 新技术可有效地使用目标检测的对抗示例欺骗多目标跟踪
新技术可有效地使用目标检测的对抗示例欺骗多目标跟踪
对抗机器学习的最新研究开始关注自主驾驶中的视觉感知,并研究了目标检测模型的对抗示例。然而在视觉感知管道中,在被称为多目标跟踪的过程中,检测到的目标必须被跟踪,以建立周围障碍物的移动轨迹。由于多目标跟踪被设计为对目标检测中的错误具有鲁棒性,它对现有的盲目针对目标检测的攻击技术提出了挑战:我们发现攻击方需要超过98%的成功率来实际影响跟踪结果,这是任何现有的攻击技术都无法达到的。本文首次研究了自主驾驶中对抗式机器学习对完全视觉感知管道的攻击,并发现了一种新的攻击技术——轨迹劫持,该技术可以有效地使用目标检测的对抗示例欺骗多目标跟踪。使用我们的技术,仅在一个帧上成功的对抗示例就可以将现有物体移入或移出自驾车辆的行驶区域,从而造成潜在的安全危险。我们使用Berkeley Deep Drive数据集进行评估,发现平均而言,当3帧受到攻击时,我们的攻击可以有接近100%的成功率,而盲目针对目标检测的攻击只有25%的成功率。
01
背景
自从Eykholt等人发现第一个针对交通标志图像分类的对抗示例以来,对抗式机器学习中的若干研究工作开始关注自动驾驶中的视觉感知,并研究物体检测模型上的对抗示例。例如,Eykholt等人和钟等人针对YOLO物体探测器研究了停车标志或前车背面的贴纸形式的对抗示例, 并进行室内实验,以证明攻击在现实世界中的可行性。在这些工作的基础上,最近赵等人利用图像变换技术来提高户外环境中这种对抗式贴纸攻击的鲁棒性,并且能够在真实道路上以30 km/h的恒定速度行驶的汽车上实现72%的攻击成功率。虽然之前研究的结果令人担忧,但在自动驾驶或一般的机器人系统中,目标检测实际上只是视觉感知管道的前半部分——在后半部分,在一个称为多目标跟踪的过程中,必须跟踪检测到的目标,以建立周围障碍物的移动轨迹。这对于随后的驾驶决策过程是必需的,该过程需要构建的轨迹来预测这些障碍物的未来移动轨迹,然后相应地规划驾驶路径以避免与它们碰撞。为了确保目标检测中的高跟踪精度和对错误的鲁棒性,在多目标跟踪中,只有在多个帧中具有足够一致性和稳定性的检测结果可以包括在跟踪结果中,并且实际上影响驾驶决策。因此,自动驾驶视觉感知中的多目标跟踪对现有的盲目针对目标检测的攻击技术提出了新的挑战。例如,正如我们稍后在第3节中的分析所示,对目标检测的攻击需要连续成功至少60帧才能欺骗典型的多目标跟踪过程,这需要至少98%的攻击成功率。据我们所知,没有现有的针对目标检测的攻击能够达到如此高的成功率。在本文中,我们首次研究了自动驾驶中考虑完全视觉感知管道的对抗性机器学习攻击,即目标检测和目标跟踪,并发现了一种新的攻击技术,称为跟踪器劫持,它可以用在目标检测上的对抗示例有效地欺骗多目标跟踪过程。我们的关键见解是,虽然很难直接为假对象创建轨迹或删除现有对象的轨迹,但我们可以仔细设计对抗示例来攻击多目标跟踪中的跟踪误差减少过程,以使现有对象的跟踪结果偏离攻击者希望的移动方向。这种过程旨在提高跟踪结果的鲁棒性和准确性,但讽刺的是,我们发现攻击者可以利用它来大大改变跟踪结果。