 嵌入式常见笔试题收集
嵌入式常见笔试题收集
一、系统相关
波特率
1)定义:
波特率表示每秒钟传送的码元符号的个数,是衡量数据传送速率的指标,它用单位时间内载波调制状态改变的次数来表示。
在信息传输通道中,携带数据信息的信号单元叫码元,每秒钟通过信道传输的码元数称为码元传输速率,简称波特率。波特率是传输通道频宽的指标。
2)计算:
波特率115200 = 115200 (位/秒)
以最普通的串口(起始位+8位数据+停止位)为例:
除以10,得到的是每秒字节数:
波特率115200 = 115200 (位/秒) = 11520 (字节/秒)
再除以 1024,就是每秒 KB 数:
波特率115200 = 115200 (位/秒) = 11.25 (KB/秒)
如果有一位奇偶校验位,就应该除以 11,得到的是每秒字节数。
最后:
波特率115200 = 115200 (位/秒) = 10.27 (KB/秒)
备注:
二进制环境下,波特率 = 比特率。
哈佛结构
哈佛结构是一种将程序指令存储和数据存储分开的存储器结构,它的主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问,目的是为了减轻程序运行时的访存瓶颈。
程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度,如Microchip公司的PIC16芯片的程序指令是14位宽度,而数据是8位宽度。
冯诺依曼结构
冯·诺依曼结构,又称为普林斯顿体系结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。取指令和取操作数都在同一总线上,通过分时复用的方式进行;缺点是在高速运行时,不能达到同时取指令和取操作数,从而形成了传输过程的瓶颈。由于程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同。
其中,msp430、ARM7、freescale等单片机为冯诺依曼结构。
改进型哈佛结构
改进型哈佛结构虽然也使用两个不同的存储器:程序存储器和数据存储器,但它把两个存储器的地址总线合并了,数据总线也进行了合并,即原来的哈佛结构需要4条不同的总线,改进后需要两条总线。
ARM处理器的工作模式
一个程序运行在不同的模式下面的时候,能够运行的ARM处理器的指令是不一样的,能够访问的ARM处理器的寄存器都是不一样的。这些模式为:
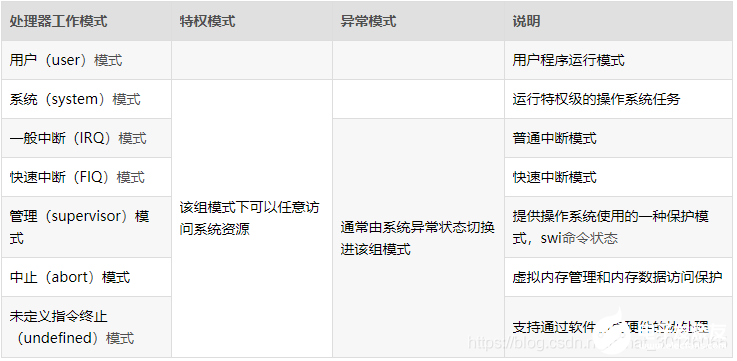
特权模式
除用户模式外,其它模式均为特权模式(Privileged ModesARM内部寄存器和一些片内外设在硬件设计上只允许(或者可选为只允许)特权模式下访问。此外,特权模式可以自由的切换处理器模式,而用户模式不能直接切换到别的模式。
异常模式
特权模式中除系统(system)模式之外的其他5种模式又统称为异常模式。它们除了可以通过在特权下的程序切换进入外,也可以由特定的异常进入。比如硬件产生中断信号进入中断异常模式,读取没有权限数据进入中止异常模式,执行未定义指令时进入未定义指令中止异常模式。其中管理模式也称为超级用户模式,是为操作系统提供软中断的特有模式,正是由于有了软中断,用户程序才可以通过系统调用切换到管理模式。
硬件权限级别:系统模式 > 异常模式 > 用户模式
对于Linux而言,一般的应用程序运行在User模式,而Linux内核运行在SVC模式,即Supervisor模式
(1)用户模式:
用户模式是用户程序的工作模式,它运行在操作系统的用户态,它没有权限去操作其它硬件资源,只能执行处理自己的数据,也不能切换到其它模式下,要想访问硬件资源或切换到其它模式只能通过软中断或产生异常。
(2)系统模式:
系统模式是特权模式,不受用户模式的限制。用户模式和系统模式共用一套寄存器,操作系统在该模式下可以方便的访问用户模式的寄存器,而且操作系统的一些特权任务可以使用这个模式访问一些受控的资源。
说明:用户模式与系统模式两者使用相同的寄存器,都没有SPSR(Saved Program Statement Register,已保存程序状态寄存器),但系统模式比用户模式有更高的权限,可以访问所有系统资源。
(3)一般中断模式:
一般中断模式也叫普通中断模式,用于处理一般的中断请求,通常在硬件产生中断信号之后自动进入该模式,该模式为特权模式,可以自由访问系统硬件资源。
(4)快速中断模式:
快速中断模式是相对一般中断模式而言的,它是用来处理对时间要求比较紧急的中断请求,主要用于高速数据传输及通道处理中。
(5)管理模式(Supervisor,SVC):
管理模式是CPU上电后默认模式,因此在该模式下主要用来做系统的初始化,软中断处理也在该模式下。当用户模式下的用户程序请求使用硬件资源时,通过软件中断进入该模式。
说明:系统复位或开机、软中断时进入到SVC模式下。
(6)终止模式:
