 如何搭建NLP经典模型(含代码)
如何搭建NLP经典模型(含代码)
之前整理过斋藤康毅的深度学习神作《深度学习入门:基于Python的理论与实现》,对小白非常友好,它没有用任何的现成框架(比如pyTorch、tensorFlow等等),而是直接用python自带的库手把手教你,从如何实现梯度下降开始到手磕一个CNN经典网络,让你不再对深度学习框架的内部机制感到神秘。
短短几年,这位大佬再度出了“续集”—《深度学习进阶:自然语言处理》[1]!(可以说是NLP入门必读的经典著作了!)
小斋这次的写作风格和前作一样,都是手把手教你从实现词向量开始,像搭积木一样,再到如何实现经典网络NLP届的界的经典网络RNN、LSTM、seq2seq和Attention等NLP中重要的深度学习技术。
(太感人了,这次终于要搞懂词向量究竟是个什么鬼了!(逃
凡我不能创造的,我就不能理解。
— 理查德·费曼(致敬费曼)
话不多说,这次我不再整理的和上个系列一样那么详细(繁冗)了(个人觉得没必要,那样整理还不如直接看书来的直接痛快。所以这一次我会摘取基础又重要的部分,如果你想再详细深究下去,乖,去参考原书噢!
本书用到的库:
Numpy
Matplotlib
(真的是只用了这两个基本库!(强
如果要用GPU加速运算的话,再加一个CuPy库。
作者强调,自己动手的经验、花时间思考的经验,都是无法复制的。(所以,听话,要自己尝试敲1敲代码噢!
本书第一章为上一本书神经网络的复习,咱直接跳到第二章 从词向量开始
正文开始
目录
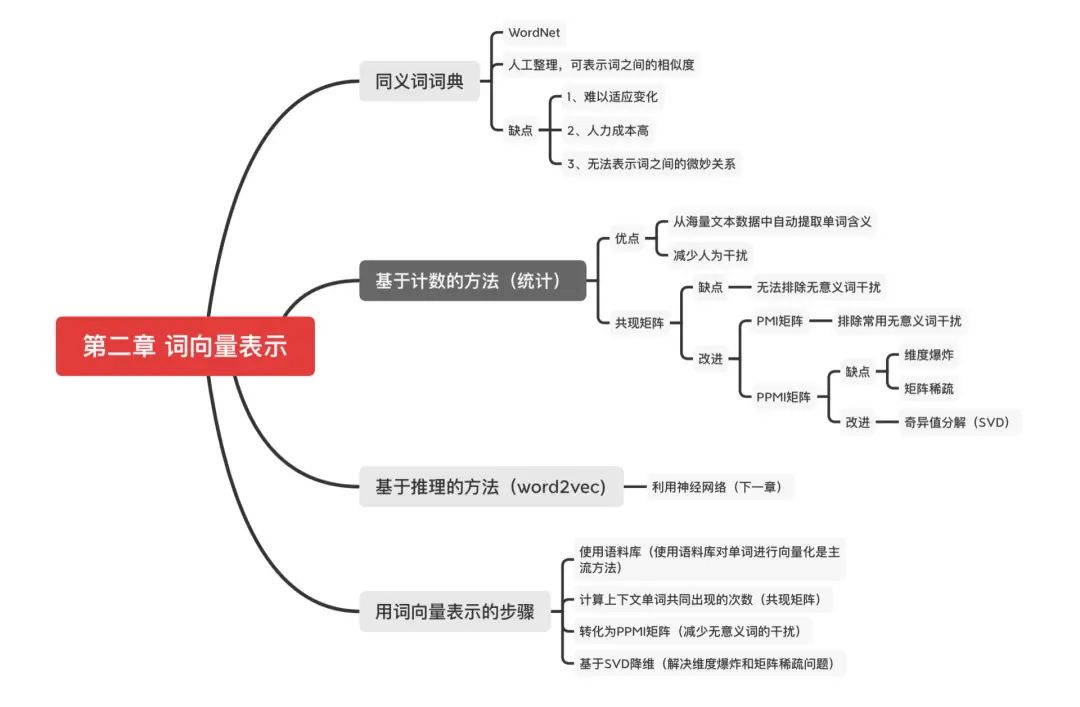
什么是自然语言处理?
