 positional encoding详解
positional encoding详解
近期我会一连几篇谈谈bert中的关键细节,这个position encoding是我看到的bert(实质上是transformer中提出的)中最为惊喜的但是却被很多人忽略(可以理解为媒体鼓吹最少的)一个细节,这里给大家谈谈。
什么是position encoding
顾名思义,就是基于位置的一套词嵌入方法,说得简单点,就是对于一个句子,都有对应的一个向量。
position encoding的收益
我感觉要做一个事情,首先还是要看他的出发点和收益,说白了就是优点是啥,做这个的目标是啥,这样我们才知道怎么做。
回头看看CNN结构、RNN甚至是transformer的self-attention,其实都没有特别关注位置信息,而实际上,我们却是需要去关注的,毕竟作为一门语言,他大都有比较严谨的语法结构,特定词汇还真的会出现在特定位置,这是非常有意思的,来看看例子(来源于知乎):
I like this movie because it doesn't have an overhead history.I don't like this movie because it has an overhead history.
从情感上,上面是正面,下面是负面,这个非常显而易见,因为这个否定句,从实体提取的角度都有movie和history,无论是哪个任务,都可以看到一个语法结构中存在的位置信息。
对CNN,只能考虑到固定前后的局部信息,RNN能考虑稍微长期的信息,LSTM是有重点的记录,Transformer只能考虑到全局的信息,尤其在bert中,只用了transformer encoder,模型上就完全丧失对位置信息的描述了,因此引入基于位置的特征就可能在特定任务中产生收益。
换个角度再看一个例子:
I believe I can be the best.
对于self attention,如果没有positional encoding,两个i的输出将会一样,但是我们知道,这两个i是存在区别的,不是在指代上,而是含义上,第一个i是观点的发出者,“不要你觉得,我要我觉得”,第二个i是观点的对象,“认为我会是最棒的,不是别人”,所以从语义上两者就有所区别了,权重向量完全一样可就有问题了吧。这也是缺少位置信息的缺憾。
position embedding怎么做
首先,最简单的模式就是对词向量矩阵直接加一层全连接层,就是全连接层。就真的是这么简单!
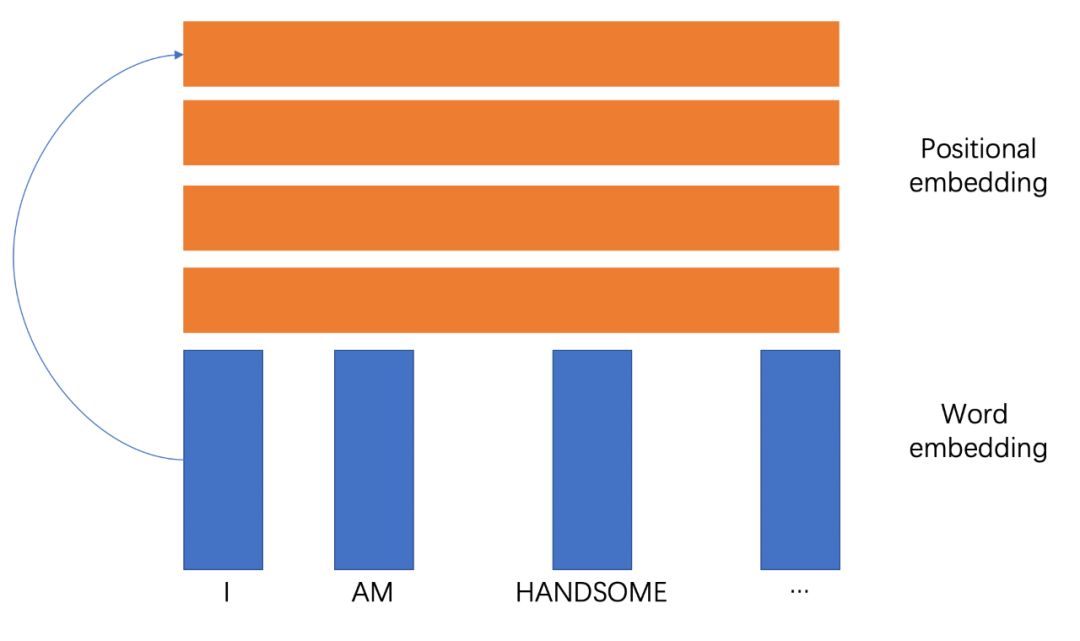
对于每个位置的词向量,都稳定的乘以一个稳定的向量,就如上面所示,第1个位置一定对应positonal embedding的第一个向量,那这组向量抽出来,不是positional embedding是啥。
但当然的,这里就有很大的问题,那就是这只是绝对位置,看上面第一个例子(我再搬运一遍):
I like this movie because it doesn't have an overhead history.I don't like this movie because it has an overhead history.
