 在生产环境用了一年k8s的经验教训
在生产环境用了一年k8s的经验教训
【导读】:Netflix架构师在使用Kubernetes一年后,回顾了团队迁移到Kubernetes的好与坏,取与舍。
2015年时,我们的团队在亚马逊EC2部署服务已经有几年了。这时我所在的团队接到一项任务,要创建所有研发团队都可以使用的全新部署平台。这些年以来基于AWS的平台的新版本发布虽然已经足够流畅,但如果要用定制化脚本或工具做自动化部署,对于非运维团队人员来说就不那么易用了。对于没资源学习所有定制化工具和脚本细节的小团队尤其困难。主要问题是,AWS没有模块化部署,而没有模块化部署研发和运维之间就存在一定隔阂。容器化正是要解决这个隔阂的,而且容器化是趋势。
如果你们还没在生产中使用Docker和kubernetes,看看我们团队是怎么吃螃蟹的。我们已经在生产环境使用kubernetes有一年多了。
首先从容器和容器编排工具入手
我认为,容器是未来的部署格式。使用容器,非常方便用服务所需的基础层进行打包。Docker这类工具虽然提供了容器,我们也需要管理副本和做故障转移的工具和API,有了这些才能自动化部署多台机器。
Kubernetes和docker swarm这类工具在2015年还很不成熟,只有一些早期的可用于生产环境的版本。我们还是决定从docker swarm开始用起。
一开始我们用docker swarmd来管理网络。我们用“大使模式"和一堆脚本,达到部署自动化的目的。这有多困难呢?这是我们趟的第一个坑:容器集群、网络、部署自动化是非常难处理的
我们很快意识到了这点,这时决定尝试另一个工具,kubernetes。kubernetes看起来是最好的选择,因为它有来自google、红帽、Core OS等确切了解大规模部署的组织的技术支撑。
kubernetes做负载均衡
译注:翻译本文时ingress已经可用了, 负载均衡相关的内容可以直接跳过。关于ingress、负载均衡、clusterIP和NodePort之间的区别参考下文中《Ingress vs. ClusterIP vs. NodePort vs. LoadBalancer 》部分 https://www.ibm.com/cloud/blog/kubernetes-ingress
用kubernetes工作,就要非常熟悉它的概念,比如pod、service、replication controller等。如果你还没对这些概念非常了解,可以读读kubernetes文档。kubernetes官网为初学者提供了很多文档。
