 机器学习中流式数据处理的使用场景及相关技术介绍
机器学习中流式数据处理的使用场景及相关技术介绍
在工业界,当我们提到实时数据机器学习时,常常可以听到如下讨论:
他们希望有一个模型,这个模型利用最近历史信息来进行预测分析。举一个天气的例子,如果最近几天都是晴天,那么未来几天极小概率会出现雨雪和低温天气
这个模型还需要是可更新的。当数据流经系统时,模型是可以随之进化升级。举个例子,随着业务规模的扩大,我们希望零售销售模型仍然保持准确。
实时机器学习应用是人工智能真正落地服务化的关键一步,因为工业界大部分场景下数据都是实时产生的。因此作为一名合格的人工智能领域专家,掌握流式场景下的算法设计必不可少。 本文主要介绍流式数据处理的使用场景、相关技术,并从服务管理的角度,介绍了针对流式计算服务的设计及关键指标。主要面向希望了解流式计算、服务管理的朋友们。
流式计算的使用场景
01
首先,当前业界已经有非常多数据处理的方式了,为什么还需要流式数据处理?要回答这个问题,我们先回顾一下传统的的数据处理架构。 传统的数据处理架构是一种典型的以数据库为中心,适应存储事务性数据处理的场景。由于数据处理能力优先,在该架构下,往往数据都是以批量的方式进行处理,例如:批量写入数据库、批量读取数据库进行数据处理。这种架构在面对实时性较低的场景中较为有效,但是在对实时性较高的场景则不太有效,例如:自动驾驶场景、工业机器人场景、基于会话的用户统计等。
因此,流式计算或流式数据处理被提出。其实流处理它最接近数据产生的自然规律,只不过过去我们没有流处理能力,只能做一些特殊的处理才能真正地使用流数据,比如将流数据攒成批量数据再处理,不然无法进行大规模的计算。使用流数据并不新鲜,新鲜的是我们有了新技术,从而可以大规模、灵活、自然和低成本地使用它们。 流式处理的核心目标有以下三点:
低延迟:近实时的数据处理能力
高吞吐:能处理大批量的数据
可以容错:在数据计算有误的情况下,可容忍错误,且可更正错误
流式处理框架
02
典型的流处理框架结合了消息传输层技术以及流处理层技术。具体如图所示:
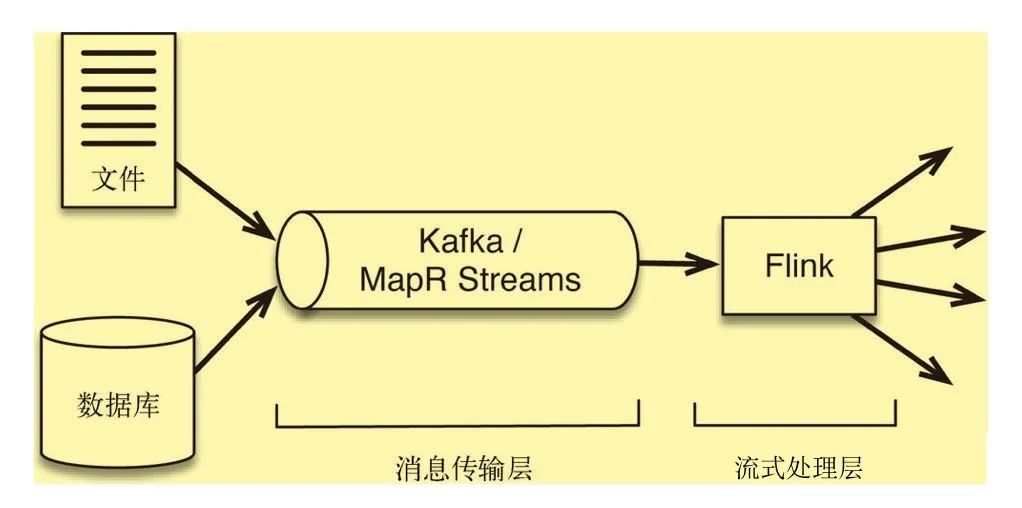
消息传输层的引入流处理层提供了以下支持:
消息传输层的一个作用是作为流处理层上游的安全队列,它相当于缓冲区,可以将事件数据作为短期数据保留起来,以防数据处理过程发生中断
具有持久性的好处之一是消息可以重播。实现时间穿梭
在当前典型的流处理技术中,有这么几类:
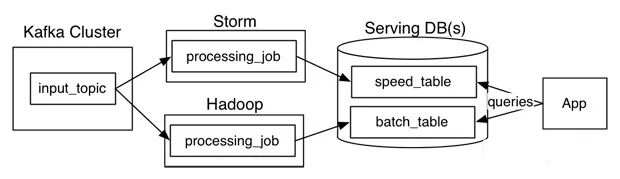
Lambda架构
