 NLP事件抽取综述之挑战与展望
NLP事件抽取综述之挑战与展望
本系列文章主要分享近年来事件抽取方法总结,包括中文事件抽取、开放域事件抽取、事件数据生成、跨语言事件抽取、小样本事件抽取、零样本事件抽取等。主要包括以下几大部分:
定义(Define)
综述(Survey)
模型(Models)
数据集(Datasets)
挑战与展望(Future Research Challenges)
Github地址:https://github.com/xiaoqian19940510/Event-Extraction
Few-shot or zero-shot
2020
Meta-Learning with Dynamic-Memory-Based Prototypical Network for Few-Shot Event Detection, WSDM 2020[1]
事件检测(ED)是事件抽取的一个子任务,涉及到识别触发器和对提到的事件进行分类。现有的方法主要依赖于监督学习,并需要大规模的标记事件数据集,不幸的是,这些数据集在许多实际应用中并不容易获得。
在这篇论文中,考虑并重新制定了一个有限标记数据的教育任务作为一个少样本的学习问题。提出了一个基于动态记忆的原型网络(DMB-PN),它利用动态记忆网络(DMN)不仅可以更好地学习事件类型的原型,还可以为提到事件生成更健壮的句子编码。传统的原型网络只使用一次事件提及次数,通过平均计算事件原型,与之不同的是,由于DMNs的多跳机制,我们的模型更加健壮,能够从多次提及的事件中提取上下文信息。
实验表明,与一系列基线模型相比,DMB-PN不仅能更好地解决样本稀缺问题,而且在事件类型变化较大、实例数量极小的情况下性能更强。
Exploiting the Matching Information in the Support Set for Few Shot Event Classification, PAKDD 2020[2]
现有的事件分类(EC)的工作主要集中在传统的监督学习设置,其中模型无法提取的事件提到新的/看不见的事件类型。尽管EC模型能够将其操作扩展到未观察到的事件类型,但在这一领域还没有研究过少样本习。为了填补这一空白,在本研究中,我们调查了在少样本学习设置下的事件分类。
针对这一问题们提出了一种新的训练方法,即在训练过程中扩展利用支持集。特别地,除了将查询示例与用于训练的支持集中的示例进行匹配之外,我们还试图进一步匹配支持集中本身的示例。该方法为模型提供了更多的训练信息,可应用于各种基于度量学习的少样本学习方法。我们在两个EC基准数据集上的广泛实验表明,该方法可以提高事件分类准确率达10%