http://kubernetes.io/docs/whatisk8s/
只要有一个在运行的kubernetes集群,就可以用kubectl部署一个服务了。kubectl是kuberntes的命令行接口。但很快就遇到了自动化部署的瓶颈。但在自动化部署前还要解决不能通过网络请求部署服务的问题。
部署接口是有一个服务,但是这个服务的IP地址在集群内部。也就是部署应用的服务根本不暴露给网络请求!在Google Cloud Engine上可以通过配置一个负载均衡来访问kubernetes服务。但如果不是在GCE用kubernetes,就需要额外做一些事情让kubecctl可以通过网络访问。
通过kubernetes宿主机网络和端口直接暴露服务接口,这个解决办法比较容易,很多人都是这么做的。但如果我们的服务依赖着宿主机的端口,部署多个应用时就会产生端口冲突。这也让扩展集群或替换掉宿主机变得很麻烦。
两步搭建负载均衡
在kubernetes集群前端配置如HAProxy和NGINX这类负载均衡服务是比较方便的解决方案。我们在AWS上用VPN访问kubernetes集群,用AWS的Elastic Load Balancer把外部流量接入集群内的HAProxy。HAProxy给每个Kubernetes服务都配置了一个接口,这个接口把流量分发给每个pod。
这个两步搭建负载均衡是为了绕过AWS ELB的限制做的。ELB不能处理多个虚机,这也是我们用HAProxy的原因。只使用HAProxy不用ELB也可以,但这样就要想办法在DNS层绕过动态AWS IP地址。
图1:两步负载均衡的工作原理
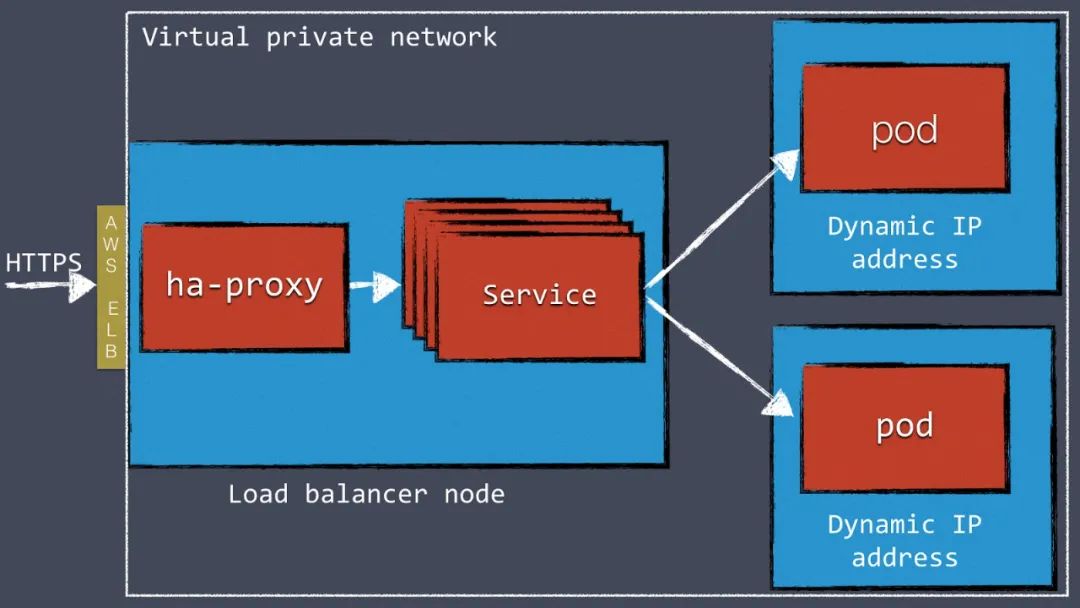
当前kubernetes正在开发ingress的功能。这个功能会允许直接从kubernetes内部定义外部负载均衡。当前这个功能还没实现完,去年我们是用api和一些开源工具做的可配置的负载均衡。https://kubernetes.io/docs/concepts/services-networking/ingress/
配置负载均衡
首先我们需要一个存储负载均衡配置的地方。这个配置可以放在任何地方,但既然已经有etcd了,我们就决定把数据存到etcd。我们用confd这个工具监听etcd中配置的变化,基于模板生成新HAProxy配置文件。新服务添加到Kubernetes中时,在etcd中增加一个配置,这就会触发新HAProxy文件的生成。
Kubernetes越来越成熟