基于Lambda架构,实现了离线计算的精确性的同时,且获得了流式数据处理的实时性。但是,由于要开发同样逻辑的代码,开发、维护成本高
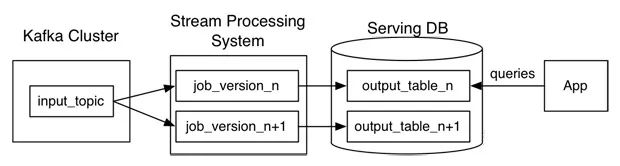
Kappa架构为了解决lambda架构中维护两套同样逻辑的代码,kappa架构提出使用流式处理解决上述问题。当需要重新处理、计算数据时,使用另一个流程处理的作业(可以是相同的、优化的版本)进行数据处理。
spark streaming
基于小批量进行数据处理
Flink
以上几种技术中,flink既可以实现低延迟、高吞吐,还可以实现容错。
Flink概况
03
Flink技术除支持流处理外,还支持批处理,其架构如下图所示:
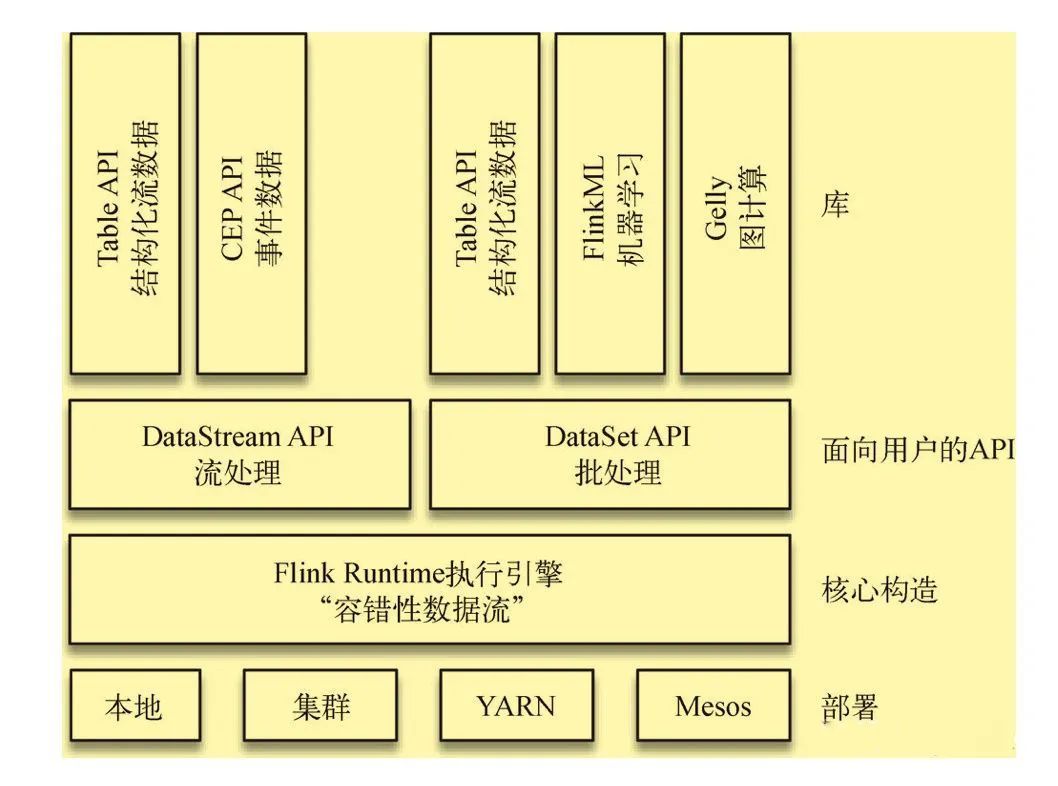
另外,Flink具有分布式的特点,具体体现在它能够在成百上千台机器上运行,它将大型的计算任务分成许多小的部分,每个机器执行一个部分。 Flink能够自动地确保在发生机器故障或者其他错误时计算能持续进行,或者在修复bug或进行版本升级后有计划地再执行一次。这种能力使得开发人员不需要担心失败。 Flink本质上使用容错性数据流,这使得开发人员可以分析持续生成且永远不结束的数据(即流处理)。因为不用再在编写应用程序代码时考虑如何解决问题,所以工程师的时间得以充分利用,整个团队也因此受益。好处并不局限于缩短开发时间,随着灵活性的增加,团队整体的开发质量得到了提高,运维工作也变得更容易、更高效。Flink让应用程序在生产环境中获得良好的性能。
总体来说,Flink的主要特性:
符合产生数据的自然规律:支持流式数据处理
发生故障后仍保持准确:具体容错机制(exactly once)
及时给出所需结果:低延迟、实时性强
时间概念
在流数据处理的体系中,时间是一个重要的概念。总体来说,可分为以下三种时间:
事件时间:即事件实际发生的时间。更准确地说,每一个事件都有一个与它相关的时间戳,并且时间戳是数据记录的一部分(比如手机或者服务器的记录)。事件时间其实就是时间戳。处理时间,即事件被处理的时间。
处理时间:其实就是处理事件的机器所测量的时间
摄取时间:也叫作进入时间。它指的是事件进入流处理框架的时间
Flink允许用户根据所需的语义和对准确性的要求选择采用事件时间、处理时间或摄取时间定义窗口
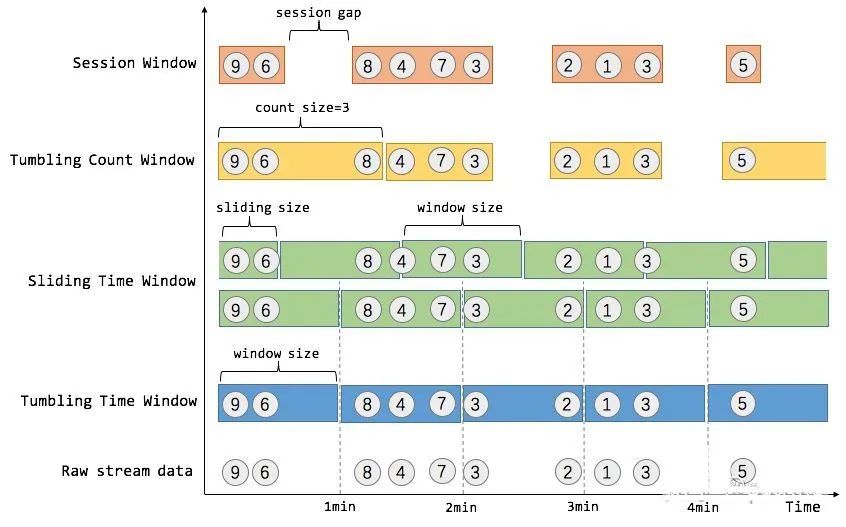
窗口
窗口是一种机制,它用于将许多事件按照时间或者其他特征分组,从而将每一组作为整体进行分析(比如求和)
时间穿梭
流处理器支持事件时间,这意味着将数据流“倒带”,用同一组数据重新运行同样的程序,会得到相同的结果
