 PowerVR光线追踪混合渲染效果
PowerVR光线追踪混合渲染效果
作者:RYS SOMMEFELDT
尽管在理论上实现现代GPU的方法是无限的,但真正有效的方法是切实的了解问题并着手将方案变为现实。制造现代高性能半导体器件以及试图加速当前可编程光栅化技术所面临的问题揭示了GPU硬件行业发展的未来趋势。
例如在现代GPU中SIMD处理和固定功能纹理单元是必不可少的,以至于不使用它们来设计的GPU方案几乎肯定意味着在研究之外不具有商业上的可行性和实用性。即使是过去20年来,任何一个GPU最疯狂的愿景也没有舍弃这些核心原则(安息吧,Larrabee(英特尔公司(GPU 的芯片代号))。
过去15年来实时光线追踪加速一直被默认为是GPU设计中最令人烦心的问题,关于光线追踪应该如何在GPU上实现的主流规范是微软推出的DXR,它要求的执行模型却不能真正融入到GPU的工作模式,这无疑给任何需要支持它的GPU设计者带来一些严重的潜在问题。如果实时光线追踪是它们过去十年时间没有考虑过的事情,那么这个问题会更加明显,而Imagination一直在关注这个问题。
光线追踪面临的关键挑战
如果你遵循DXR规范并考虑需要在GPU中实现些什么从而提供计算加速性能,那么你将很可能快速梳理出不管采用何种设计方案都需要解决的以下几个问题:
首先你需要一种方法来生成和处理一组包含几何体的数据结构,从而能以更有效的方式根据几何体来跟踪光线。其次当追踪光线时,GPU要测试光线是否与之相交,要提供一些用户可定义的编程接口。第三被跟踪的光线可以发出新的光线!DXR规范定义的实现方案还需要考虑其他问题,但是从全局来看这三个因素是最重要的。
PowerVR光线追踪混合渲染效果
生成和使用加速数据结构来有效的表示需要做相交测试的几何体意味着GPU可能要完成一个全新的执行阶段,然后我们需要用全新的接口函数处理这些新的数据结构,测试是否相交,之后在程序员的控制下根据相交测试的结果实现一些功能。GPU是并行的设计,所以同时处理一堆光线意味着什么?这样做是否发现了新挑战,而这些挑战与传统的几何和像素并行处理所带来的挑战却大不相同?
上一个问题的答案是非常肯定的,的确这些差异对如何将光线追踪映射到现有的GPU执行的模型中有着深远的影响。这些GPU存在计算资源和内存资源的不平衡,导致内存访问成为一种宝贵的资源,而浪费这些资源是导致效率和性能低下的最主要原因之一。
哦不——我们做了些什么?
GPU被设计成可以以任何形式充分利用与之连接的DRAM的访问,利用内存访问的空间或时间局部性来作为实现这一目的的方法。值得庆幸的是最常见和最现代化的光栅化渲染有一个很好的特性,即在着色期间(尤其是像素着色通常是任何给定帧的主要工作负载)三角形和像素顶点有可能与它们的近邻共享相关数据。因此,您访问一组像素所需的任何缓存数据,很可能下一个相邻的组将需要使用您已经从DRAM中提取并缓存的部分或全部内存数据。对于当今大多数栅格化渲染工作负载而言,这都是正确的,因此我们都可以松一口气,并围绕该属性设计GPU架构。
当我们使用光线追踪,这些就都失效了。光线追踪使所有空间局部性消失。下面让我们来分析其中的原因。
物体表面的问题
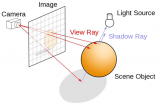
最简单的思考方式就是观察四周,在你坐下来阅读这篇文章时注意光线在你所处环境中的作用。由于光线追踪建模了光线从所有光源传播时的属性,因此它必须处理光线照射在场景中任何表面时发生的情况。也许我们只关心光线照射哪些物体,也许物体的表面以均匀的方向散射光线,但它也可能完全是随机的。也许表面吸收了所有的光,因此不会有次级光线的传播。也许表面有一种材质属性,使它能够部分吸收几乎所有照射来的光线,然后随机散射它不能捕获的少量光线。
只有第一种场景可以映射到GPU的利用内存访问局部性的工作模式,即使如此也只有当所有并行处理的光线都照射到同一类型的三角形时才可以。