Kubernetes依然存在很多未解决问题,就像负载均衡那样问题多多。很多问题会被社区识别后写出设计文档,文档中讨论可以解决问题的新功能。但是产出通用的解决方案需要消耗大量时间,也就是说这些文档里讨论的功能可能需要很久才能发布到新版本里。这是件好事,长期来看设计新功能时省事有害无益。
虽然发布新功能耗时不短,Kubernetes并没有被限制住。使用kubernetes API几乎可以做到任何你想做的事。一旦社区发布了解决方案,我们就用标准方案替换我们定制化开发的方案。
定制化开发了负载均衡结局方案,下一个挑战是实现一个特别重要的部署能力:蓝绿发布。
Kubernetes内做蓝绿发布
蓝绿发布的服务是在发布过程中没有任何服务不可用时段的。和滚动发布相比,蓝绿发布是通过创建一个新集群副本,上面跑着新版本的服务,老版本的服务依然存在、而且在接收事实流量。只有新副本完全部署好、已经运行起来,这时负载均衡会把流量切给新版本的服务。
这种发布方式的好处是同一时刻,只有一个版本的服务在工作,不需要考虑版本兼容的问题。蓝绿发布对于实例数量少的副本更友好。
图2:蓝绿发布的工作原理
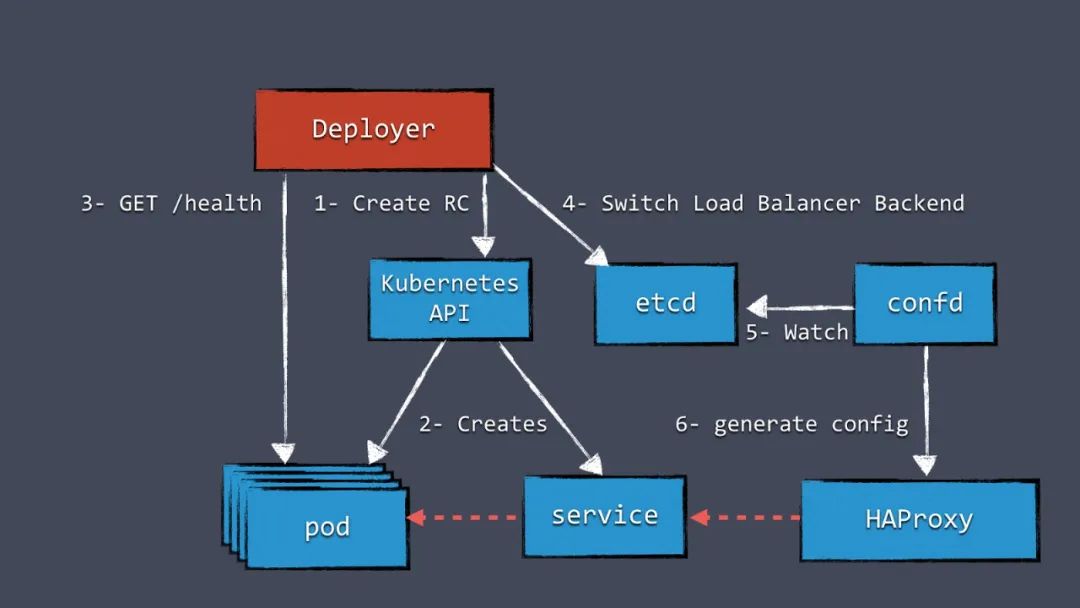
图2里有一个组件叫Deployer,它负责调度整个发布流程。你的团队可以创建这个组件,我们已经把我们的实现作为Amdatu项目的一部分、使用Apache协议开源了。这个组件还有可以配置部署的web界面。
https://bitbucket.org/amdatulabs/amdatu-kubernetes-deployer
https://bitbucket.org/account/user/amdatulabs/projects/INFRA
重新配置负载均衡前,需要对每个pod做健康检查,这个机制在蓝绿发布里非常重要。我们希望每个我们部署的组件都提供一个监控检查功能。我们通常会给每个程序添加一个HTTP健康检查服务。
自动化部署
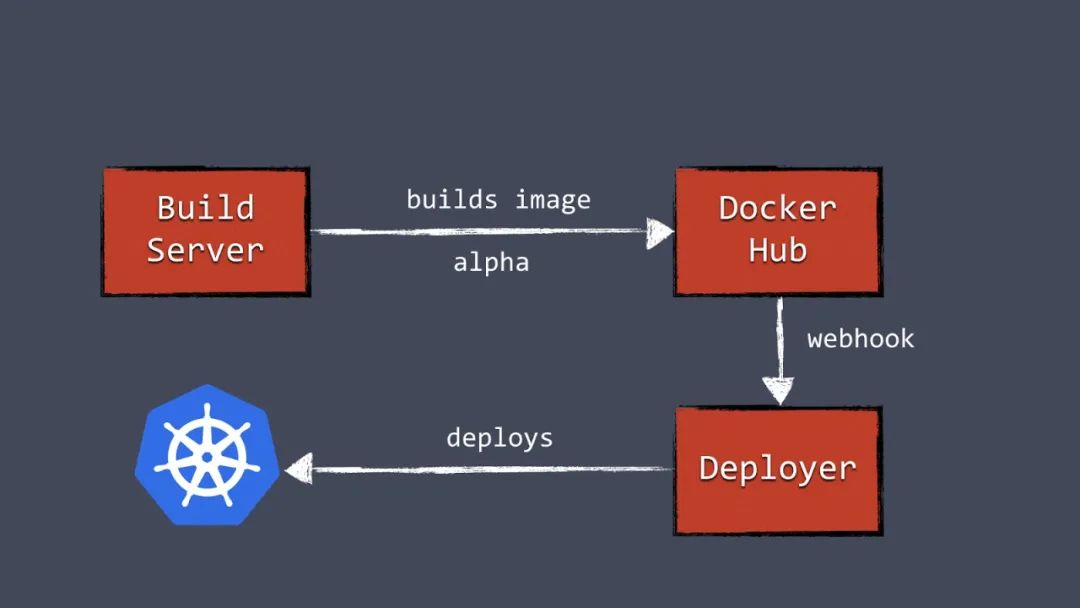
有了Deployer,就能把部署绑定到某个pipeline上了。打镜像成功后,构建服务器就会把新的docker镜像推到镜像服务器上。比如推给Docker Hub。然后构建服务器触发Deployer,自动部署新版本到test环境。同样一个镜像可以被推到生产环境,只需触发生产环境的Deployer即可进行部署。
图3:自动化容器部署流水线
了解资源限制
用Kubernetes就必须了解资源限制机制。可以配置每个pod的请求数和CPU、内存的限制,也可以控制给定资源数和突发资源数的限制。