中止模式用于支持虚拟内存或存储器保护,当用户程序访问非法地址,没有权限读取的内存地址时,会进入该模式,linux下编程时经常出现的segment fault通常都是在该模式下抛出返回的。
(7)未定义模式:
未定义模式用于支持硬件协处理器的软件仿真,CPU在指令的译码阶段不能识别该指令操作时,会进入未定义模式。
流水线机制
传统的单片机(如8051)中,处理器只有完成一条指令的读取和执行后,才会开始下一条指令的处理,所以PC(程序计数器)总是指向正在执行的指令。而ARM体系架构中则引入了流水线的概念。
到ARM7为止的ARM处理器使用了简单的三级流水线。三级流水线使用三个工位,将指令的处理分为三个阶段,分别为取指、译码和执行。取指:从存储器中装载;译码:识别将要被执行的指令;执行:处理指令并将结果写回寄存器。
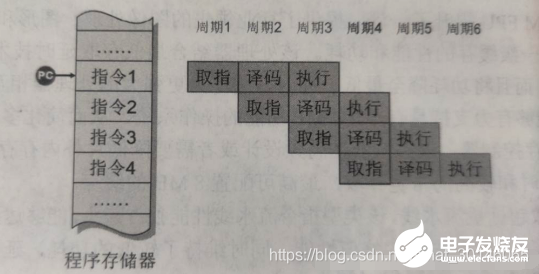
Cortex-A9架构基于先进的推测型八级流水线
同步通信和异步通信
(1)同步通信要求接收端时钟频率和发送端时钟频率一致,发送端发送连续的比特流;异步通信时不要求接收端时钟和发送端时钟同步,发送端发送完一个字节后,可经过任意长的时间间隔再发送下一个字节。
(2)同步通信效率高;异步通信效率较低。
(3)同步通信较复杂,双方时钟的允许误差较小;异步通信简单,双方时钟可允许一定误差。
(4)同步通信可用于点对多点;异步通信只适用于点对点。同步是阻塞模式,异步是非阻塞模式。
异步通信:异步通信中的接收方并不知道数据什么时候会到达,收发双方可以有各自自己的时钟。发送方发送的时间间隔可以不均,接收方是在数据的起始位和停止位的帮助下实现信息同步的。这种传输通常是很小的分组,比如一个字符为一组,为这个组配备起始位和结束位。所以这种传输方式的效率是比较低的,毕竟额外加入了很多的辅助位作为负载,常用在低速的传输中。典型通信为串口通信。
同步通信:同步通信中双方使用频率一致的时钟,它的分组相比异步则大得多,称为一个数据帧,通过独特的bit串作为启停标识。发送方要以固定的节奏去发送数据,而接收方要时刻做好接收数据的准备,识别到前导码后马上要开始接收数据了。同步这种方式中因为分组很大,很长一段数据才会有额外的辅助位负载,所以效率更高,更加适合对速度要求高的传输,当然这种通信对时序的要求也更高。典型通信为:SPI和IIC。
软实时和硬实时
硬实时与软实时之间最关键的差别在于,软实时只能提供统计意义上的实时。例如,有的应用要求系统在95%的情况下都会确保在规定的时间内完成某个动作,而不一定要求100%。在许多情况下,这样的“软性”正确率已经可以达到用户期望的水平。比如,用户在操作DVD播放机时,只要98%的情况都能正常播放,用户可能就满意了;而发射卫星、控制核反应堆的应用系统,这些系统的实时性必须达到100%,是绝对不允许出现意外。
ARM体系的CPU两种工作状态
ARM状态:arm处理器工作于32位指令的状态,所有指令均为32位。
THumb状态:arm执行16位指令的状态,即16位状态。
THumb指令集是arm指令集的一个子集,是针对代码密度问题而提出的,它具有16位的代码宽度。与等价的32位代码相比较,THumb指令集在保留32位代码优势的同时,大大的节省了系统的存储空间。
另外:ARM的M系列主要用Thumb指令,ARM9和A系列主要用ARM指令。
Linux文件权限
权限数字对应权限组说明:
总共分为4部分
【文件或文件夹】【owner权限】【group权限】【others权限】
【文件是-,文件夹是d】【r/w/x相加】【r/w/x相加】【r/w/x相加】
如 chmod 777 xxx.xxx 就是说xxx文件的权限为可读可写可执行且对所有用户有效。
ls -l a 查看a文件的权限
二、软件相关
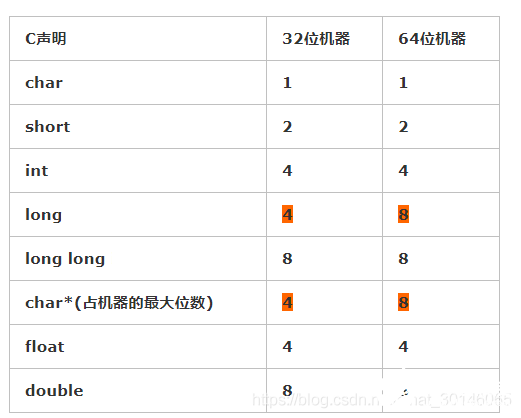
各种变量类型所占内存
大端小端问题
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。(ARM)
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。(x86平台、c51)
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
判断大小端:
#include #include typedef union{ short a; //定义一个short变量,因为它所占字节数为2,便于与长度为2的char数组内存对齐 char b[2];//定义一个char数组,因为char变量所占字节数为1,char[2]就是长度为2了 }test; int main(int argc, char *argv[]) { test ut; ut.a = 0x1234; printf("ut.b[0]:%02x/r/n",ut.b[0]);//若打印0x12即为小端,打印出0x34则为大端 printf("ut.b[1]:%02x/r/n",ut.b[1]); printf("ut:%d/r/n",sizeof(ut)); return 0; }