这里的like 和 don't like可就不是一个位置了吧,所以绝对位置肯定是有问题的,那么就要引入相对位置的概念了。来看看transformer论文里面是怎么说的(我把解释也给大家搬过来了):

这里用的是两种三角函数,可以说是非常巧妙了,我们来慢慢分析。上代码!
import matplotlib.pyplot as plt
import math
def positional_enc(i,pos):
return math.sin(pos /10000**(i/100))
x = []
for idx in range(10):
tmp_x = list(range(1,100))
tmp_y = [positional_enc(i, idx) for i in tmp_x]
plt.plot(tmp_x,tmp_y,label=str(idx))
plt.legend(loc = 'upper right')
plt.show()
代码跑出来是这样的:
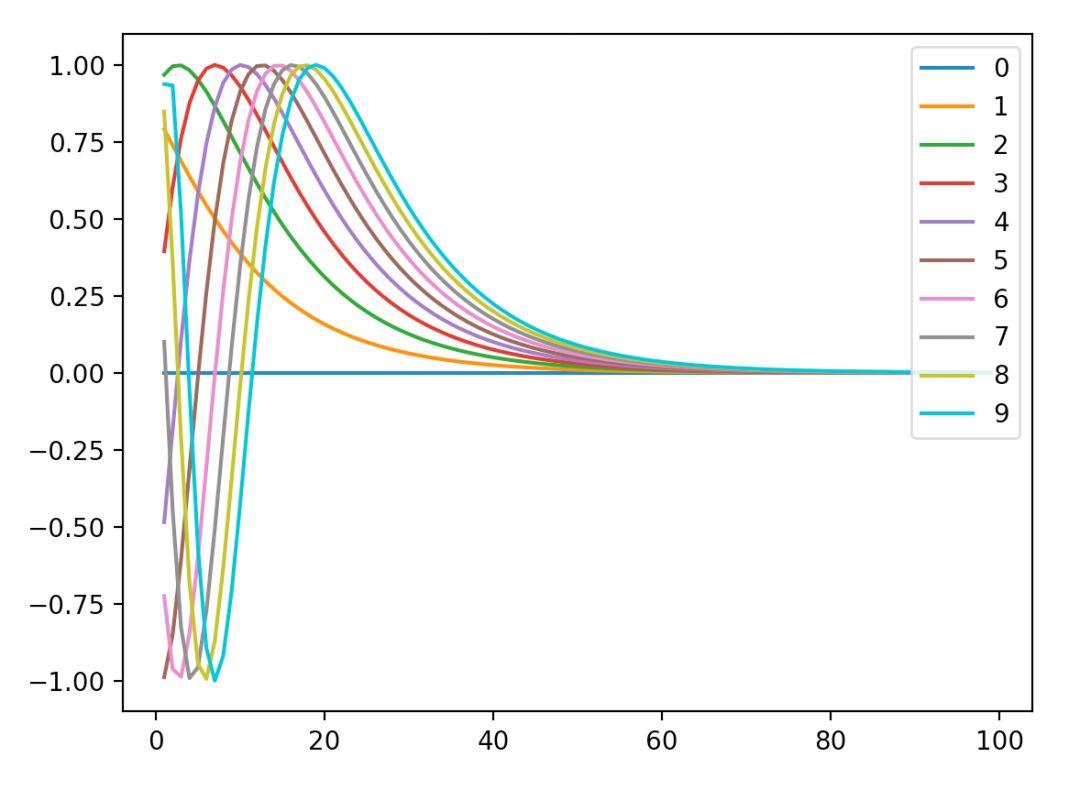
横坐标是维数上的每个值,纵坐标是对应的sin值,图例对应句子中的每个位置。
首先看维数位置-sin值之间的关系,很明显,我们没有发现周期性,最终往0处收敛,我们也可以知道了,在这种emcoding下,其实维数没必要太高了。
而对于位置-sini值之间的关系,可以整个曲线是会朝着右边移动的,从权重角度看,实质上就是每一个维度都会有一个比较看重的句子位置,其他位置说白了就是不看了,而前面的甚至可能为负,主要原因是要抛弃以前的信息,这样多个维度就能把多个位置都当做了重点来看。
周期性去了哪里呢,其实在这里,再来上代码:
import matplotlib.pyplot as plt
import math
def positional_emb(i,pos):
return math.sin(pos /10000**(i/100))
tmp_x = list(range(20))
tmp_y = [positional_emb(10, i) for i in tmp_x]
plt.plot(tmp_x,tmp_y)
plt.show()
得到了有周期性的图。
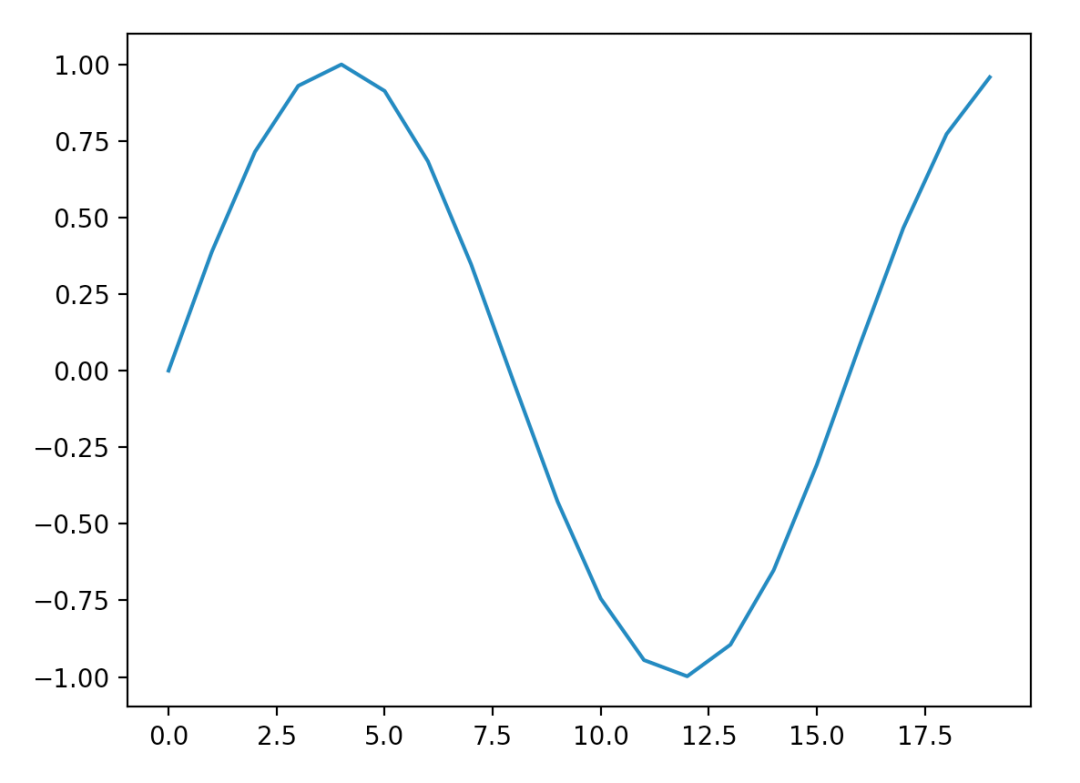