Towards Few-Shot Event Mention Retrieval : An Evaluation Framework and A Siamese Network Approach, LREC 2020[3]
在大量的文本中自动分析事件对于情境意识和决策是至关重要的。以前的方法将事件抽取视为“一刀切”,并预先定义了本体。所建立的提取模型用于提取本体中的类型。这些方法不能很容易地适应新的事件类型或感兴趣的新领域。
为了满足以事件为中心的个性化信息需求,本文引入了少样本事件提及检索(EMR)任务:给定一个由少量事件提及组成的用户提供的查询,返回在语料库中找到的相关事件提及。这个公式支持“按例查询”,这大大降低了指定以事件为中心的信息需求的门槛。检索设置还支持模糊搜索。我们提供了一个利用现有事件数据集(如ACE)的评估框架。
2018
Zero-Shot Transfer Learning for Event Extraction, ACL 2018[4]
以前的大多数事件抽取研究都严重依赖于从标注的事件提及中衍生出来的特性,因此如果不进行注释就不能应用于新的事件类型。在这项工作中,我们重新审视事件抽取,并将其建模为一个接地问题。我们设计一个Transfer的神经结构,映射事件提及和类型共同到一个共享语义空间使用神经网络结构和组成,每个事件提及的类型可以由所有候选人的最亲密的类型。
通过利用一组现有事件类型可用的手工标注和现有事件本体,我们的框架应用于新的事件类型而不需要额外的标注。在现有事件类型(如ACE、ERE)和新事件类型(如FrameNet)上的实验证明了我们的方法的有效性。对于23种新的事件类型,我们的zero-shot框架实现了可以与最先进的监督模型相比较的性能,该模型是从500个事件提及的标注数据中训练出来的。
中文事件抽取
2019
Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction, EMNLP2019 [5]
任务: 与其他研究不同,该任务被定义为:事件框架填充:也就是论元检测+识别
不同点有:不需要触发词检测;文档级的抽取;论元有重叠
动机: 解码论元需要一定顺序,先后有关
主要思想:发布数据集,具有特性:arguments-scattering and multi-event,先对事件是否触发进行预测;然后,按照一定顺序先后来分别解码论元
