 通用人工智能的多模态通用技术
通用人工智能的多模态通用技术

现有的大多数人工智能模型和方法仍属于窄人工智能,也被称为弱人工智能(weak artificial intelligence)。相对而言,强人工智能(strong artificial intelligence)期望机器能像人一样思考、推理,能处理各种任务,比肩人类的智能水平(human-like or human-level intelligence)。与强人工智能相比,现有通用人工智能更加强调机器的“泛 化”能力,包括场景泛化(即模型从单一场景泛化 至多个场景)、模态泛化(即一个模型适用于多种 模态的任务)、任务泛化(即一个模型可以处理多种类型的任务)等。
通用人工智能目前仍然处于发展初期,是对现有窄/弱人工智能的反思、补充和改进,也是通往强人工智能道路上的重要路线。通用人工智能所研究的是一个智能系统应该具备哪些能力,并且运用这些能力解决各式各样的复杂问题。
通用人工智能的多模态通用技术
现实生活中,人类接收的信息模态多种多样,如视觉、声音、文字、嗅觉、触觉等。人类可以综合运用多种模态的信息对事物进行理解和推理。多模态学习是通用智能需要解决的关键问题之一,其任务可以归结为两个基本类:多模态表征学习和模态转换。需要指出的是,这两个问题并非不相关,比如表征可以用来做模态转换。下面介绍几种典型的多模态学习任务。
多模态表征学习和融合
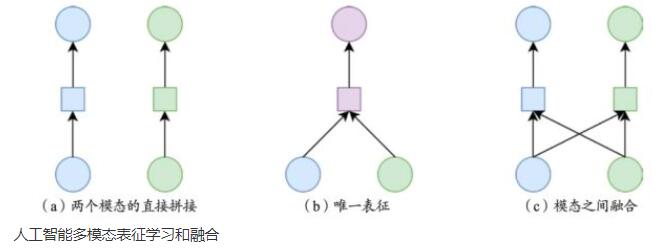
多模态表征学习指的是学习包含多个模态的样本表征,比如视频里可能包含的视觉信息、声音信息等,使得表征能够反映所包含的多个模态信息,以帮助理解识别等任务。最直接的方法是分别处理各个模态,得到每个模态的表征,再将其直接拼接起来作为最后的表征;也可以最终只产生一个表征,把不同模态的表征融合成一个表征;也可以继续把融合的表征做进一步处理,以生成更强的表征;还可以在产生表征的过程中,不停地进行模态之间的信息交互或者融合,以增强每个模态的表征。
多模态协同学习
多模态协同学习指的是利用模态之间的关联,借助其他一个或者多个模态,来帮助某一模态或者多个模态建模和学习。模态之间的关联信息非常常见,比如人在说话的时候,既有声音模态,也有视觉(唇语)模态,如人脸表情或者行为动作;比如互联网上的图片,通常有文件名等;比如在视频中,视频帧可能有相应的声音(语音或者音乐),也可能有文字脚本。人类对单一模态的理解,也是通过联合其他模态信息进行分析的。多模态协同学习的要领在于把关联转换成合适的约束,以及从各个模态获取合适的信息形成约束。例如图像和文本(比如图像及其文件名)有一一对应关系。
借助于物体的属性描述来帮助图像识别建模,在某种意义上也是多模态协同学习。例如,对狗的识别,我们都清楚地了解狗是由哪些部分组成的,具有怎样的属性特征,比如它有4条腿、尾巴、毛发等。但是在目前主流的物体识别中,这种信息没有被加进去,“狗”只是作为一个标签。而人类从图像里识别狗的时候,头脑中有很多狗的图像认知信息,同时也从别的渠道获得狗的其他知识,如组成方式等。所以,建模时需要把关于狗的额外知识信息加进去,来提升建模识别性能,也会提升模型的鲁棒性。

多模态统一表征学习
多模态统一表征学习指的是把不同模态映射到 同一个特征空间,使得不同模态在这个特征空间里可以直接比较(比如欧氏距离),比较的时候不用 区分特征来自什么模态。多模态任务可以是把一幅图片转变成一段文字或者一首诗,或者将文字转化成一幅图像;以及在文字、图片或者视频搜索中,如果图像和文本的特征都转换到同一个空间中,那我们就可以进行统一的搜索,而不再区分不同的模态。
人类具有在不同模态之间快速映射的能力,比如看到一个场景,我们的头脑会快速“搜索”到应景的一首歌、一段文字或者一首诗。多模态统一表示是模拟人类这个能力的一种实现方法。多模态统一表征问题的主要研究点在于如何定义关系保持和寻找合适的映射,以及对大规模数据和实际问题的探索。目前已经有了实际系统的探索,如“小冰写诗”。

责任编辑:YYX
-
人工智能
+关注
关注
1820文章
50364浏览量
267016 -
通用技术
+关注
关注
0文章
7浏览量
7321
发布评论请先 登录
人工智能多模态与视觉大模型开发实战 - 2026必会
浅谈人工智能(2)

声智科技助力第一届产学结合高校通用人工智能大赛决赛圆满落幕
云知声荣获2025人工智能治理示范案例
四维图新亮相2025国际前瞻人工智能安全与治理大会
航天宏图人工智能技术深度赋能社会治理现代化
浅析多模态标注对大模型应用落地的重要性与标注实例
云天励飞亮相2025深圳通用人工智能大会
勇艺达亮相2025深圳通用人工智能大会
商汤科技多模态通用智能战略思考
挖到宝了!人工智能综合实验箱,高校新工科的宝藏神器
挖到宝了!比邻星人工智能综合实验箱,高校新工科的宝藏神器!
聚焦前沿,赋能AI教学!华清远见第32届全国高校人工智能师资班(多模态大模型与具身智能)圆满落幕!




评论