利用这种攻击技术,少至一帧的对抗示例足以将现有物体移入或移出自主车辆的行驶区域,从而导致潜在的安全危险。我们从Berkeley Deep Drive数据集随机抽样的100个视频片段中选择20个进行评估。在推荐的多目标检测配置和正常测量噪声水平下,我们发现我们的攻击可以在少至一帧和平均2到3个连续帧的对抗示例中成功。我们重复并比较了之前盲目针对目标检测的攻击,发现当攻击连续3帧时,我们的攻击成功率接近100%,而盲目针对对象检测攻击的成功率只有25%。
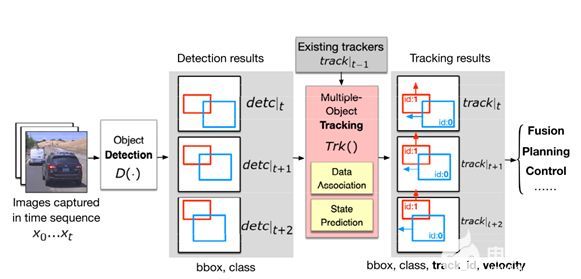
图表 1自动驾驶中的完整视觉感知管道,即目标检测和多目标跟踪
本文贡献
考虑到自动驾驶中完整的视觉感知管道,即目标检测和运动检测,我们首次研究了对抗性机器学习攻击。我们发现,在不考虑多目标跟踪的情况下,盲目针对目标检测的攻击至少需要98%的成功率才能真正影响自动驾驶中的完整视觉感知管道,这是任何现有攻击技术都无法达到的。·我们发现了一种新的攻击技术——轨迹劫持,它可以有效地利用物体检测中的对抗示例来欺骗移动终端。这种技术利用了多目标跟踪中的跟踪误差减少过程,并且可以使仅在一帧内成功的对抗示例将现有物体移入或移出自主车辆的行驶距离,从而导致潜在的安全危险。·使用Berkeley Deep Drive数据集进行的攻击评估表明,我们的攻击可以在少至一帧、平均只有2到3个连续帧的情况下获得成功,当3个连续帧受到攻击时,我们的攻击成功率接近100%,而盲目针对目标检测的攻击成功率仅为25%。
多目标跟踪
多目标跟踪的目的是识别视频帧序列中的物体及其运动轨迹。随着物体检测的进步,通过检测进行跟踪已经成为多目标跟踪的范例,其中检测步骤识别图像中的物体,跟踪步骤将物体链接到轨迹(即轨迹)。如图1所示,在时间t检测到的每个物体将与动态模型(例如,位置、速度)相关联,动态模型表示物体的过去轨迹(track| t1)。,每一条轨迹都用卡尔曼滤波器来维护状态模型,其以预测-更新循环运行:预测步骤根据运动模型估计当前对象状态,更新步骤采用检测结果detc|t 作为测量值来更新其状态估计结果track|t。检测到的物体与现有跟踪器之间的关联被公式化为二分匹配问题, 基于轨迹和被检测对象之间的成对相似性损失,最常用的相似性度量是基于空间的损失,它测量边界框或bbox之间的重叠量。为了减少这种关联中的误差,在卡尔曼滤波预测中需要精确的速度估计。由于摄像机帧的离散性,卡尔曼滤波器使用速度模型来估计下一帧中被跟踪对象的位置,以补偿帧间对象的运动。然而,如后面第3节中所述,这种错误减少过程意外地使得进行跟踪者劫持成为可能。多目标跟踪通过两个阈值管理轨迹的创建和删除。具体来说,只有当对象被持续检测到一定数量的帧时,才会创建一个新的轨迹,该阈值将被称为命中数,或用H指代,这有助于过滤掉物体检测器偶尔产生的误报。另一方面,如果在R帧的持续时间(或者称为保留时间)内没有对象与轨迹相关联,轨迹将被删除。它可以防止轨迹由于物体检测器罕见的假阴性而被意外删除。R和H的配置通常既取决于检测模型的精度,也取决于帧速率(fps)。先前的研究提出了R = 2帧/秒和H = 0.2帧/秒的配置,对于普通的30帧/秒视觉感知系统给出了R = 60帧和H = 6帧。第3节的评估将表明,一个盲目地以目标检测为目标的攻击需要不断地欺骗至少60帧(R)来擦除一个对象,而我们提出的轨迹劫持攻击可以通过少到一帧,平均只有2~3帧的攻击,来伪造持续R帧的对象,或在跟踪结果中抹除H帧的目标对象。