数据集:ten years (2008-2018) Chinese financial announcements:ChFinAnn;
Cross-lingual Structure Transfer for Relation and Event Extraction, EMNLP 2019) [6]
动机:从资源不足以及注释不足的语料库中进行复杂语义结构的识别(例如事件和实体关系)是很困难的,这已经变成了一个很有挑战性的信息抽取任务。
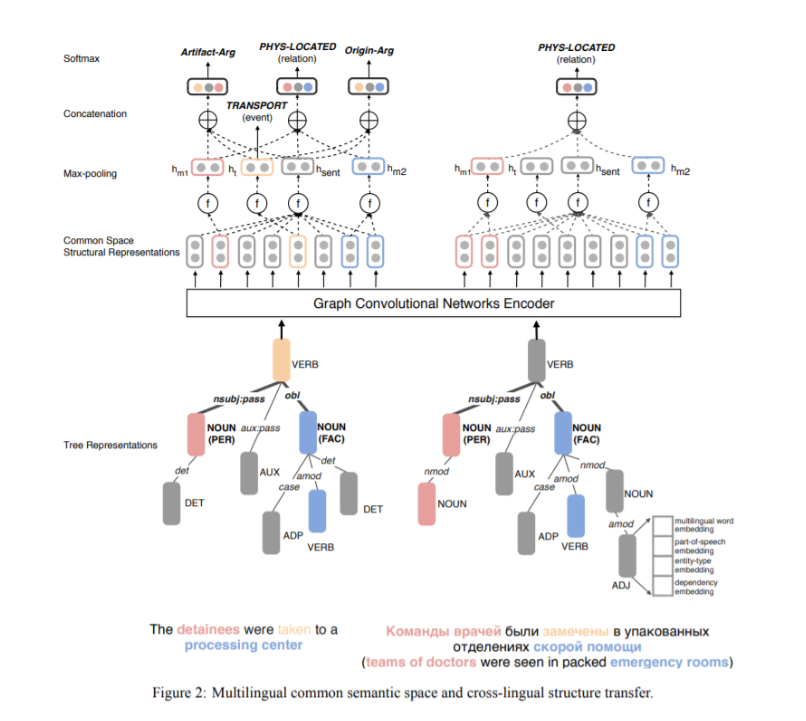
主要思想:通过使用卷积神经网络,将所有实体信息片段、事件触发词、事件背景放入一个复杂的、结构化的多语言公共空间,然后我们可以从源语言注释中训练一个事件抽取器,并将它应用于目标语言。
数据集:ACE2005
2018
DCFFE: A Document-level Chinese Financial Event Extraction System based on Automatically Labelled Training Data, ACL 2018 [7]
动机:在某些特定领域,例如金融,医疗和司法领域,由于数据标记过程的成本很高,因此标记数据不足。此外,当前大多数方法都关注于从一个句子中提取事件,但通常在一个文档中,一个事件由多个句子表示。我们提出一种方法来解决这个问题。
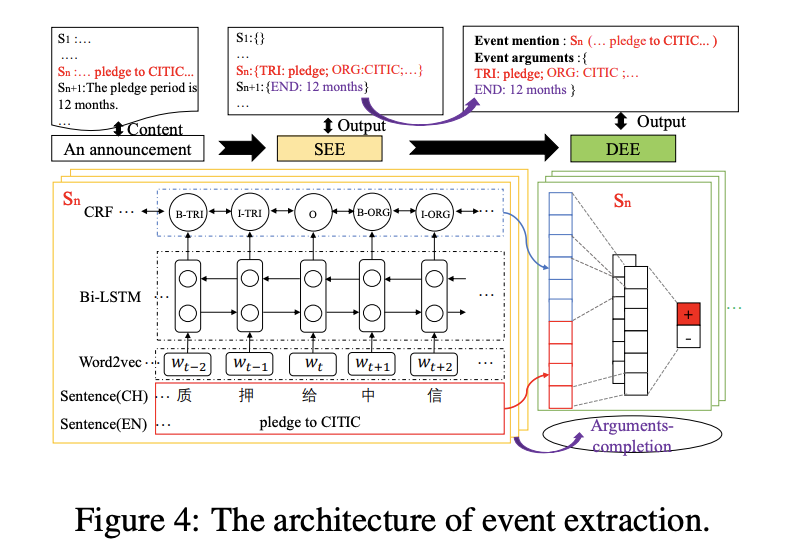
主要思想:我们提供了一个名为DCFEE的框架,该框架可以从被自动标记过的训练数据中抽取文档级事件。我们使用一个序列标记模型来自动抽取句子级事件,并且提出了一个关键事件检测模型和一个论元填充策略,进而从文档中提取整个事件。
数据集:Chinese financial event dataset
2016
A convolution bilstm neural network model for chinese event extraction, NLPCC 2016 [8]
动机:在中文的事件抽取中,以前的方法非常依赖复杂的特征工程以及复杂的自然语言处理工具。本文提出了一种卷积双向LSTM神经网络,该神经网络将LSTM和CNN结合起来,可以捕获句子级和词汇信息,而无需任何人为提供的特征。
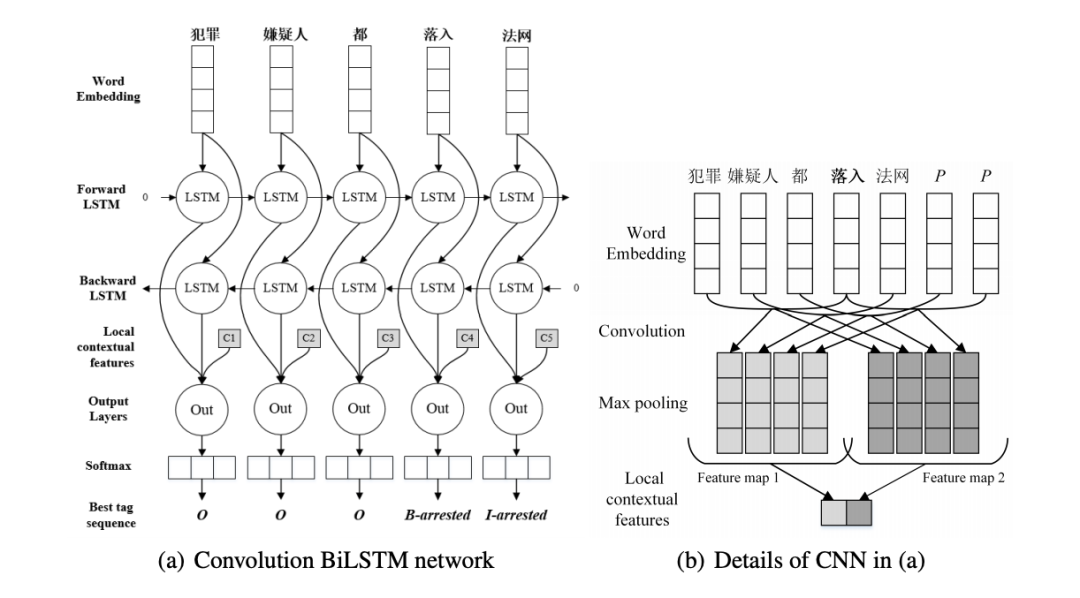
