 基于PyTorch的深度学习入门教程之PyTorch重点综合实践
基于PyTorch的深度学习入门教程之PyTorch重点综合实践

前言
PyTorch提供了两个主要特性:
(1) 一个n维的Tensor,与numpy相似但是支持GPU运算。
(2) 搭建和训练神经网络的自动微分功能。
我们将会使用一个全连接的ReLU网络作为实例。该网络有一个隐含层,使用梯度下降来训练,目标是最小化网络输出和真实输出之间的欧氏距离。
目录
Tensors(张量)
Warm-up:numpy
PyTorch:Tensors
Autograd(自动梯度)
PyTorch:Variables and autograd (变量和自动梯度)
PyTorch : Defining new autograd functions(定义新的自动梯度函数)
TensorFlow: Static Graphs (静态图)
nn module
PyTorch: nn
PyTorch: optim
PyTorch: Custom nn Modules (定制nn模块)
PyTorch: Control Flow + Weight Sharing (控制流+权重分享)
Tensors(张量)
Warm-up:numpy
在介绍PyTorch之前,我们先使用numpy来实现一个网络。
Numpy提供了一个n维数组对象,以及操作这些数组的函数。Numpy是一个通用的科学计算框架。它不是专门为计算图、深度学习或者梯度计算而生,但是我们能用它来把一个两层的网络拟合到随机数据上,只要我们手动把numpy运算在网络上前向和反向执行即可。
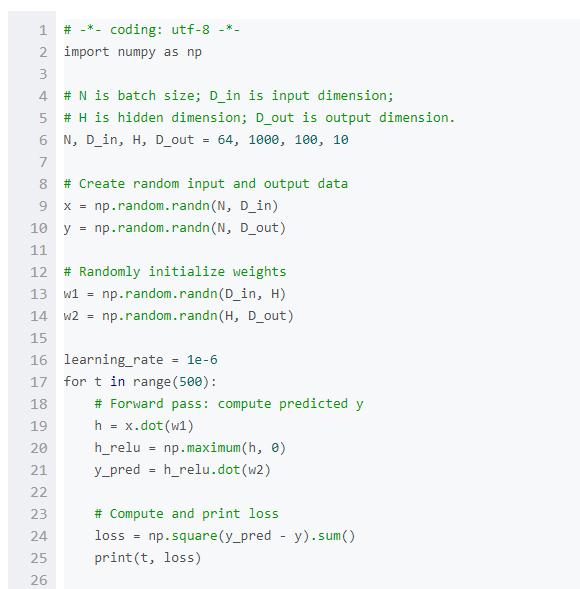
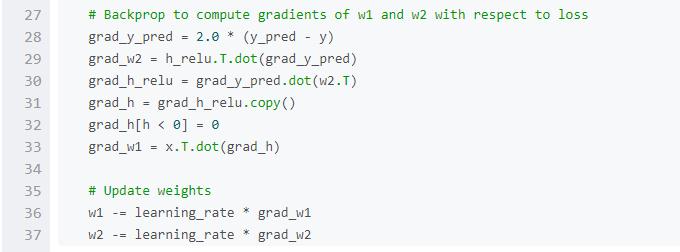
Numpy是一个了不起的框架,但是它很遗憾地不能支持GPU运算,无法对数值计算进行GPU加速。对于现在的深度神经网络,GPU一般能提供50倍以上的加速,所以numpy由于对GPU缺少支持,不能满足深度神经网络的计算需求。
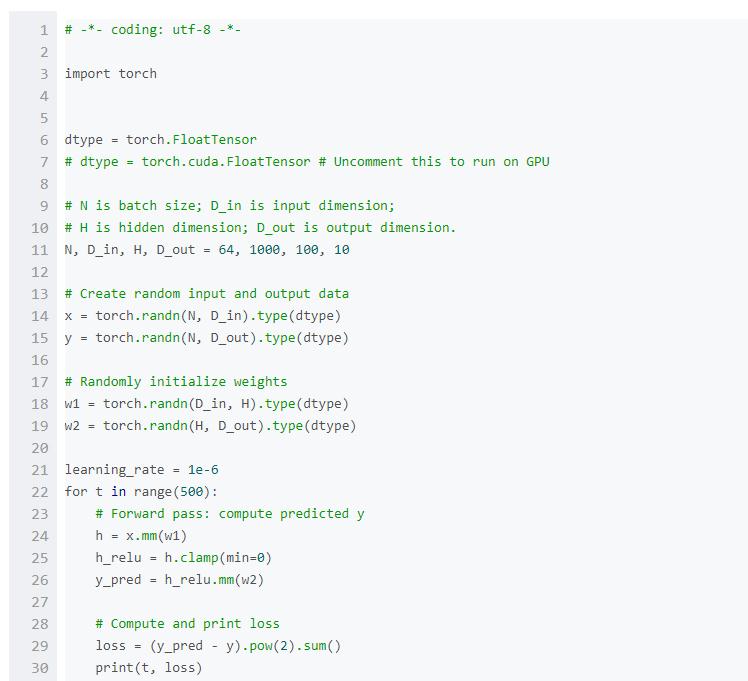
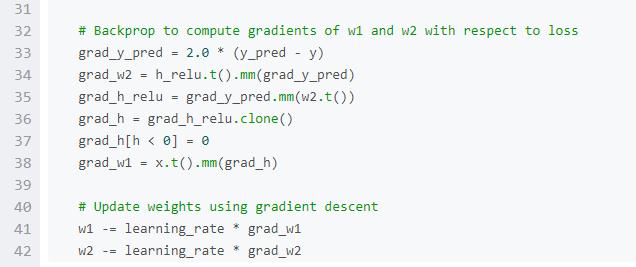
这里介绍一下最基本的PyTorch概念:Tensor。一个PyTorch Tensor在概念上等价于numpy array:Tensor是一个n维的array,PyTorch提供了很多函数来在Tensors上进行运算。像numpy arrays一样,PyTorch Tensors也不是为深度学习、计算图、梯度而生;他们是一个科学计算的通用工具。
PyTorch Tensors可以利用GPU来加速数值计算。为了能在GPU上跑Tensor,我们只需要将它转到新的数据类型。
我们使用PyTorch Tensors来拟合2层的网络。与上面的numpy例子一样,我们需要手动执行网络上的前向和反向过程。
Autograd(自动梯度)
PyTorch:Variables and autograd (变量和自动梯度)
在上面的例子中,我们必须手动执行网络的前向和反向通道。对于一个两层的小网络来说,手动反向执行不是什么大事,但是对于大型网络来说,就非常费劲了。
幸运的是,我们可以使用自动微分来自动计算神经网络的反向通道。PyTorch的autograd 包就提供了此项功能。当使用autograd的时候,你的网络的前向通道定义一个计算图(computational graph),图中的节点(node)是Tensors,边(edge)将会是根据输入Tensor来产生输出Tensor的函数。这个图的反向传播将会允许你很轻松地去计算梯度。
这个听起来复杂,但是实际操作非常简单。我们把PyTorch Tensors打包到Variable 对象中,一个Variable代表一个计算图中的节点。如果x是一个Variable,那么x. data 就是一个Tensor 。并且x.grad是另一个Variable,该Variable保持了x相对于某个标量值得梯度。
PyTorch的Variable具有与PyTorch Tensors相同的API。差不多所有适用于Tensor的运算都能适用于Variables。区别在于,使用Variables定义一个计算图,令我们可以自动计算梯度。
下面我们使用PyTorch 的Variables和自动梯度来执行我们的两层的神经网络。我们不再需要手动执行网络的反向通道了。