水印
假设第一个窗口从1000开始(即从10时0分0秒开始),需要计算从1000到1000的数值总和。当时间就是记录的一部分时,我们怎么知道1000已到呢?换句话说,我们怎么知道盖有时间戳1059的元素还没到呢?Flink通过水印来推进事件时间。水印是嵌在流中的常规记录,计算程序通过水印获知某个时间点已到。
有状态的计算
流式计算分为无状态和有状态两种情况:
无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过90度时发出警告。
有状态的计算则会基于多个事件输出结果。
数据处理容错及一致性保障
在有状态的数据处理中,如何保障数据的一致性是一个关键点。保障一致性的方式有以下三种:
at most once:这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失
at least once:这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算
exactly once:这指的是系统保证在发生故障后得到的计数结果与正确值一致
Flink如何保证exactlyonce呢?它使用一种被称为“检查点”的特性,在出现故障时将系统重置回正确状态。
有限流处理是无限流处理的一种特殊情况,它只不过在某个时间点停止而已。此外,如果计算结果不在执行过程中连续生成,而仅在末尾处生成一次,那就是批处理(分批处理数据)
原文标题:流式计算、数据处理及相关技术
文章出处:【微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
人工智能
+关注
关注
1791文章
46737浏览量
237302 -
机器学习
+关注
关注
66文章
8367浏览量
132358
原文标题:流式计算、数据处理及相关技术
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OTA测试暗箱的技术原理和应用场景
移动终端测试仪的技术原理和应用场景
便携式示波器的技术原理和应用场景
实时示波器的技术原理和应用场景
高速数字化仪的技术原理和应用场景
光学透过率测量仪的技术原理和应用场景
超声波测厚仪的技术原理和应用场景
智能IC卡测试设备的技术原理和应用场景
NFC协议分析仪的技术原理和应用场景
RISC-V适合什么样的应用场景
FPGA与MCU的应用场景
AIOT是什么意思?AIOT的应用场景和作用






 工商网监
工商网监
评论