主要思想:首先使用双向LSTM将整个句子中的单词的语义编码为句子级特征,不做任何句法分析。然后,我们利用卷积神经网络来捕获突出的局部词法特征来消除触发器的歧义,整个过程无需来自POS标签或NER的任何帮助。
数据集:ACE2005, KBP2017 Corpus
半监督远程监督事件抽取
2018
Semi-supervised event extraction with paraphrase clusters, NAACL 2018[9]
动机:受监督的事件抽取系统由于缺乏可用的训练数据而其准确性受到限制。我们提出了一种通过对额外的训练数据进行重复抽样来使事件抽取系统自我训练的方法。这种方法避免了训练数据缺乏导致的问题。
主要思想:我们通过详细的事件描述自动生成被标记过的训练数据,然后用这些数据进行事件触发词识别。具体来说,首先,将提及该事件的片段聚集在一起,形成一个聚类。然后用每个聚类中的简单示例来给整个聚类贴一个标签。最后,我们将新示例与原始训练集结合在一起,重新训练事件抽取器。
数据集:ACE2005, TAC-KBP 2015
开放域事件抽取
2020
Open-domain Event Extraction and Embedding for Natural Gas Market Prediction, arxiv 2020
动机:以前的方法大多数都将价格视为可推断的时间序列,那些分析价格和新闻之间的关系的方法是根据公共新闻数据集相应地修正其价格数据、手动注释标题或使用现成的工具。与现成的工具相比,我们的事件抽取方法不仅可以检测现象的发生,还可以由公共来源检测变化的归因和特征。
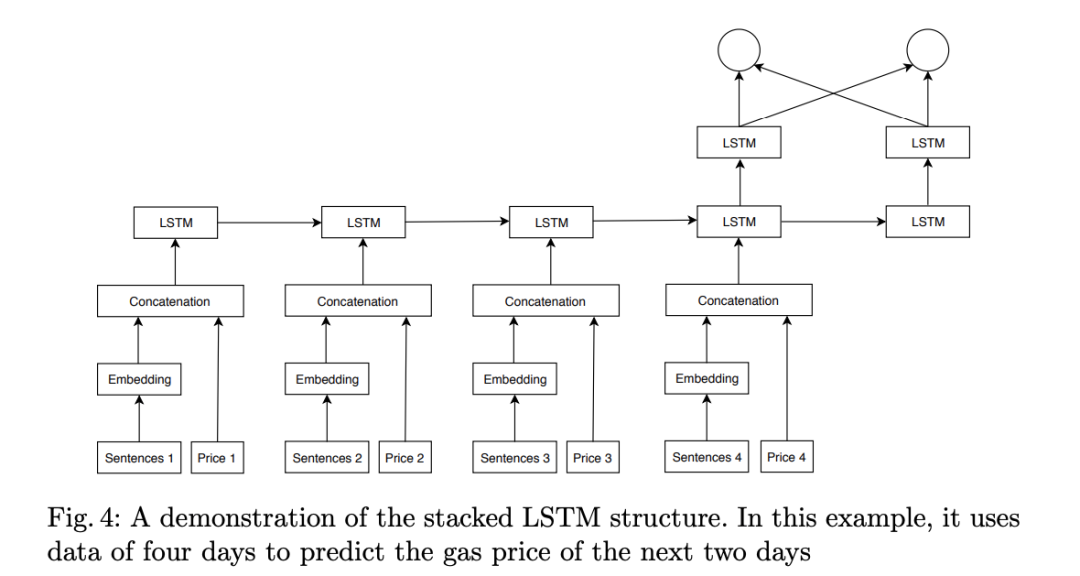
主要思想:依靠公共新闻API的标题,我们提出一种方法来过滤不相关的标题并初步进行事件抽取。价格和文本均被反馈到3D卷积神经网络,以学习事件与市场动向之间的相关性。
数据集:NYTf、FT、TG
2019
Open Domain Event Extraction Using Neural Latent Variable Models, ACL2019 [10]
动机:我们考虑开放领域的事件抽取,即从新闻集群中抽取无约束的事件类型的任务。结果表明,与最新的事件模式归纳方法相比,这种无监督模型具有更好的性能。
主要思想:以前关于生成模式归纳的研究非常依赖人工生成的指标特征,而我们引入了由神经网络产生的潜在变量来获得更好的表示能力。我们设计了一种新颖的图模型,该模型具有潜在的事件类型矢量以及实体的文本冗余特征,而这些潜在的事件类型矢量来自全局参数化正态分布的新闻聚类。