02
轨道劫持攻击
多目标跟踪可以选择包括一个或多个相似性度量来匹配跨帧的对象。常见的度量包括边界框重叠、对象外观、视觉表示和其他统计度量。作为多目标跟踪对抗威胁的首次研究,我们选择了基于并集的交集(IoU)的匈牙利匹配作为我们的目标算法,因为它是最广泛采用和标准化的相似性度量,不仅是最近的研究,两个真实世界的自动驾驶系统,百度阿波罗和Autoware也采用了这一度量 ,这确保了我们工作的代表性和实际意义。
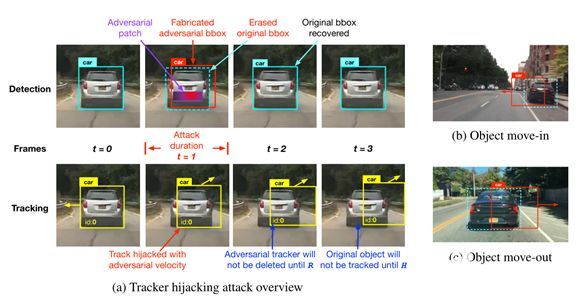
图表 2描述轨迹劫持攻击流程(a),以及两种不同的攻击场景:对象移入(b)和移出(c),其中轨迹劫持可能导致严重的安全后果,包括急停和追尾。
图2a展示了本文发现的轨迹劫持攻击,其中用于对象检测的对抗示例(例如,前车上的对抗补丁)可以欺骗检测结果,只用一帧就极大地偏离多目标跟踪中目标对象(例如,前车)的轨迹。如图所示,目标汽车最初在t0时被跟踪到以预测的速度向左。攻击开始于时间t1,在汽车后部贴上对抗的补丁。该补丁是精心生成的,以两个对立的目标欺骗目标检测器:(1)从检测结果中删除目标对象的边界框;(2)制作一个类似形状的边界框,但稍微向攻击者指定的方向移动。所构造的边界框(t1处检测结果中的红色边界框)将与跟踪结果中的目标对象的原始轨迹相关联,我们称之为轨迹劫持,并且因此将向轨迹给出朝向攻击者期望的方向的假速度。图2a中所示的轨迹劫持仅持续一帧,但其对抗效果可能持续数十帧,这取决于MOT参数R和H(在第2节中介绍)。例如,在攻击后的时间t2,所有的检测边界框都恢复正常,但是,两个不利影响持续存在: (1)目标对象虽然在检测结果中被恢复,但是将不会被跟踪,直到达到命中计数(H),并且在此之前,该对象在跟踪结果中仍然丢失;(2)受攻击者诱导速度劫持的轨迹将不会被删除,直到一个保留时间(R)过去。然而,值得注意的是,我们的攻击在实践中并不总是成功的,因为如果轨迹在短时间的攻击期间没有偏离对象的真实位置足够远,恢复的对象可能仍然与其原始轨迹相关联。我们的实验结果表明,当使用对抗示例成功攻击3个连续帧时,我们的攻击通常达到接近100%的成功率。这种持续的不良效应可能会在自动驾驶场景中造成严重的安全后果。我们强调两种可能导致紧急停车甚至追尾事故的攻击场景:
攻击场景1: 目标物体移入
如图2b所示,可以在路边物体(例如停放的车辆)上放置对抗贴片,以欺骗经过的自驾车辆的视觉感知。在检测结果中,生成对抗补丁以导致目标边缘框向道路中心平移,并且被劫持的轨迹将在受害车辆的感知中表现为在前方加塞的移动车辆。如果按照朱等人的建议将R配置为2 fps,该跟踪器将持续2秒钟,并且这种情况下的轨迹劫持可能导致紧急停止和潜在的追尾碰撞。
攻击场景2:目标物体移出