同义词词典
基于计数的方法
基于计数的方法改进
必做练习
-
语料库的预处理。实现分词(将文本分割成单词,以单词为最小单元输入给模型)
-
单词ID化(将单词用ID来表示,相当于给每一个单词编个代号,和我们学生编个学号一个意思,方便定位和管理呗)
-
利用共现矩阵表示文本的词向量。
(这些练习会在后续搭建模型的时候用得到噢!相当于我们先造积木,之后搭网络就有素材啦!本章的词向量表示也就是对文本进行预处理的准备工作!)
注意:全文的讲解都是以
(存在一个问题 —> 找到解决办法 —> 新的解决办法又有什么问题 —> 又找到解决办法 )的思路一步一步引出各种概念和解决方案的。
我们的学习过程也是如此,市面上突然出现的各种模型也是如此,了解它解决了什么问题也就知道乱七八糟的各种模型为什么会出现了。
什么是自然语言处理?
-
自然语言:就是我们平常使用的语言,如汉语、英语;
-
自然语言处理:就是让机器理解人类的语言,理解了人类语言才能对我们的语言进行进一步解读和分析!(比如对人类的情感进行分析、对文本进行分类、能够实现人机对话等等)
在没有深度学习的时候,专家们是这样进行词向量的表示的:
同义词词典
最著名的同义词词典当属WordNet [2]啦。WordNet等同义词词典中对大量单词人工的定义了同义词和层级结构关系等。
同义词词典存在的问题
-
难以顺应时代的变化。语言是活的,新词会不断出现。
-
人力成本高,WordNet收录了超过20W个单词。
-
无法表示单词的微妙差异。即使是含义相近的单词,也有细微的差别。比如,vintage 和retro(类似复古的意思)虽然表示相同的含义,但是用法不同,而这种细微的差别在同义词词典中是无法表示出来的(让人来解释是相当困难的)。
Marty:“This is heavy (棘手).”
Dr. Brown:“In the future, things are so heavy (重)?”
— 电影《回到未来》
在电影《回到未来》中,有这样一个场景:从1985 年穿越回来的马蒂和生活在1955年的的博士的对话中,对“heavy”的含义有不同的理解。如果要处理这样的单词变化,就需要人工不停地更新同义词词典。
基于计数的方法(基于统计)
目标:从海量文本数据中自动提取单词含义,减少人为干扰。
-
语料库(corpus):就是我们输入模型的大量文本,比如句子、文章等等。
这里将用一句话作为语料库来阐述接下来的所有概念。
> text = 'you say goodbye and I say hello.'
语料库的预处理
1、进行句子的分词,并标记每个单词的ID。(就像给每个学生编上学号ID一样,方便后续指定某一个学生呀!)
>>>text=text.lower()//将所有单词转化为小写>>>text=text.replace('.','.')//使句号其和前一个单词分开>>>text'yousaygoodbyeandisayhello.'>>>words=text.split('')//切分句子>>>words['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.'] //由八个词组成的数组
首先,使用lower()方法将所有单词转化为小写,这样可以将句子开头的单词也作为常规单词处理。然后,将空格作为分隔符,通过split(' ')切分句子。考虑到句子结尾处的句号(.),我们先在句号前插人一个空格(即用 ' .'替换'.'),再进行分词。
2、我们进一步给单词标上 ID,以便使用单词 ID 列表,方便为后续对每个单词进行操作。
将单词列表转化为单词 ID 列表,然后再将其转化为 NumPy 数组。