数据集:GNBusiness
Reporting the unreported: Event Extraction for Analyzing the Local Representation of Hate Crimes, EMNLP 2019[11]
动机:将事件抽取和多实例学习应用于本地新闻文章的语料库,可以用来预测仇恨犯罪的发生。
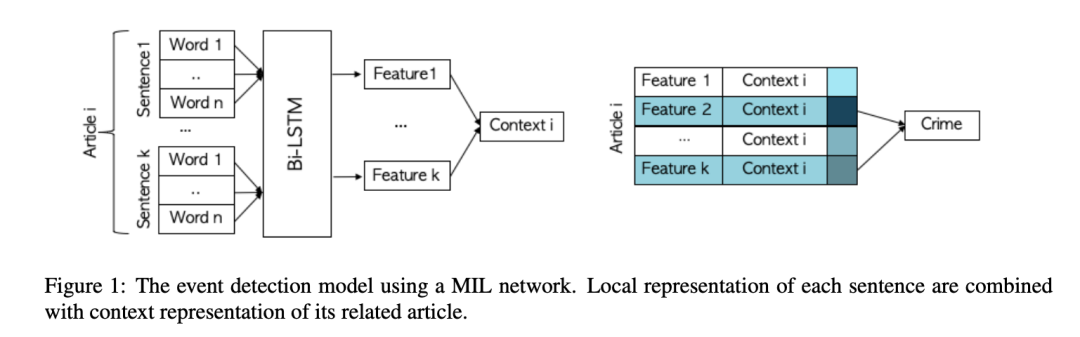
主要思想:根据是否为仇恨罪标记每篇文章的任务被定义为多实例学习(MIL)问题。我们通过使用文章所有句子中嵌入的信息来确定文章是否报道了仇恨犯罪。在一组带注释的文章上测试了模型之后,我们将被训练过的模型应用于联邦调查局没有报道过的城市,并对这些城市中仇恨犯罪的发生频率进行了下界估计。
多语言事件抽取
2019
Cross-lingual Structure Transfer for Relation and Event Extraction, EMNLP 2019) [12]
动机:从资源不足以及标注不足的语料库中进行复杂语义结构的识别(例如事件和实体关系)是很困难的,这已经变成了一个很有挑战性的信息抽取任务。
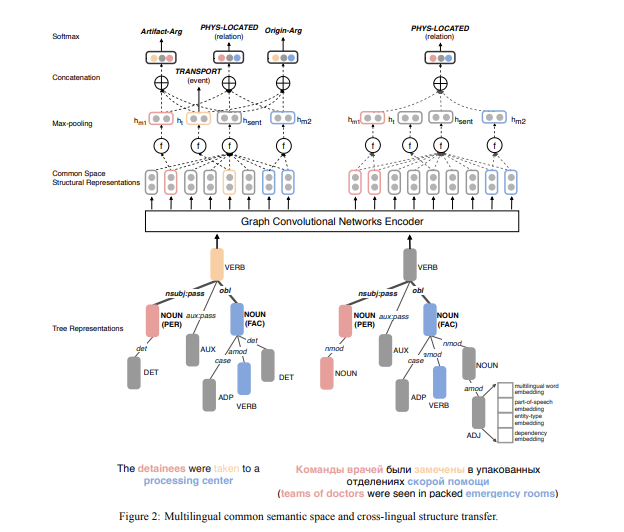
主要思想:通过使用卷积神经网络,将所有实体信息片段、事件触发词、事件背景放入一个复杂的、结构化的多语言公共空间,然后我们可以从源语言标注数据中训练一个事件抽取器,并将它应用于目标语言。
数据集:ACE2005
2016
Leveraging Multilingual Training for Limited Resource Event Extraction, COLING 2016[13]
动机:迄今为止,利用跨语言训练来提高性能的工作非常有限。因此我们提出了一种新的事件抽取方法。
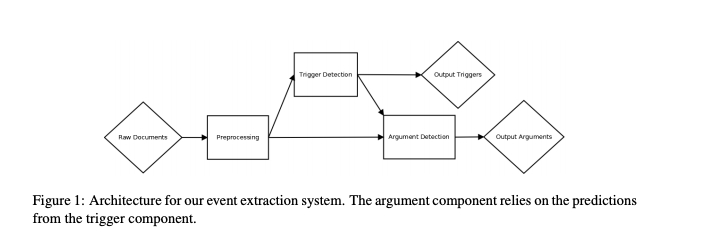
主要思想:在本文中,我们提出了一种新颖的跨语言事件抽取方法,该方法可在多种语言上进行训练,并利用依赖于语言的特征和不依赖于语言的特征来提高性能。使用这种系统,我们旨在同时利用可用的多语言资源(带标注的数据和引入的特征)来克服目标语言中的标注数据稀缺性问题。从经验上我们认为,我们的方法可以极大地提高单语系统对中文事件论元提取任务的性能。与现有工作相比,我们的方法是新颖的,我们不依赖于使用高质量的机器翻译的或手动对齐的文档,这因为这种需求对于给定的目标语言可能是无法满足的。