同样,轨迹劫持攻击也可以使受害自驾车辆前方的物体偏离道路,导致撞车,如图2c所示。如果H使用0.2 fps的推荐配置,则应用于前车后部的对抗贴片可能会欺骗后面的自动车辆的多目标跟踪器相信物体正在偏离其路线,并且前车将在200ms的持续时间内从跟踪结果中消失,这可能会导致受害者的自动驾驶汽车撞上前车。

我们的攻击目标是一阶卡尔曼滤波器,它预测一个状态向量,包含检测到的对象与时间相关的位置和速度。对于数据关联,我们采用最广泛使用的并集的交集(IoU)作为相似性度量,通过匈牙利匹配算法计算边缘框之间的IoU,以解决将连续帧中检测到的边缘框与现有轨迹关联的二分匹配问题。多目标跟踪中的这种算法组合在以前的研究和现实世界中是最常见的。现在描述我们的方法,即生成一个敌对补丁,操纵检测结果劫持轨迹。详见Alg.1,给定一个目标视频图像序列,攻击迭代地找到成功劫持所需的最少干扰帧,并为这些帧生成对抗补丁。在每次攻击迭代中,对原始视频剪辑中的一个图像帧进行处理,给定目标对象的索引K,该算法通过求解等式1找到放置对抗边缘框的最佳位置pos,以劫持目标对象的轨迹。然后,攻击使用对抗补丁构建针对目标检测模型的对抗帧,使用等式2作为损失函数,擦除目标对象的原始边缘框,并在给定位置构建对抗边缘框。轨迹随后被偏离其原始方向的对抗帧更新,如果下一帧中的目标对象没有通过多目标跟踪算法与其原始跟踪器相关联,则攻击成功;否则,对下一帧重复该过程。我们下面讨论这个算法中的两个关键步骤。
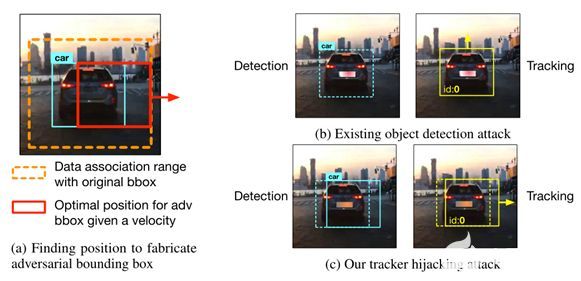
图表 3现有的目标检测攻击和我们的轨迹劫持攻击的比较。简单擦除bbox的攻击对跟踪输出没有影响(b),而利用精心选择的位置伪造bbox的轨迹劫持攻击成功地将轨迹重定向到攻击者指定的方向(c)。
寻找对抗包围盒的最佳位置
为了偏离目标对象K的跟踪器,除了移除其原始边界框detc|t[K] 之外,攻击还需要制造一个向指定方向移动δ的对抗框。这就变成了优化问题(Eq.1),即找到使检测框和现有跟踪器之间的匈牙利匹配(M())的损失最大化的平移向量δ,使得边界框仍然与其原始跟踪器相关联(M ≤ λ),但是偏移足够大,以给轨迹提供对抗速度。请注意,我们还将移动的边界框限制为与补丁重叠,以方便对抗示例的生成,因为敌对扰动通常更容易影响其附近的预测结果,尤其是在物理环境中。
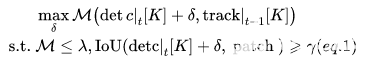
生成对抗目标检测的补丁
类似于现有的针对目标检测模型的对抗性攻击,我们还将对抗性补丁生成公式化为等式2中所示的优化问题。现有的不考虑多目标跟踪的攻击直接将目标类(如停止标志) 的概率降到最低从而在检测结果中抹去对象。然而,如图3b所示,这种对抗示例在欺骗多目标跟踪方面非常无效,因为即使在检测边界框被擦除之后,跟踪器仍将跟踪R帧。相反,我们的跟踪器劫持攻击的损失函数包含两个优化目标:(1)最小化目标类概率以擦除目标对象的边缘框;(2)在攻击者想要的位置以特定的形状伪造对抗边缘框以劫持轨迹。
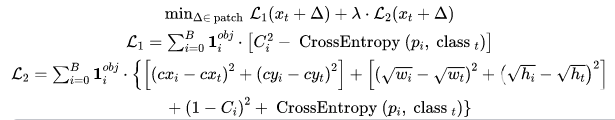
03
攻击评估
评估指标