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
这些配置对同时、高效运行多个容器很重要,如果没有正确地配置,容器可能会因为没有被分配足够内存而经常崩溃。
早早开始配置并测试容器的资源限制,没有资源限制的集群依然会运行,不过一旦给某些容器真正的流量,就会出大问题。
怎么给k8s做监控
基本部署好k8s之后,我们很快意识到监控和日志对这种动态环境来说非常重要。如果你面对着数量众多的副本和节点,登陆一台服务器看日志文件这件事就不再可行。一旦开始用kubernetes,就需要规划集中式的日志和监控了。
日志
日志有数量众多的开源工具可供选择。日志管理工具Graylog,从容器中采集和消费数据用Kafka消息队列。容器发送日志到kafka,kafka把日志交给graylog建索引。我们让容器自己发日志到Kafka,这样处理日志就很容易。还有其他一些方案可以从外部取容器内的日志、把日志发到日志管理系统的方案的做法,参考:https://www.loggly.com/blog/top-5-docker-logging-methods-to-fit-your-container-deployment-strategy/
监控
kubernetes在容器挂掉后恢复做的非常好。当容器由于某种原因崩溃,kubernetes会做容器重启。如果Kubernetes里运行着一个副本,终端用户可能无法注意到程序重启了。Kubernetes的恢复做的太好,以至于我们遇到过一组容器由于内存泄露,一天重启了好多次但没人知道重启动这种情况。
尽管从kubernetes的角度看没问题,但我们开发和维护人员还是需要知道是否程序存在问题的。我们用一个定制化的健康检查大盘,监控所有kubernetes节点、每个pod和其他如数据存储之类的服务。每个pod的健康检查是使用了对当前某个服务的检查。要实现这样一个大盘,kubernetes api又一次变得十分重要。
度量负载、吞吐量、程序错误等数据也很重要,这时候就要使用开源工具了。我们的应用组件把数据发送到InfluxDB这个时序数据库里。存储在InfluxDB内的数据可以通过Grafana做可视化,Grafana是开源数据大盘管理系统。除了influxdb + grafana之外还有很多其他可选项,任意解决方案都可以提升系统问题的可观测性。
kubernetes和数据存储
很多新k8s用户问,“我该怎么用kubernetes处理数据存储呢?”