PyTorch : Defining new autograd functions(定义新的自动梯度函数)
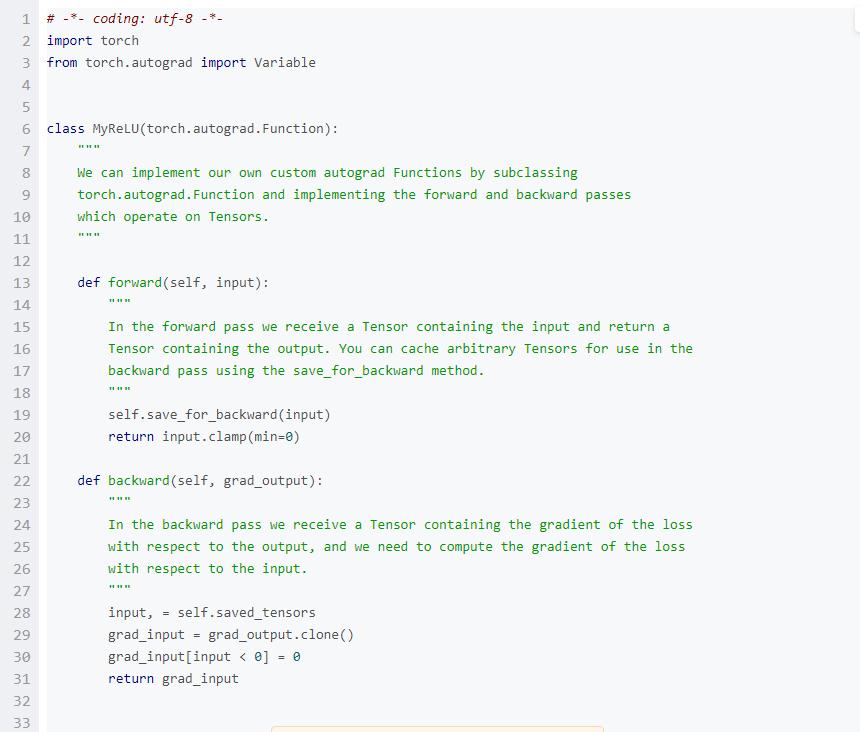
在底层,每一个原始的自动梯度运算符实际上是两个在Tensor上运行的函数。其中,forward函数计算从输入Tensors获得的输出Tensors。而backward函数接收输出Tensors相对于某个标量值的梯度,并且计算输入Tensors相对于该相同标量值的梯度。
在PyTorch中,我们可以很容易地定义自己的自动梯度运算符。具体来讲,就是先定义torch.autograd.Function的子类,然后实现forward和backward函数。之后我们就可以使用这个新的自动梯度运算符了。使用该运算符的方式是创建一个实例,并且像一个函数一样去调用它,传递包含输入数据的Variables。
在这个例子中,我们定义自己的定制自动梯度函数来执行ReLU非线性,然后使用它执行我们的两层网络。