我们将成功的攻击定义为当攻击停止时,检测到的目标对象的边界框不再与任何现有的跟踪器相关联。我们使用物体检测的对抗示例成功所需的最小帧数来衡量我们的轨迹劫持攻击的有效性。攻击效果高度依赖于原轨迹的方向向量与敌手目标的差异。例如,如果选择对抗方向与其原始方向相反,攻击者可以在只有一帧的情况下对跟踪器进行大的移动,而如果敌手方向恰好与目标的原始方向相同,则很难使跟踪器偏离其已建立的轨迹。为了控制变量,我们在前面定义的两种攻击场景中测量攻击所需的帧数:即目标对象移入和移出。具体来说,在所有的移入场景中,我们选择沿着道路停放的车辆作为目标,攻击目标是将轨迹移动到中心,而在所有的移出场景中,我们选择向前移动的车辆,攻击目标是将目标轨迹移离道路。
数据集
我们从Berkeley Deep Drive数据集中随机采样了100个视频片段,然后手动选择10个适合对象移入场景,另外10个适合对象移出场景。对于每个片段,我们手动标记一个目标车辆,并将补丁区域标注为其后面的一个小区域,如图3c所示。所有视频每秒30帧。
实施细节
我们使用Python实现了我们的目标视觉感知管道,使用YOLOv3作为目标检测模型,因为它在实时系统中非常受欢迎。对于多目标跟踪实现,我们在sklearn包中使用了称为线性赋值的匈牙利匹配实现来进行数据关联,并在OpenCV中使用的基础上提供了卡尔曼滤波器的参考实现。攻击的有效性取决于卡尔曼滤波器的配置参数,称为测量噪声协方差(cov)。cov是对系统中有多少噪声的估计,当更新轨迹时,较低的cov值将使卡尔曼滤波器对在时间t的检测结果更有信心,而较高的cov值将使卡尔曼滤波器在时间t 更信任它先前在时间t- 1的预测。这种测量噪声协方差通常基于实际中检测模型的性能来调整。如图4a所示,我们在从非常小(103)到非常大(10)的不同cov配置下评估我们的方法,而在实践中cov通常设置在0.01和10之间。

图表 4 在正常的测量噪声协方差范围(a)中,尽管有(R,H)设置,我们的轨迹劫持攻击仅需要对抗示例平均只欺骗2~3个连续的帧来成功地带偏目标轨迹。我们还比较了在不同的攻击者能力下,轨迹劫持的成功率与以前对目标检测器的敌对攻击的成功率,即对抗示例可以可靠地欺骗目标检测器所需的连续帧的数量(b)
评估结果
图4a表明了在20个视频剪辑上成功的轨道劫持,物体检测上的对抗示例需要欺骗的平均帧数。虽然在fps为30时推荐R = 60、H = 6的配置,我们仍然测试不同的保留时间(R)和命中数(H)组合,这是因为现实部署通常比较保守,使用较小的R和H。结果表明,尽管有(R,H)配置,轨迹劫持攻击仅需要平均在2到3个连续帧中成功的目标检测对抗示例就能成功。我们还发现,即使只有一帧成功的对抗示例,当cov分别为0.1和0.01时,我们的攻击仍有50%和30%的成功率。有趣的是,我们发现对象移入通常比对象移出需要更少的帧。原因是,在驶入场景中停放的车辆(图2b)相对于自主车辆自然具有驶离速度。因此,与移出攻击相比,移入攻击触发了攻击者期望的速度和原始速度之间的较大差异。这使得原始对象一旦恢复,就更难正确关联,使得劫持更容易。图4b显示了我们的攻击和以前盲目针对目标检测的攻击(称为检测攻击)的成功率。