用MongoDB和MySQL这类数据存储,一般都要把数据持久化地存储起来。容器重启时会丢失上次的数据,这对无状态的组件没什么问题,但是对于持久化数据存储,这样非常不好。kubernetes对持久化数据有volumn这个概念。
一个volume可以有多种底层实现,包括存储在宿主机的文件、AWS EBS、NFS等。虽然volume算是个好解决方案,但是对我们运行着的数据存储来说不是一个好方案。
副本问题
多数deployment中,数据存储都会以复制的方式运行。典型就是Mongodb里的replica set、mysql以主副节点模式运行。这引入了一些新问题,首先是每个节点的数据存储集群都可能是不同的系统。写入同一个卷可能导致数据不可用。另一个问题是多数数据存储都需要准确的用来启动集群的配置参数,自动发现、自动配置节点并不常见常用。
一台运行着数据存储的机器要为负载做特殊的配置,比如配置更高IOPS。这样一来,对于数据存储,使用k8s做增加删除节点的成本会大大增加。这些特性与k8s部署的动态特性适配性不好。
不在生产环境中使用Kubernetes存储数据
我们认为在Kubernetes中做数据存储收益有限。在K8S中启动数据存储比大多数kubernetes deployment都复杂。
鉴于此,我们决定把生产数据存储到kubernetes节点中。我们在其他机器上手动部署集群,使用必要的手段优化特定数据存储。运行在Kubernetes中的服务和访问其他服务一样连接并访问存储节点。不是有Kubernetes了就一定要把所有东西都部署上去。除了数据存储和HAProxy服务器,其他在kubernetes内运行,包括日志和监控。
为什么我们对明年kubernets的表现非常期待
看看我们部署的系统,kubernetes已经非常强大了。kubernetes API是做自动化和部署pipeline的极好的工具。deployment又快又可靠,我们也不再跟虚拟机打交道了。我们的构建和部署因为测试、维护容器更容易也变得更可靠了。
可见,采取这种部署方式对于想跟上业界其他频繁部署应用、而且要降低部署开销的团队的步伐也是非常必要的。
计算成本
看下成本。跑kubernetes需要一个etcd集群和一个master节点,运行这些花费不高,但是对于部署规模不大的集群来说可能成本占比会更高。对于部署规模小的部署,使用Google的容器化服务解决方案可能是更好的选择。
对于大规模部署来说,这可以节省很多在服务方面的开销。这时运行etcd和一个master节点不会是显著的消耗了。kubernetes可以在同一台机器上要运行很多容器、并最大限度地使用资源。这减少了所需的服务器数量,进而更省钱。尽管使用K8s听起来很好,但是对于运维这种大集群来说就不那么好做了,有许多托管服务需要考虑,包括我的团队正在研究的云RTI。
Kubernetes的光明未来
用预发布版本的kubernetes非常有挑战,跟进新版本更新有时候几乎是不可能的。近一年来,kubernetes的开发一直以来都在飞快地进行,社区已经变成了开发人才们的发电站。社区一年时间的进展可能是难以估算的。
责任编辑:lq
-
自动化
+关注
关注
29文章
5598浏览量
79431 -
模块化
+关注
关注
0文章
332浏览量
21379
原文标题:在生产环境用了一年 k8s 的经验教训
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
k8s和docker区别对比,哪个更强?
k8s微服务架构就是云原生吗?两者是什么关系
混合云部署k8s集群方法有哪些?
k8s可以部署私有云吗?私有云部署全攻略
k8s云原生开发要求

k8s容器启动失败的常见原因及解决办法
云服务器部署k8s需要什么配置?
纳尼?自建K8s集群日志收集还能通过JMQ保存到JES
常用的k8s容器网络模式有哪些?
K8S集群中使用JDOS KMS服务对敏感数据安全加密
K8S学习教程三:在PetaExpress KubeSphere 容器部署 Wiki 系统 wiki.js 并启用中文全文检索
K8S学习教程(二):在 PetaExpress KubeSphere容器平台部署高可用 Redis 集群





 工商网监
工商网监
评论