基于需求”的测试中进行分析。在许多项目中,高等级的需求最先被测试。此时代码覆盖率可以被用来检测和报告所达到的覆盖比例。
然而不幸的是,在系统测试和功能测试阶段想要达到100%的代码覆盖率几乎是不可能的。通常情况下系统测试和功能测试只能达到60%-70%的代码覆盖率,剩余30%-40%的代码覆盖率需要在单元测试和集成测试阶段才能够完成。
单元测试使用包含驱动和桩的测试代码隔离系统中的特定函数,同时使用测试用例模拟这些函数的执行。这些所谓的“低等级测试需求” 对被测试代码提供了更高的控制,可以提高先前执行的系统测试覆盖率(甚至能达到100%)。因此,在不同的测试之间共享覆盖率数据是非常有必要的。
嵌入式环境中获取覆盖率带来的挑战
常言道“有得必有失”,在嵌入式环境获取代码覆盖率的问题上,要付出的代价是对待测代码额外的插桩工作。
插桩是将额外的代码添加到程序中,从而实现测试过程中的覆盖率收集和分析操作。
由于插桩的相关操作将导致程序源代码增多,进而延长程序的执行时间,因而需要预测插桩后的源代码的覆盖范围预测,尤其当测试实时嵌入式系统环境时,此项工作就更为重要。
事实上,要精准的预测程序文件插桩的影响几乎是不可能的。没有算法支持(也不可能有)。 每个系统都包含很多的变量,具有独立唯一的复杂性。当然,对于典型的示例系统来说,获取一组准确的估计还是可能实现的。
在共享环境中获取覆盖率数据
在嵌入式环境下管理代码覆盖率的主要问题在于如何配置内存以容纳额外的插桩代码。
VectorCAST针对大量示例代码评估后发现添加了上文中提出的各种覆盖率额外配置之后,源代码量增长量普遍达到了10%。对于绝大多数的32位目标板,这并不是一个很大的问题,但对于存储容量有限的8位或者16位目标板来说,几乎可以肯定这会是一个问题。
为了降低可执行文件的大小,各种各样的代码插桩技术被发明出来,针对不同大小的存储区域有不同的数据采集技术。植入存储器内部的收集系统可以用于监测被检测到的代码。这是插桩技术中保证使用最少RAM的关键技术。
-
嵌入式
+关注
关注
5209文章
20657浏览量
337066 -
JAVA
+关注
关注
20文章
3006浏览量
116832 -
C++
+关注
关注
22文章
2129浏览量
77374
发布评论请先 登录
测量嵌入式软件的代码覆盖率
C语言单元测试在嵌入式软件开发中的作用及专业工具的应用
重点厘清覆盖率相关的概念以及在芯片开发流程中跟覆盖率相关的事项
Verilog代码覆盖率检查
怎么才能写出高覆盖率的Verilog代码?
高覆盖率的Verilog代码的编写技巧
如何使用覆盖率指标进行更有效的嵌入式软件测试
更好地测量代码覆盖率的 9 个技巧

代码覆盖率工具的重要性
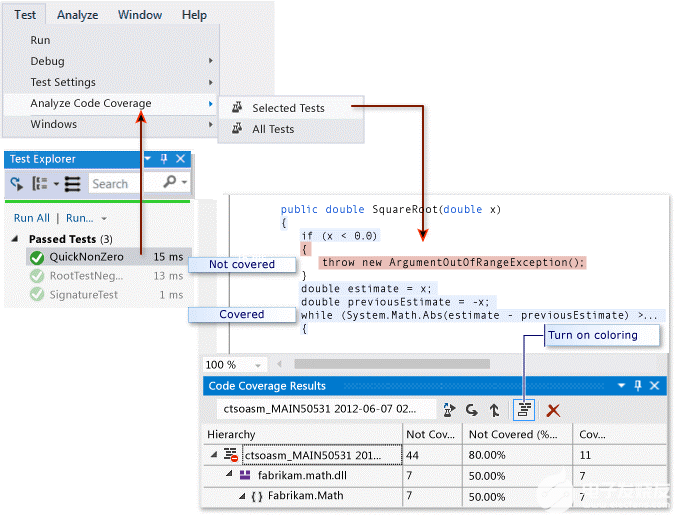
测量嵌入式系统中的代码覆盖率
代码覆盖率记录




评论