数据集:ACE2005
数据生成
2019
Exploring Pre-trained Language Models for Event Extraction and Geenration, ACL 2019[14]
动机:ACE事件抽取任务的传统方法通常依赖被手动标注过的数据,但是手动标注数据非常耗费精力并且也限制了数据集的规模。我们提出了一个方法来克服这个问题。
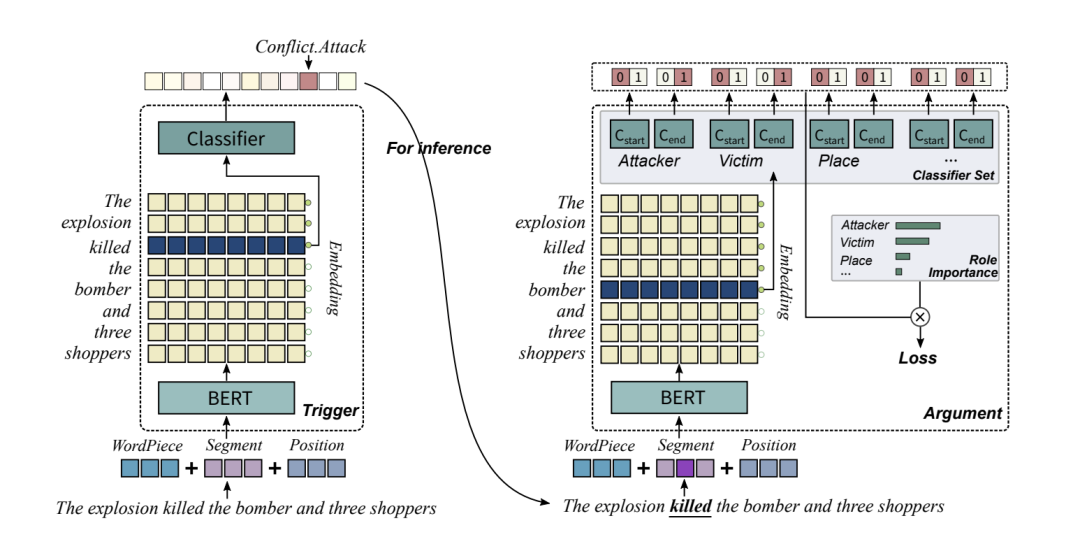
主要思想:本文提出了一个基于预训练语言模型的框架,该框架包含一个作为基础的事件抽取模型以及一种生成被标注事件的方法。我们提出的事件抽取模型由触发词抽取器和论元抽取器组成,论元抽取器用前者的结果进行推理。此外,我们根据角色的重要性对损失函数重新进行加权,从而提高了论元抽取器的性能。
数据集:ACE2005
Open Event Extraction from Online Text using a Generative Adversarial Network, EMNLP 2019 [15]
动机:提取开放域事件的结构化表示的方法通常假定文档中的所有单词都是从单个事件中生成的,因此他们通常不适用于诸如新闻文章之类的长文本。为了解决这些局限性,我们提出了一种基于生成对抗网络的事件抽取模型,称为对抗神经事件模型(AEM)。
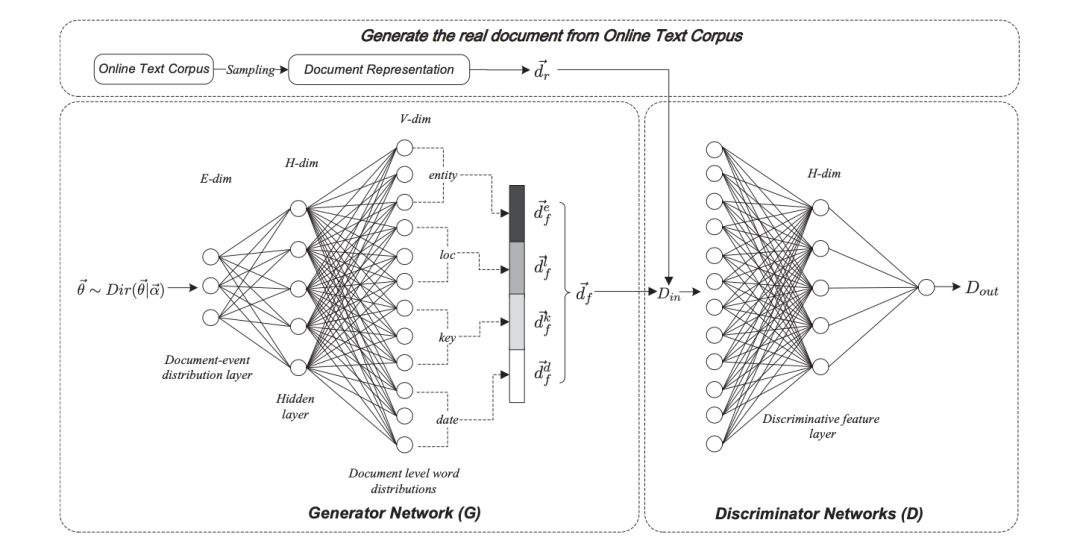
主要思想:AEM使用Dirichlet先验对事件建模,并使用生成器网络来捕获潜在事件的模式。鉴别符用于区分原始文档和从潜在事件中重建的文档。鉴别器的副产品是鉴别器网络生成的特征允许事件抽取的可视化。
数据集:Twitter, and Google datasets
Reporting the unreported: Event Extraction for Analyzing the Local Representation of Hate Crimes, EMNLP 2019[16]
动机:将事件抽取和多实例学习应用于本地新闻文章的语料库,可以用来预测仇恨犯罪的发生。
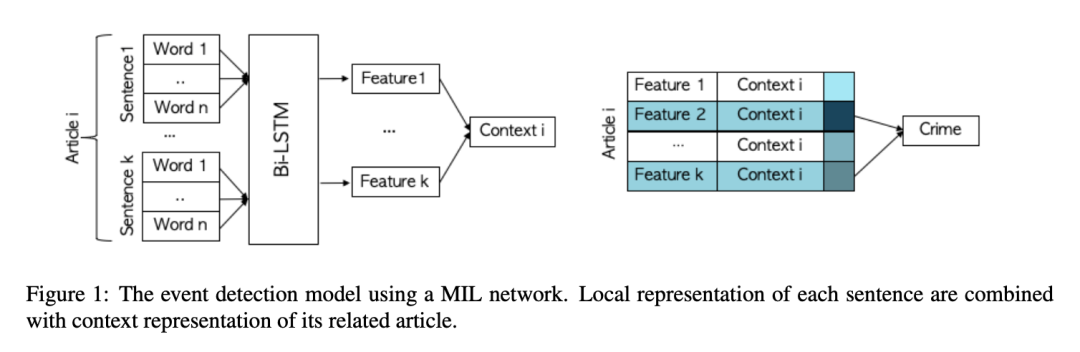
主要思想:根据是否为仇恨罪标记每篇文章的任务被定义为多实例学习(MIL)问题。我们通过使用文章所有句子中嵌入的信息来确定文章是否报道了仇恨犯罪。在一组带标注数据的文章上测试了模型之后,我们将被训练过的模型应用于联邦调查局没有报道过的城市,并对这些城市中仇恨犯罪的发生频率进行了下界估计。