word_to_id={}//将单词转化为单词IDid_to_word={}//将单词ID转化为单词(键是单词ID,值是单词)forwordinwords:ifwordnotinword_to_id://如果单词不在word_to_id中,则分别向word_to_id和id_to_word添加新ID和单词new_id=len(word_to_id)word_to_id[word]=new_idid_to_word[new_id] = wordcorpus = np.array([word_to_id[w] for w in words])
如果单词不在 word_to_id 中,则分别向 word_to_id 和id_to_word 添加新 ID 和单词
如下为创建好了单词 ID 和单词的对应表
>id_to_word{0:'you',1:'say',2:'goodbye',3:'and',4:'i',5:'hello',6:'.'}>word_to_id{'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}
最后,我们将单词列表转化为单词 ID 列表,然后再将其转化为 NumPy 数组。
>corpusarray([0, 1, 2, 3, 4, 1, 5, 6])
将第一步和第二步封装为一个preprocess() 函数,使用这个函数,可以按如下方式对语料库进行预处理。( 代码在common/util.py)
输入要处理的语料库text,输出corpus, word_to_id, id_to_word
> text = 'You say goodbye and I say hello.'>corpus,word_to_id,id_to_word=preprocess(text)
corpus 是单词ID 列表,word_to_id 是单词到单词 ID 的字典,id_to_word 是单词 ID 到单词的字典。
语料库的预处理已完成。这里准备的 corpus、word_to_id 和 id_to_word 这 3 个变量名在本书接下来的很多地方都会用到。
接下来的目标就是使用语料库提取单词含义,这里先使用基于计数的方法,也就是基于统计的方法,能够得到词向量!(也就是将单词表示为向量)
分布式假说(distributional hypothesis)
-
分布式假说(distributional hypothesis):某个单词的含义由它周围的单词形成。(某个人存在的价值由它的社会属性构成。—我瞎说的)
单词本身没有含义,单词含义由它所在的上下文(语境)形成。
比如“I drink beer.” “We drink wine.” , drink 的附近常有饮料出现。
另外,从“I guzzle beer.” “We guzzle wine.”可知,guzzle 和 drink 所在的语境相似。进而我们可以推测出guzzle 和 drink 是近义词(guzzle 是“大口喝”的意思) 。
基于这一假说,我们就可以通过单词的上下文来表示该单词。如图,左侧和右侧的 2 个单词就是上下文。

这里的窗口大小可以控制你需要关心多少单词的上下文。显而易见,关心的上下文单词数越多,单词的含义越准确,但是所需要的存储量就越大,看你自己的取舍咯!这里简单起见,窗口大小为1。
如何基于分布式假设使用向量表示单词,最直截了当的实现方法是对周围单词的数量进行计数。
共现矩阵(co-occurrence matrix)
-
共现矩阵(co-occurrence matrix):用上下文共同出现的单词次数作为该单词的向量。即若两个单词挨着出现一次,次数加一。
上面已经处理好语料库了,接下来构建共现矩阵,也就是计算每个单词的上下文所包含的单词的频数。在这个例子中,我们将窗口大小设为 1,从单词 ID 为 0 的 you 开始。
单词 you 的上下文仅有 say 这个单词,如下图所示。

所以单词you可表示为:
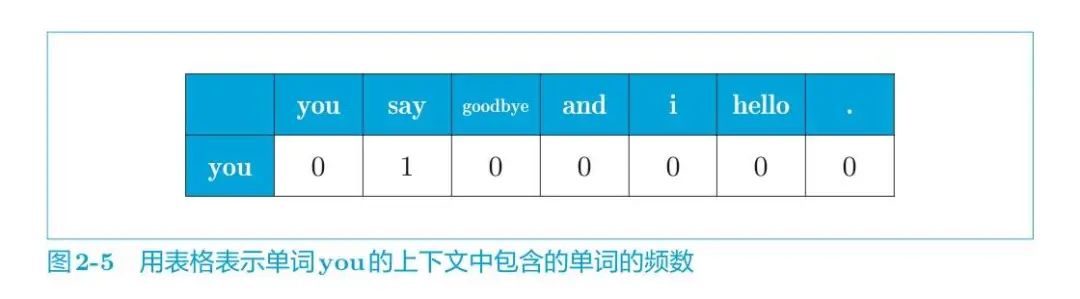
即可以用向量 [0, 1, 0, 0, 0, 0, 0] 表示单词 you。其他单词也是重复如此操作。