TensorFlow: Static Graphs(静态图)
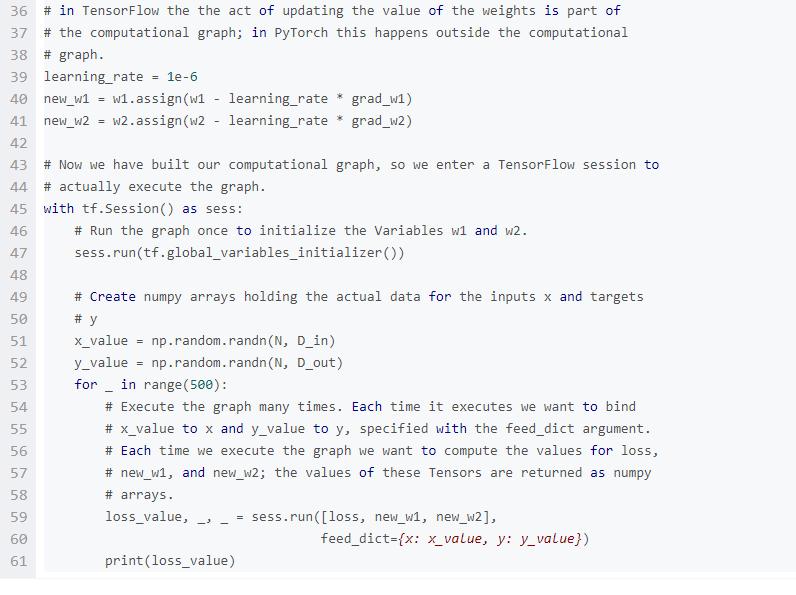
PyTorch自动梯度看起来非常像TensorFlow:在两个框架中,我们都定义计算图,使用自动微分来计算梯度。两者最大的不同就是TensorFlow的计算图是静态的,而PyTorch使用动态的计算图。
在TensorFlow中,我们定义计算图一次,然后重复执行这个相同的图,可能会提供不同的输入数据。而在PyTorch中,每一个前向通道定义一个新的计算图。
静态图的好处在于你可以预先对图进行优化。例如,一个框架可能要融合一些图运算来提升效率,或者产生一个策略来将图分布到多个GPU或机器上。如果你重复使用相同的图,前期优化的消耗就会被分摊开,因为相同的图在多次重复运行。
静态图和动态图的一个不同之处是控制流。对于一些模型,我们希望对每个数据点执行不同的计算。例如,一个递归神经网络可能对于每个数据点执行不同的时间步数,这个展开(unrolling)可以作为一个循环来实现。对于一个静态图,循环结构要作为图的一部分。因此,TensorFlow提供了运算符(例如tf .scan)来把循环嵌入到图当中。对于动态图来说,情况更加简单:既然我们为每个例子即时创建图,我们可以使用正常的解释流控制来为每个输入执行不同的计算。
为了与上面的PyTorch自动梯度实例做对比,我们使用TensorFlow来拟合一个简单的2层网络。