2017
Automatically Labeled Data Generation for Large Scale Event Extraction, ACL 2017 [17]
动机:手动标记的训练数据成本太高,事件类型覆盖率低且规模有限,这种监督的方法很难从知识库中抽取大量事件。
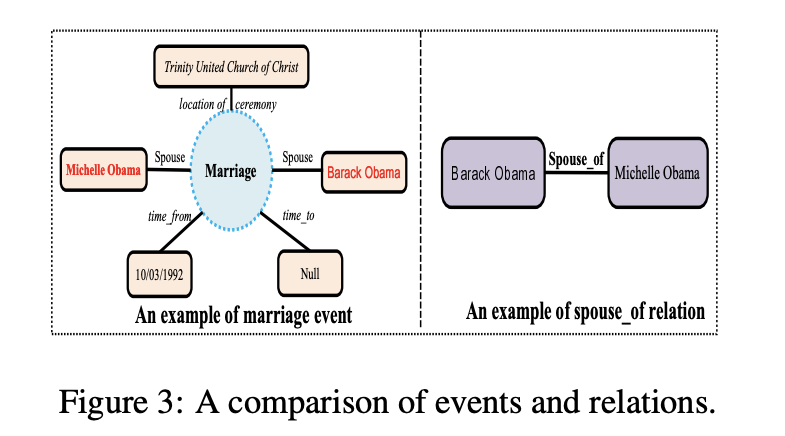
主要思想:1)提出了一种按重要性排列论元并且为每种事件类型选取关键论元或代表论元方法。2)仅仅使用关键论元来标注事件,并找出关键词。3)用外部语言知识库FrameNet来过滤噪声触发词并且扩展触发词库。
数据集:ACE2005
阅读理解式事件抽取
2020
Event Extraction by Answering (Almost) Natural Questions, EMNLP 2020 [18]
主要思想:事件抽取问题需要检测事件触发并提取其相应的参数。事件参数抽取中的现有工作通常严重依赖于作为预处理/并发步骤的实体识别,这导致了众所周知的错误传播问题。为了避免这个问题,我们引入了一种新的事件抽取范式,将其形式化为问答(QA)任务,该任务以端到端的方式抽取事件论元。实证结果表明,我们的框架优于现有的方法; 此外,它还能够抽取训练时未见角色的事件论元。
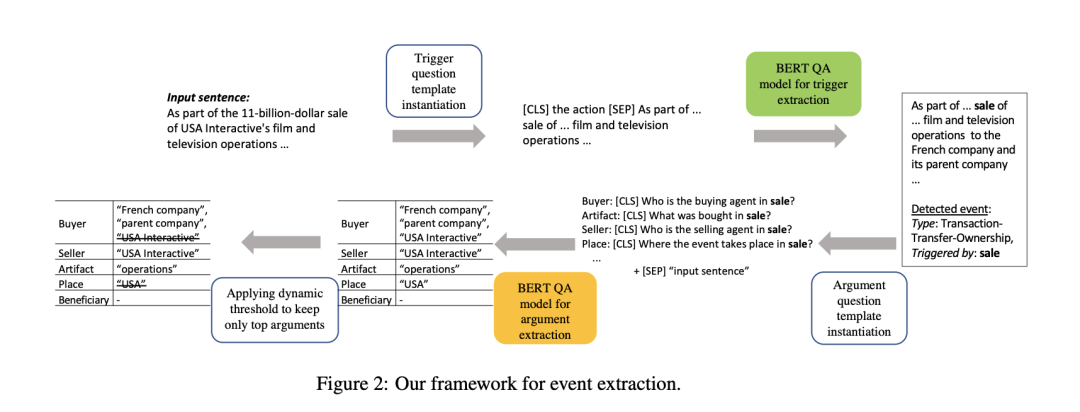
数据集:ACE
2019
Neural Cross-Lingual Event Detection with Minimal Parallel Resources, EMNLP2019[19]
标注数据的缺乏给事件检测带来了巨大的挑战。跨语言教育旨在解决这一挑战,通过在不同语言之间传递知识,提高性能。但是,以前用于ED的跨语言方法对并行资源有严重依赖,这可能限制了它们的适用性。
在本文中,我们提出了一种跨语言的ED的新方法,证明了并行资源的最小依赖性。具体来说,为了构建不同语言之间的词汇映射,我们设计了一种上下文依赖的翻译方法; 为了解决语序差异问题,我们提出了一种用于多语言联合训练的共享句法顺序事件检测器。通过在两个标准数据集上的大量实验,研究了该方法的有效性。实证结果表明,我们的方法在执行不同方向的跨语言迁移和解决注解不足的情况下是有效的。