我们复制了钟等人最近针对目标检测的对抗性补丁攻击,该攻击针对自动驾驶环境,并通过真实世界的汽车测试显示了其有效性。在这种攻击中,目标是从每一帧的检测结果中擦除目标类。在两种(R,H)设置下进行评估,我们发现我们的轨迹劫持攻击即使只攻击3帧也能达到优越的攻击成功率(100%),而检测攻击需要可靠地欺骗至少R个连续帧。当按照30 fps的帧率将R设置为60时,检测攻击需要在受害自驾车行驶的同时对抗性补丁能够持续成功至少60帧。这意味着超过98.3% (59/60)的对抗示例成功率,这在以前的研究中从未达到。请注意,检测攻击在R之前仍然可以有高达约25%的成功率。这是因为检测攻击导致对象在某些帧中消失,并且当车辆航向在此消失期间发生变化时,仍然有可能导致原始对象在恢复时与原始轨迹中的轨迹预测不匹配。然而,由于我们的攻击是为了故意误导多目标跟踪中的轨迹预测,我们的成功率要高得多(3-4倍),并且可以在少至3帧的攻击下达到100%。
04
讨论与总结
对该领域未来研究的启示
如今,针对自动驾驶中视觉感知的对抗性机器学习研究,无论是攻击还是防御,都使用目标检测的准确性作为事实上的评估指标。然而,正如在我们的工作中具体显示的,在不考虑多目标跟踪的情况下,对检测结果的成功攻击并不意味着对多目标跟踪结果的同等或接近成功的攻击,多目标跟踪结果是真实世界自动驾驶中视觉感知任务的最终输出。因此,我们认为这一领域的未来研究应考虑:(1)使用多目标跟踪准确度作为评估指标;(2)不仅仅关注目标检测,还应研究多目标跟踪特有的弱点或多目标跟踪与目标检测之间的相互作用,这是一个目前尚未充分探索的研究领域。这篇论文标志着第一次朝两个方向努力的研究。
实用性提升
我们的评估目前都是用捕获的视频帧进行数字处理的,而我们的方法在应用于生成物理补丁时应该仍然有效。例如,我们提出的对抗补丁生成方法可以自然地与以前工作提出的不同技术相结合,以增强物理世界中的可靠性。
通用性提高
虽然在这项工作中,我们侧重于使用基于IoU的数据关联的多目标跟踪算法,但我们寻找位置来放置对抗边界框的方法通常适用于其他关联机制(例如,基于外观的匹配)。我们针对YOLOv3的对抗示例生成算法也应该适用于其他具有适度适应性的目标检测模型。我们计划提供更多真实世界端到端视觉感知管道的参考实现,为未来自动驾驶场景中的对抗学习研究铺平道路。
fqj
-
滤波器
+关注
关注
161文章
7924浏览量
179587 -
目标检测
+关注
关注
0文章
213浏览量
15724
发布评论请先 登录
相关推荐
使用RTSP摄像头执行多摄像头多目标Python演示,缺少输出帧是怎么回事?
探索对抗训练的概率分布偏差:DPA双概率对齐的通用域自适的目标检测方法

浅谈多目标优化约束条件下充电设施有序充电控制策略
视频目标跟踪从0到1,概念与方法

使用STT全面提升自动驾驶中的多目标跟踪
IP 地址欺骗:原理、类型与防范措施
目标检测识别主要应用于哪些方面

多目标智能识别系统
基于深度学习的小目标检测
基于GIS的SAR多目标智能识别系统
基于 FPGA 的目标跟踪电磁炮系统
多目标跟踪算法总结归纳





 工商网监
工商网监
评论