计算图和自动梯度是非常强大的范式,可用于定义复杂的运算符和自动求导数。然而,对于一个大型的网络来说,原始的自动梯度有点太低级别了。
在建立神经网络的时候,我们经常把计算安排在层(layers)中。某些层有可学习的参数,将会在学习中进行优化。
在TensorFlow中,Keras,TensorFlow-Slim和TFLearn这些包提供了原始计算图之上的高级抽象,这对于构建神经网络大有裨益。
在PyTorch中, nn包服务于相同的目的。nn包定义了一系列Modules,大体上相当于神经网络的层。一个Module接收输入Variables,计算输出Variables,但是也可以保持一个内部状态,例如包含了可学习参数的Variables。nn 包还定义了一系列在训练神经网络时常用的损失函数。
在下面例子中,我们使用nn包来实现我们的两层神经网络。


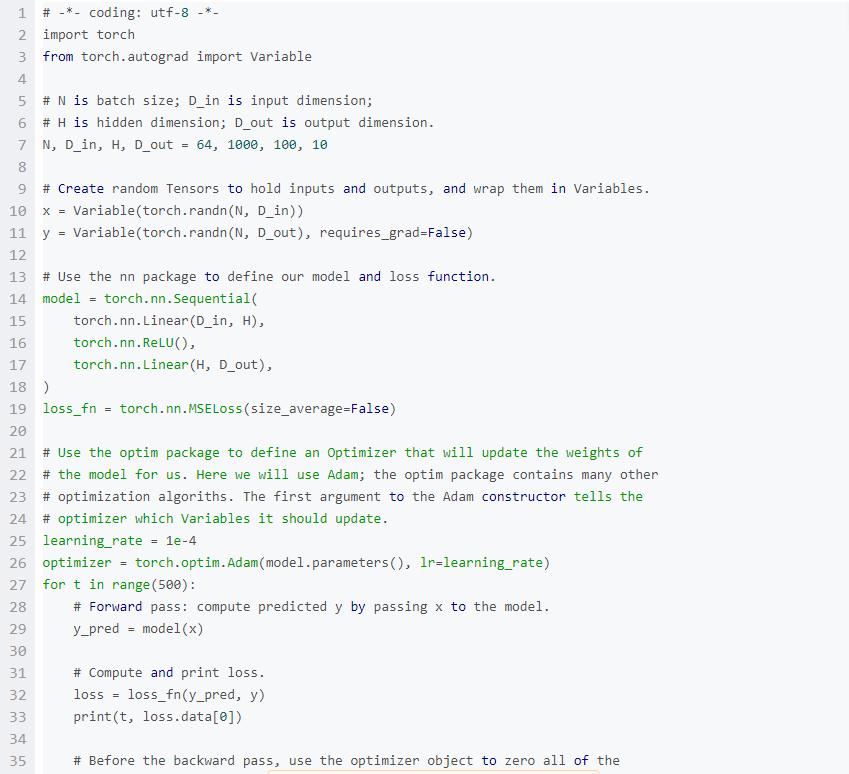
目前,我们已经通过手动改变持有可学习参数的Variables的 .data成员来更新模型的权重。对于简单的优化算法(例如随机梯度下降)来说这不是一个大的负担,但是实际上我们经常使用更加复杂的优化器来训练神经网络,例如AdaGrad, RMSProp, Adam等。
PyTorch的optim包将优化算法进行抽象,并提供了常用的优化算法的实现。
下面这个例子,我们将会使用 nn包来定义模型,使用optim包提供的Adam算法来优化这个模型。

有时候,需要设定比现有模块序列更加复杂的模型。这时,你可以通过生成一个nn.Module的子类来定义一个forward。该forward可以使用其他的modules或者其他的自动梯度运算来接收输入Variables,产生输出Variables。
在这个例子中,我们实现两层神经网络作为一个定制的Module子类。


我们实现一个非常奇怪的模型来作为动态图和权重分享的例子。这个模型是一个全连接的ReLU网络。每一个前向通道选择一个1至4之间的随机数,在很多隐含层中使用。多次使用相同的权重来计算最内层的隐含层。
这个模型我们使用正常的Python流控制来实现循环。在定义前向通道时,通过多次重复使用相同的Module来实现权重分享。
我们实现这个模型作为一个Module的子类。


总结
本文介绍了PyTorch中的重点模块和使用,对于开展之后的实战练习非常重要。所以,我们需要认真练习一下本文的所有模块。最好手敲代码走一遍。
责任编辑:xj
-
深度学习
+关注
关注
73文章
5610浏览量
124654 -
pytorch
+关注
关注
2文章
813浏览量
14930
发布评论请先 登录
PyTorch 中RuntimeError分析
Pytorch 与 Visionfive2 兼容吗?
机器学习和深度学习中需避免的 7 个常见错误与局限性




评论