Entity-relation extraction as multi-turn question answering, ACL2019[20]
提出了一种新的实体-关系抽取的范式。我们把任务作为多向问答的问题,也就是说,实体和关系的抽取转化为确定答案的任务。这种多轮QA形式化有几个关键的优点:
首先,问题查询为我们想要识别的实体/关系类编码重要的信息;
其次,QA为实体与关系的联合建模提供了一种自然的方式;
第三,它允许我们开发良好的机器阅读理解(MRC)模型。
在ACE和CoNLL04语料库上的实验表明,提出的范式显著优于之前的最佳模型。我们能够在所有的ACE04、ACE05和CoNLL04数据集上获得最先进的结果,将这三个数据集上的SOTA结果分别提高到49.4(+1.0)、60.2(+0.6)和68.9(+2.1)。此外,我们构建了一个新开发的中文数据集恢复,它需要多步推理来构建实体依赖关系,而不是以往数据集的三元提取的单步依赖关系抽取。提出的多轮质量保证模型在简历数据集上也取得了最好的效果。
2017
Zero-shot relation extraction via reading comprehension, CoNLL 2017[21]
通过将一个或多个自然语言问题与每个关系槽相关联,可以将关系提取简化为回答简单的阅读理解问题。减少有几个好处:我们可以
学习relation-extraction模型通过扩展最近神经阅读理解技术
为这些模型相结合构建大训练集关系专用众包与远方监督问题,
zero-shot学习通过提取新关系类型,只有指定的测试时间,我们没有标签的训练例子。
在Wikipedia填槽任务上的实验表明,该方法可以高精度地将已知关系类型的新问题概括为新问题,并且在较低的精度水平下,Zero-shot地概括为不可见的关系类型是可能的,这为该任务的未来工作设置了标准。
责任编辑:xj
原文标题:超全必读!NLP 事件抽取综述(下)
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
事件
+关注
关注
0文章
12浏览量
9928 -
自然语言处理
+关注
关注
1文章
618浏览量
13553 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:超全必读!NLP 事件抽取综述(下)
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
语义分割25种损失函数综述和展望






 工商网监
工商网监
评论