于是得到了共现矩阵:
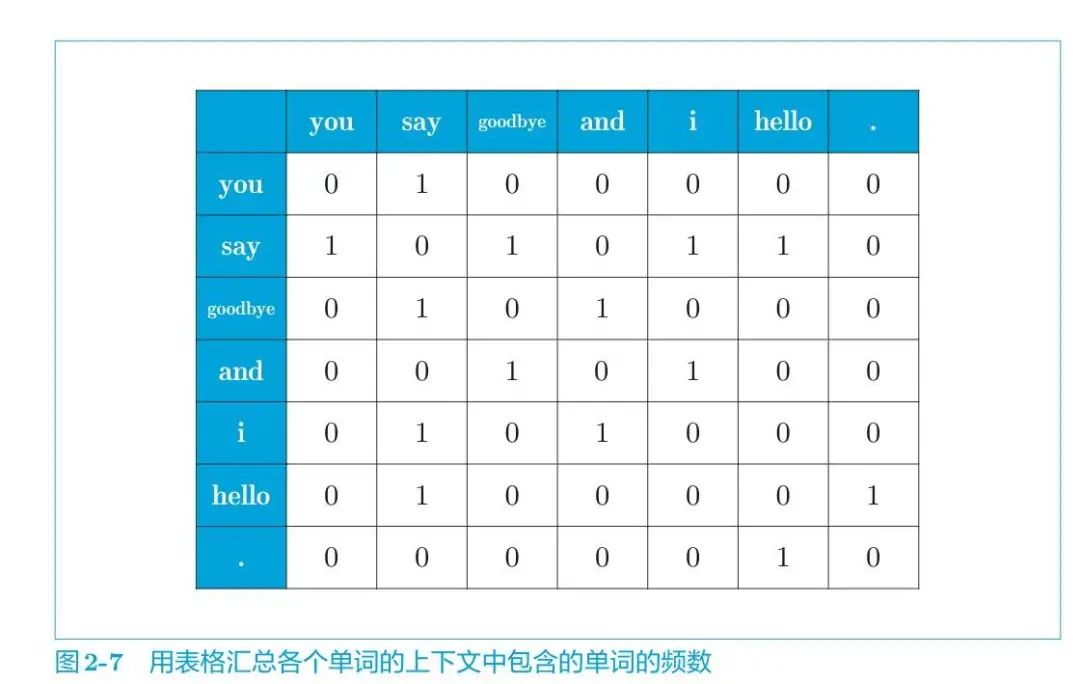
接下来,我们来实际创建一下上面的共现矩阵。
将图 2-7 的结果按原样手动输入。
C=np.array([[],[],[],[],[],[],[], ], dtype=np.int32)
这就是共现矩阵。使用这个共现矩阵,可以获得各个单词的向量,如下所示。
print(C[0])#单词ID为0的向量#[0100000]print(C[4])#单词ID为4的向量#[0101000]print(C[word_to_id['goodbye']])#goodbye的向量# [0 1 0 1 0 0 0]
我们通过共现矩阵成功地用向量表示了单词。但手动输入共现矩阵太麻烦,这一操作显然可以自动化。下面,我们来实现一个能直接从语料库生成共现矩阵的函数。
通过函数create_co_matrix()能直接从语料库生成共现矩阵。(代码实现在common/util.py)
其中参数 corpus 是单词 ID 列表,参数 vocab_ size 是词汇个数,window_size 是窗口大小。
defcreate_co_matrix(corpus,vocab_size,window_size=1):corpus_size=len(corpus)co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)foridx,word_idinenumerate(corpus):foriinrange(1,window_size+1):left_idx=idx-iright_idx=idx+iifleft_idx>=0:left_word_id=corpus[left_idx]co_matrix[word_id,left_word_id]+=1ifright_idx< corpus_size:right_word_id=corpus[right_idx]co_matrix[word_id,right_word_id]+=1return co_matrix
首先,用元素为 0 的二维数组对 co_matrix 进行初始化。然后,针对语料库中的每一个单词,计算它的窗口中包含的单词。同时,检查窗口内的单词是否超出了语料库的左端和右端。
这样一来,无论语料库多大,都可以自动生成共现矩阵。之后,我们都将使用这个函数生成共现矩阵。
到这里我们终于第一次成功的用向量表示单词啦!将正式迈入文本词向量表示的道路!
写到这发现篇幅太长了,为了能有更好的学习体验,接下来共现矩阵存在的问题以及改进方式就下一篇再见啦!
责任编辑:xj
原文标题:小白跟学系列之手把手搭建NLP经典模型(含代码)
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
模型
+关注
关注
1文章
3229浏览量
48813 -
自然语言处理
+关注
关注
1文章
618浏览量
13553 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:小白跟学系列之手把手搭建NLP经典模型(含代码)
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
超级干货!本地搭建代码托管平台Gitea

AI大模型在自然语言处理中的应用
用TINA如何搭建仿真模型?
在PyTorch中搭建一个最简单的模型
经典卷积网络模型介绍
nlp逻辑层次模型的特点
nlp神经语言和NLP自然语言的区别和联系
nlp自然语言处理基本概念及关键技术
llm模型有哪些格式
nlp自然语言处理模型怎么做
nlp自然语言处理模型有哪些
NLP模型中RNN与CNN的选择
使用PyTorch搭建Transformer模型
使用VeriStand搭建MIL测试环境





 工商网监
工商网监
评论