 SVE架构特性和指令基本用法介绍
SVE架构特性和指令基本用法介绍
SVE(Scalable Vector Extension)是arm AArch64架构下的下一代SIMD指令集,旨在加速高性能计算,SVE引入了很多新的架构特点, 比如
• 可变矢量长度
• 每通道预测
• 聚集加载和分散存储
• 横向操作
本文将对SVE做个基本介绍。
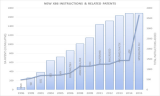
1. SIMD指令发展史 intel vs arm
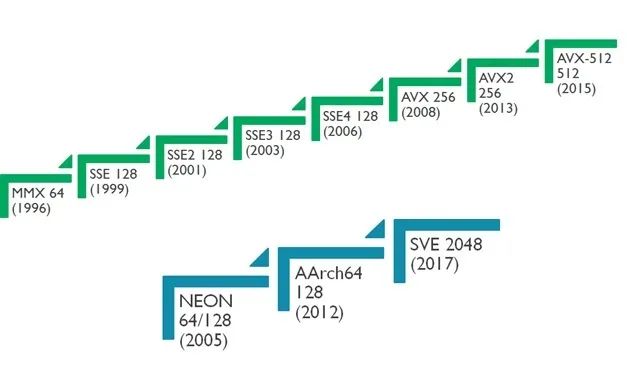
从上图我们可以看出,SIMD指令总体趋势是向着越来越长的方向发展的,到了arm SVE,最长可以支持2048位的矢量操作。
2. 背景
Armv7的高级SIMD (即arm NEON 或“MPE” 多媒体处理引擎) 指令集自2005年发布,已经面世十几年了。Armv7 NEON的主要特性如下:
• 支持8/16/32位整数操作,支持非IEEE兼容单精度浮点操作,支持指令条件执行
• 32个64位矢量寄存器,也可视为16个128位矢量寄存器
• 旨在CPU端加速多媒体处理任务
在升级到armv8架构时,AArch64 NEON指令集做出了许多改进,比如:
• 支持IEEE兼容单精度和双精度浮点操作和64位整数矢量操作
• 32个128位矢量寄存器
• 这些改进使NEON指令集更适用于通用计算,而不仅仅是多媒体计算
但是到了现在,armv8的新市场需要更彻底的SIMD指令改进。我们需要能够并行处理非常规数据和复杂数据结构,也需要更长的矢量,SVE因此而生,SVE旨在加速高性能计算。
3. SVE特性
SVE是armv8 AArch64架构的下一代SIMD指令集,它不是NEON的替代,而是聚焦于高性能计算。主要特性如下:
• 可变矢量长度
• 128位的整数倍。 最高可支持2048位
• 不同的实现可以适应不同的应用场景,不用更改指令集
• 每通道预测
• 支持复杂嵌套循环和if/then/else条件跳转, 没有循环尾数。
• 聚集加载和分散存储支持复杂数据结构,如步长数据存取、数组索引,链表等。
• 横向操作
• 支持基本的reduction操作,降低循环依赖性
4. SVE寄存器
SVE寄存器有两种:矢量寄存器和预测寄存器。
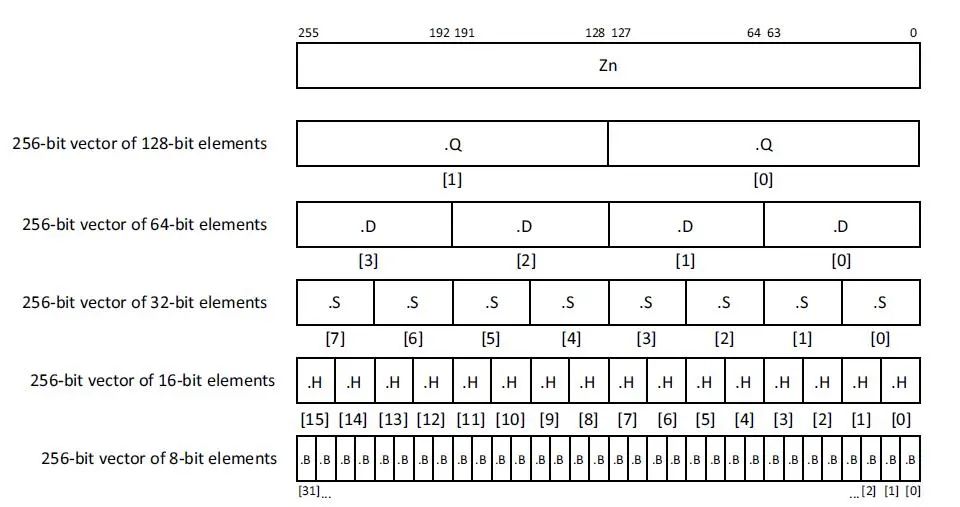
SVE共有32个可变长矢量寄存器Z0-Z31(128位的整数倍, 最高可达2048位) ,其中Z0-Z31的低128位[127:0],与AArch64 SIMD&FP寄存器V0-V31共享硬件资源。假设SVE的矢量长度为256,其矢量寄存器视图如下。SVE支持8/16/32/64位整数操作和单精度/双精度浮点操作。
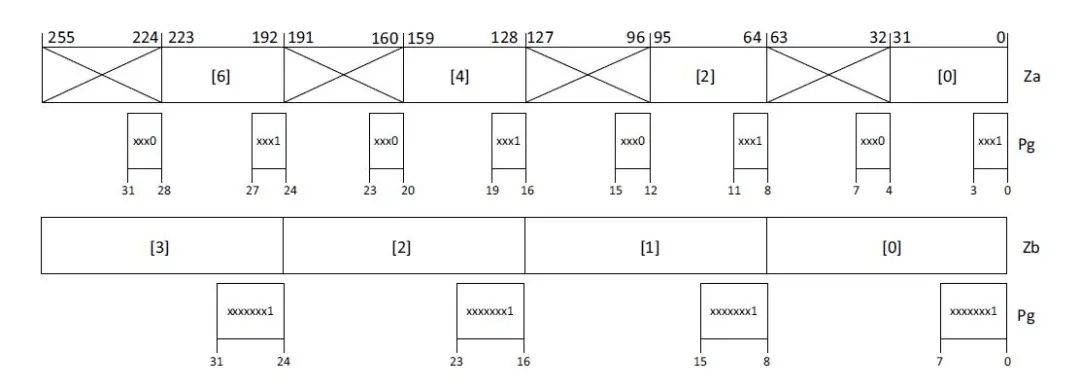
SVE预测寄存器用于控制每通道操作,有16个可变长预测寄存器P0-P15。每一个预测寄存器的位对应矢量寄存器的字节。假设SVE的矢量长度为256,预测寄存器在管理32位和64位操作时,其视图如下。在控制32位数据操作时,如果Pg寄存器的最低为1,则该通道操作为激活状态,该通道操作结果被正常存储到目的寄存器;如果Pg寄存器的最低为0,则该通道操作为未激活状态,该通道操作结果不会被存储到目的寄存器,目的寄存器的该通道数据有两种可能:
• 指令指定为Pg/z - 清零模式,该通道数据被清零。
• 指令指定为Pg/m – 合并模式,该通道数据保持原值
5. SVE指令实例
下面我们通过一些实例来介绍常用SVE指令的用法。
a. 矢量加法
大家也许都熟悉NEON的指令格式(如下),NEON指令通过对指令助记符添加“f”前缀来区分整数操作和浮点操作,如“add”和“fadd”;另外通过寄存器后缀“.2s”、“.4s”、“.2d”表示操作两个32位、四个32位数据、两个64位数据。
• add v0.4s, v0.4s, v1.4s
• fadd v0.2s, v0.2s, v1.2s
• fadd v0.2d, v0.2d, v1.2d
SVE指令也通过对指令助记符添加 “f” 前缀来区分整数操作和浮点操作。但是SVE是未知矢量长度编程,因此在指令中我们只需要指明操作数据类型就可以了。
• add z0.s, z0.s, z1.s
• fadd z0.s, z0.s, z1.s
• fadd z0.d, z0.d, z1.d
b. 矢量加载
对于加载指令,NEON指令通过助记符“ld1”、“ld2”表示加载一维数组、二维数组;通过寄存器后缀“.8h”、“.4s”表示加载八个16位、四个32位数据。
• ld1 {v0.8h}, [x1]
• ld1 {v0.4s}, [x1]
• ld2 {v0.4s, v1,4s}, [x1]
SVE加载指令添加指令助记符后缀 “h“、”w“表示读取存储元素宽度;寄存器后缀”.h“、”.s“表示元素在寄存器中的宽度。寄存器元素宽度必须大于等于读取存储宽度。对于加载指令,读取元素可以通过符号扩展或者零扩展填充到矢量寄存器;对于存储指令,每个矢量元素被截断后存储到内存中。
• ld1h {z0.h}, p0/z, [x1]
• ld1w {z0.s}, p0/z, [x1]
• ld2w {z0.s, z1.s}, p0/z, [x1]
6. 小结
本文简单介绍了SVE架构特性和指令基本用法,后续还会再写文章介绍如何在C程序中利用SVE。
原文标题:一文了解SIMD指令集SVE(可伸缩矢量扩展),加速高性能计算
文章出处:【微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
指令集
+关注
关注
0文章
222浏览量
23366 -
SIMD
+关注
关注
0文章
33浏览量
10274
原文标题:一文了解SIMD指令集SVE(可伸缩矢量扩展),加速高性能计算
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Matter SVE认证经验分享
数控车床m99指令的用法
指令集架构与微架构的区别
简述微处理器的指令集架构
微处理器的指令集架构介绍
三菱PLC传送指令的用法
PLC中SFTL指令的用法
数控车床m99指令的用法
嵌入式系统的概念与范围开发 指令集架构要怎么选才合适?






 工商网监
工商网监
评论