周期性只体现在位置和整个函数结果的关系,而具体的波长,其实是由positional encoding向量决定的。
不得不说,这个函数的设计可谓是对现实场景有了十分充分的理解,抽象非常精准。
预测效果
首先来看看两种positional encoding的具体效果,来自transformer的对比。
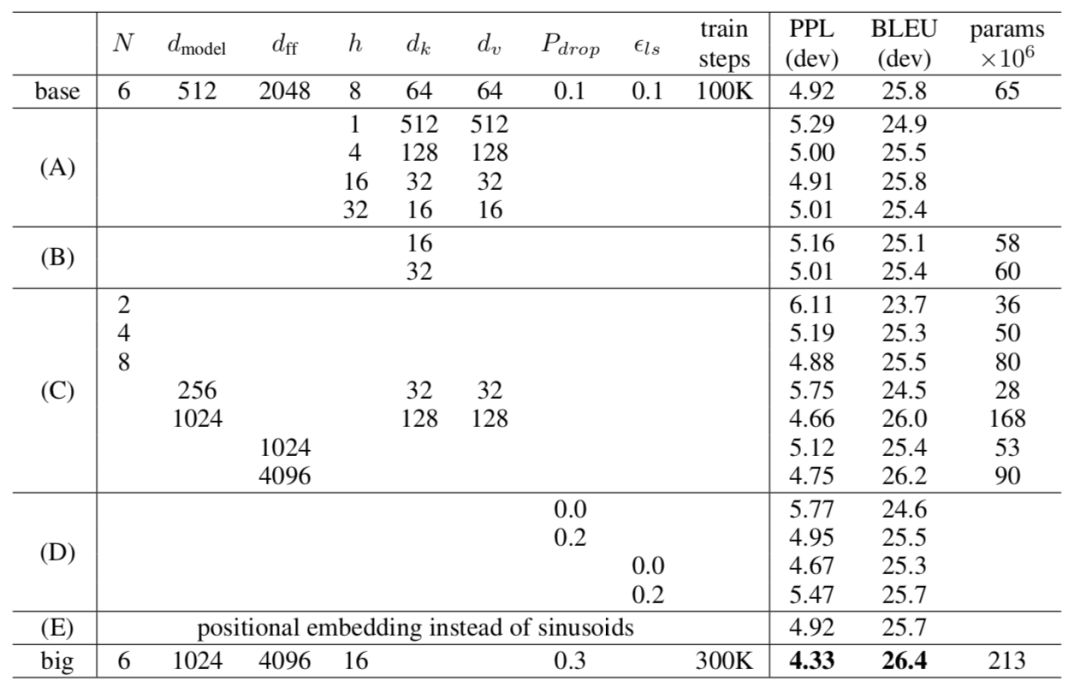
主要看E、base和big。其实可以看到posiitional emb本身的效果其实还行,与base相当,说明还是有不小收益的。
来看看源码
原理是看完了,来看看源码吧。
def positional_encoding(inputs,
maxlen,
masking=True,
scope="positional_encoding"):
'''Sinusoidal Positional_Encoding. See 3.5
inputs: 3d tensor. (N, T, E)
maxlen: scalar. Must be >= T
masking: Boolean. If True, padding positions are set to zeros.
scope: Optional scope for `variable_scope`.
returns
3d tensor that has the same shape as inputs.
'''
E = inputs.get_shape().as_list()[-1] # static
N, T = tf.shape(inputs)[0], tf.shape(inputs)[1] # dynamic
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
# position indices
position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) # (N, T)
# First part of the PE function: sin and cos argument
position_enc = np.array([
[pos / np.power(10000, (i-i%2)/E) for i in range(E)]