正是这种明显分歧的可能性导致了这些问题,如果并行处理的任何光线相互之间可能会有不同的作用,包括撞击不同的加速数据结构或发出新的光线,那么GPU能高效工作的基本前提就会被破坏,而且这通常比在传统的几何图形或像素处理中遇到的发散现象更具有破坏性。
相干性聚集
PowerVR对光线追踪硬件加速的实现所做的是硬件光线追踪和排序,它与当今行业内任何其他硬件光线追踪加速相比都是独一无二的,这对软件方面来说是完全透明的,确保硬件上并行追踪的发射光线具有潜在的相似性。我们称之为相干性聚集。
硬件维护了一个数据结构,用于层次化的存储软件发出的正在被硬件处理的光线,并能够根据它们的方向按它们在加速结构中前进的位置进行选择和分组。这意味着当它们被处理时更可能共享存储器中被访问的加速数据结构中的数据,且额外的优势是能够最大化随后要并行处理的光线-几何体相交计算的数量。
通过分析由硬件调度的光线我们可以确保以GPU友好的方式对它们进行分组,从而更高效的进行后续处理,这些是该系统成功的关键,有助于避免打破GPU行业为高效的光栅化渲染而精心设计的运行模式,这就避免了光线追踪硬件对特殊类型存储系统的需求,因此提供了与GPU的其他部分更容易集成的方案。
相干性聚集机制本身相当的复杂,因为它需要快速的追踪,排序和调度所有的被提交到硬件中处理的光线,从而不会反压前级用于发射光线的调度系统,也不会造成后级以排序好的光线和加速数据结构为输入的硬件的空闲。
如果没有硬件系统来帮助GPU处理光线排序,那么就需要依赖应用程序或游戏开发人员以某种方式在主机上处理光线的相干性问题,或者在GPU上加入一个中间的计算环节来处理光线排序——前提是这种方式被硬件所支持,以上假设的方式中没有一个能在实时的硬件平台上提升效率和性能,然而Imagination是市场上唯一拥有这种硬件光线追踪系统的GPU IP供应商。
紧跟潮流
我们之所以成为行业内唯一针对硬件光线追踪提供解决方案的供应商是因为我们已经致力于解决这个问题很长时间了,与行业中其他正在缓慢的进展相比,光线追踪已经成为当今图形技术广泛采用API之一了。
我们的相干性聚集特性与目前行业的光线追踪相互兼容(如果光线恰好发射出新的光线,堆栈将会被释放也可能发射出新的光线等等),在每个阶段进行相干性聚集处理并确保我们尽可能的实现硬件光线追踪的强大性能。
在现代的硬件光线追踪系统中最重要的是测量光线束、峰值并行测试率或空光线发射和未命中率,这些是描述光线追踪硬件性能的简单方式,但是也并不是非常的有用,毕竟开发人员并不只关心高峰值并行测试率或漏测率。
我们的目标是在整个加速系统中使用全面的光线追踪,这样开发人员就可以用光线束预算要实现哪些有用的功能。我们的相干性聚集系统与我们提供的解决方案共同实现了这个目标,与行业内的其他方案相比都是独一无二的。
原文链接:https://www.imgtec.com/blog/coherency-gathering-in-ray-tracing-the-benef...
来源:电子创新网
审核编辑:何安
-
光线追踪
+关注
关注
0文章
183浏览量
21495
发布评论请先 登录
相关推荐
基于光线追踪实现反射折射效果

基于光线追踪的渲染算法实现
光线追踪的工作原理
AMD光线追踪专家加盟高通,共筑Adreno GPU性能新高度
CPU渲染和GPU渲染优劣分析
解码AI驱动的DLSS 3.5光线重建功能
HarmonyOS实战开发-合理选择条件渲染和显隐控制
MediaTek携手望尘科技通过移动端光线追踪技术打造沉浸体育游戏体验
【RTC程序设计:实时音视频权威指南】音频采集与渲染
【RTC程序设计:实时音视频权威指南】视频采集与渲染
MediaTek携手望尘科技共同推进移动端光线追踪技术在手游中的应用落地

AMD Radeon RX 7000M系列显卡特性分析

探索渲染技术与云渲染的魅力!
边缘光线理论基础





 工商网监
工商网监
评论