大小端转换实例:
//16位 #define BSWAP_16(x) / (uint_16)((((uint_16)(x) & 0x00ff) <<8) | / (((uint_16)(x) & 0xff00) >> 8) / )
volatile关键词
volatile是一个类型修饰符(type specifier),就像我们熟悉的const一样,它是被设计用来修饰被不同线程访问和修改的变量;volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。
简单地说就是防止编译器对代码进行优化。
例如,在多线程,或者是存在中断的场景下:
buff[0]=0x01; buff[0]=0x02; buff[0]=0x03; buff[0]=0x04;
编译器可能会将上面4行代码优化为1行 buff[0]=0x04;
但是,可能我们想要的结果就是需要连续运行着四段代码,因为有可能在另外的线程或中断访问buff[0]时,我们需要得到一个实时的结果,可能是0x01,也可能是0x03,但如果不加volatile关键词,可能得到的值永远都是0x04。
do{}while(0)的技巧用法
(1)在后面要加分号,使调用如同函数
在定义宏后,使用do{}while(0)如果不加分号会直接报错
(2)避免括号等使用因素对实际运行造成影响
例如,定义一个宏:
#define foo(x) bar(x); baz(x)
然后你可能这样调用:
foo(wolf);
这将被宏扩展为:
bar(wolf); baz(wolf);
这的确是我们期望的正确输出。下面看看如果我们这样调用:
if (!feral) foo(wolf);
那么扩展后可能就不是你所期望的结果。上面语句将扩展为:
if (!feral) bar(wolf); baz(wolf);
显而易见,这是错误的。如果使用do while写法即可避免这个问题:
if (!feral) do { bar(wolf); baz(wolf); } while (0);
等价于:
if (!feral) { bar(wolf); baz(wolf); }
(3)避免空宏引起的warning
内核中由于不同架构的限制,很多时候会用到空宏,在编译的时候,空宏会给出warning,为了避免这样的warning,就可以使用do{}while(0)来定义空宏:
#define EMPTYMICRO do{}while(0)
(4)避免使用goto对程序流进行统一的控制
有些函数中,在函数return之前我们经常会进行一些收尾的工作,比如free掉一块函数开始malloc的内存,goto一直都是一个比较简便的方法:
int foo() { somestruct* ptr = malloc(...); dosomething...; if(error) { goto END; } dosomething...; if(error) { goto END; } dosomething...; END: free(ptr); return 0; }
由于goto不符合软件工程的结构化,而且有可能使得代码难懂,所以很多人都不倡导使用,那这个时候就可以用do{}while(0)来进行统一的管理:
int foo() { somestruct* ptr = malloc(...); do{ dosomething...; if(error) { break; } dosomething...; if(error) { break; } dosomething...; }while(0); free(ptr); return 0; }
这里将函数主体使用do()while(0)包含起来,使用break来代替goto,后续的处理工作在while之后,就能够达到同样的效果。
(5)定义一个单独的函数块来实现复杂的操作:
当你的功能很复杂,变量很多你又不愿意增加一个函数的时候,使用do{}while(0);,将你的代码写在里面,里面可以定义变量而不用考虑变量名会同函数之前或者之后的重复。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/sinat_30146065/article/details/105428988
-
嵌入式
+关注
关注
5082文章
19126浏览量
305260
发布评论请先 登录
相关推荐
LDO在嵌入式系统中的应用 常见LDO故障及解决方法
嵌入式系统开发与硬件的关系 嵌入式系统开发常见问题解决
利用能量收集技术实现永久运行的嵌入式系统
什么是嵌入式?一文读懂嵌入式主板
嵌入式主板是什么意思?嵌入式主板全面解析
嵌入式开发常见问题排查

嵌入式linux开发的基本步骤有哪些?
嵌入式五种常见模拟电路
嵌入式QT常见开发方式有哪些?
嵌入式系统怎么学?
嵌入式开发者的未来

USB嵌入式主机堆栈






 工商网监
工商网监
评论