 在风格迁移中如何进行数据增强
在风格迁移中如何进行数据增强

这是一篇关于风格迁移中如何进行数据增强的论文。在introduction部分,informal-->formal 的风格迁移问题,最大的障碍是训练数据的不足。为了解决此问题,本篇论文提出三种数据增强的方法来获得有用的语句对,分别为
back translation (BT)
我们使用原始语料库训练一个seq2seq模型。其中将formal语句作为模型的输入,让seq2seq模型有能力输出对应的informal句子。则 模型输入的formal语句和输出的informal语句就构成了一个新的语句对。
formality discrimination (F-Dis)
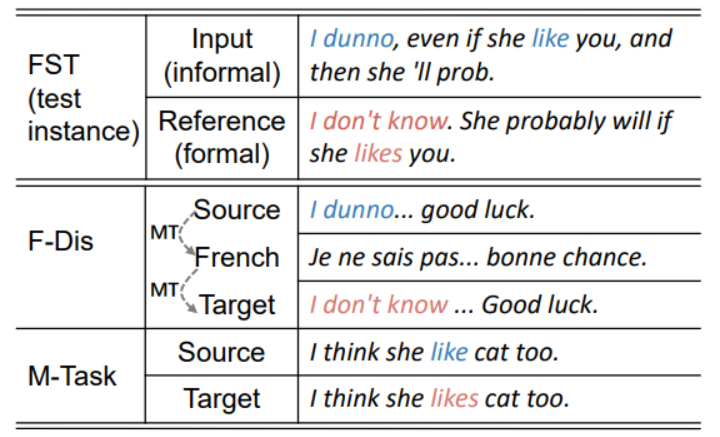
F-Dis方法使用机器翻译模型,将一个informal句子重写为formal句子。首先使用Google翻译API 将这些informal语句翻译成 其他语种(比如法语),然后又翻译回英语。如下图所示:

其中,informal语句可以从网上论坛上收集得到。
表示收集到的第i条句子(informal), 是最后翻译回的句子(formal), 二者构成了一个新的语句对。
本方法同时使用CNN构建了一个“格式判别器”:用来给一个句子的“正规”程度 打分。就是上图中右边括号内的小数。最终选出的新数据集要求如下:
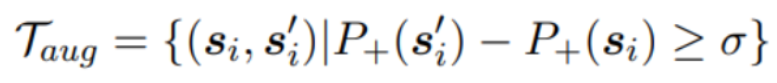
其中表示句子的“正规”程度, 是阈值
multi-task transfer (M-Task)
我们观察到,formal语句通常语法正确,而informal语句的语法经常出错。
前人研究表明,对FST的输出再使用一个语法错误纠正模型( grammatical error correction model,GEC)可以提高模型效果。受此启发,本论文直接使用GEC的训练数据作为增强的新数据集。如下图
模型训练
上面提到的seq2seq模型为Transformer (base)。
本论文首先使用增强的新数据用于 预训练,然后使用原始语料数据做微调,将这称为pre-training & finetuning (PT&FT)方法。下面结果证明了PT&FT的效果优于ST方法。ST是把增强数据和原数据一起训练。
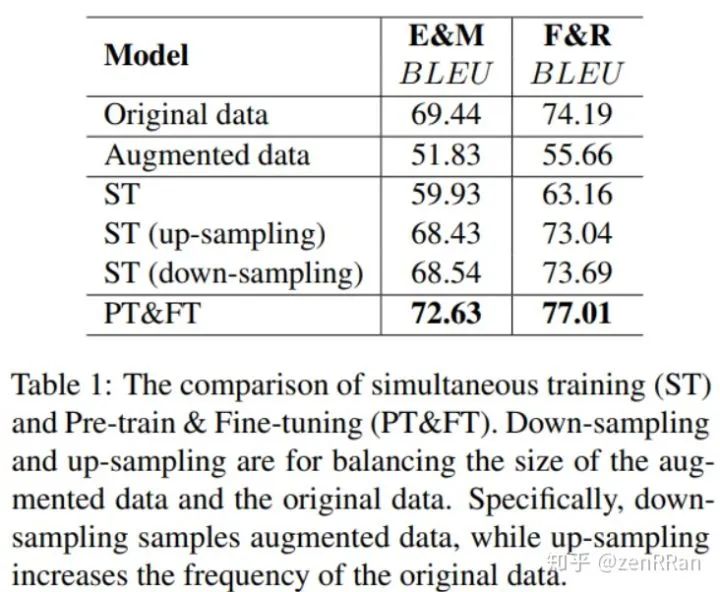
下图展现了三种数据增强方法的效果:
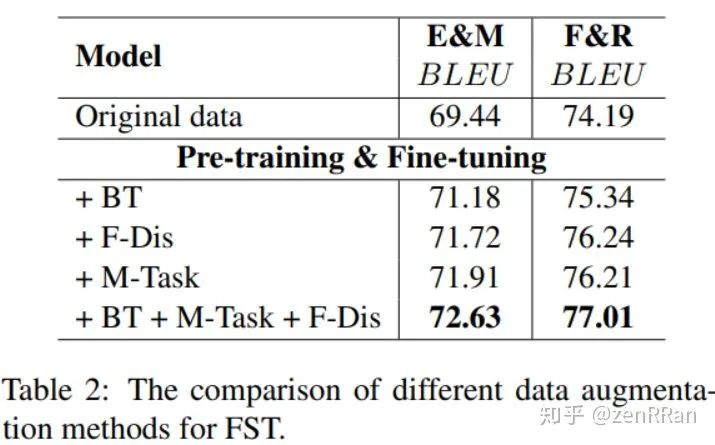
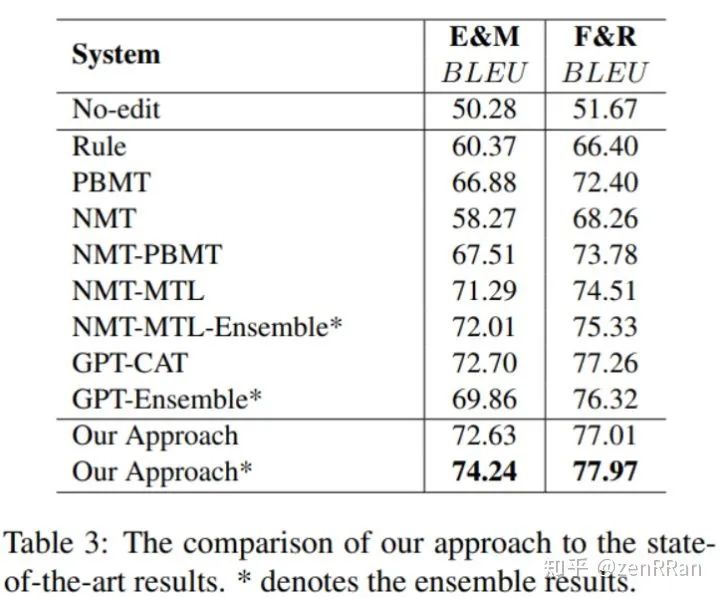
下图展现了我们的方法与前人模型的比较结果:
责任编辑:xj
原文标题:【ACL2020】关于正式风格迁移的数据增强方法
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
数据
+关注
关注
8文章
7349浏览量
95028 -
机器学习
+关注
关注
67文章
8566浏览量
137234 -
自然语言处理
+关注
关注
1文章
630浏览量
14726
原文标题:【ACL2020】关于正式风格迁移的数据增强方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
通过对数字音频信号进行数学运算和算法处理的高性能Audio DSP-DU562

zfs数据恢复—ZFS存储迁移数据读不出数据怎么恢复数据?
设备PLC没有以太网口如何进行数据采集
无质量损失的数据迁移:Nikon SLM Solutions信赖3Dfindit企业版
温度循环测试后如何进行数据记录和分析?
如何使用运行数据趋势分析验证装置准确性?

工业数据中台在智能制造中的作用
宏集方案 | 如何进行产线高阶能耗数据的计算和可视化?

中软国际上云迁移服务充分释放云计算价值
使用Cypress FX2 EZ USB进行数据采集应用,为什么采集到的数据不是连续的?
三菱CNC如何进行数据采集并对接到ERP系统




评论