for pos in range(maxlen)])
# Second part, apply the cosine to even columns and sin to odds.
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1
position_enc = tf.convert_to_tensor(position_enc, tf.float32) # (maxlen, E)
# lookup
outputs = tf.nn.embedding_lookup(position_enc, position_ind)
# masks
if masking:
outputs = tf.where(tf.equal(inputs, 0), inputs, outputs)
return tf.to_float(outputs)
本身公式上没有想象的复杂,但是这里面其实展现了很多python相关的技巧。
这里的计算并非全都使用的tf,对positionenc,前面用numpy进行计算,然后用embeddinglookup的方式引入。
position_enc[:,0::2]和position_enc[:,1::2]来自numpy语法,避免了写循环和条件语句就能够完成奇数偶数计算。
另外是有很多可能在各种教材或者教程中没有的函数工具,大家可以多看看学学。
tf.AUTO_REUSE:批量化共享变量作用域的方法。
tf.tile():张量扩展,对当前张量内的数据进行一定规则的复制,保证输出张量维度不变。
责任编辑:xj
原文标题:bert之我见 - positional encoding
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
深度学习
+关注
关注
73文章
5503浏览量
121207 -
自然语言
+关注
关注
1文章
288浏览量
13355 -
nlp
+关注
关注
1文章
488浏览量
22046
原文标题:bert之我见 - positional encoding
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐











 工商网监
工商网监
评论