 深度学习图像识别解释方法的概述
深度学习图像识别解释方法的概述
图像识别(即 对图像中所显示的对象进行分类)是计算机视觉中的一项核心任务,因为它可以支持各种下游的应用程序(自动为照片加标签,为视障人士提供帮助等),并已成为机器学习(ML)算法的标准任务。
在过去的十年中,深度学习(DL)算法已成为最具竞争力的图像识别算法。但是,它们默认是“黑匣子”算法,也就是说很难解释为什么它们会做出特定的预测。
为什么这会成为一个问题呢?这是因为ML模型的使用者通常出于以下原因而希望能够解释图像的哪些部分导致了算法的预测结果:
1.机器学习调试模型,开发人员可以分析解释识别偏差和预测模型是否可能推广到新的图像
2. 机器学习模型的用户可能会更加信任一个模型,如果提供了为什么做出特定预测的解释的话。
3. 关于ML的法规(例如GDPR)要求一些算法决策可以用人类的语言来解释。
在以上因素的推动下,在过去的十年中,研究人员开发了许多不同的方法来打开深度学习的“黑匣子”,旨在使基础模型更具可解释性。有些方法对于某些种类的算法是特定的,而有些则是通用的。有些是快的,有些是慢的。
在本文中,我们概述了一些为图像识别而发明的解释方法,讨论了它们之间的权衡,并提供了一些示例和代码,您可以自己使用Gradio来尝试这些方法。
留一法 LEAVE-ONE-OUT
在深入研究之前,让我们从一个适用于任何类型图像分类的非常基本的算法开始:留一法(LOO)。
LOO是一种易于理解的方法。如果您要从头开始设计一种解释方法的话,那么这是您可能会想到的第一个算法。其想法是首先将输入图像分割为一系列较小的子区域。然后,运行一系列预测,每次遮罩(即将像素值设置为零)其中一个子区域。根据每个区域的“蒙版”相对于原始图像影响预测的程度,为每个区域分配一个重要度分数。直观地来说,这些分数量化了哪一部分的区域最有助于进行预测。
因此,如果我们在一个3x3的网格中将图像分成9个子区域,则LOO如下所示:
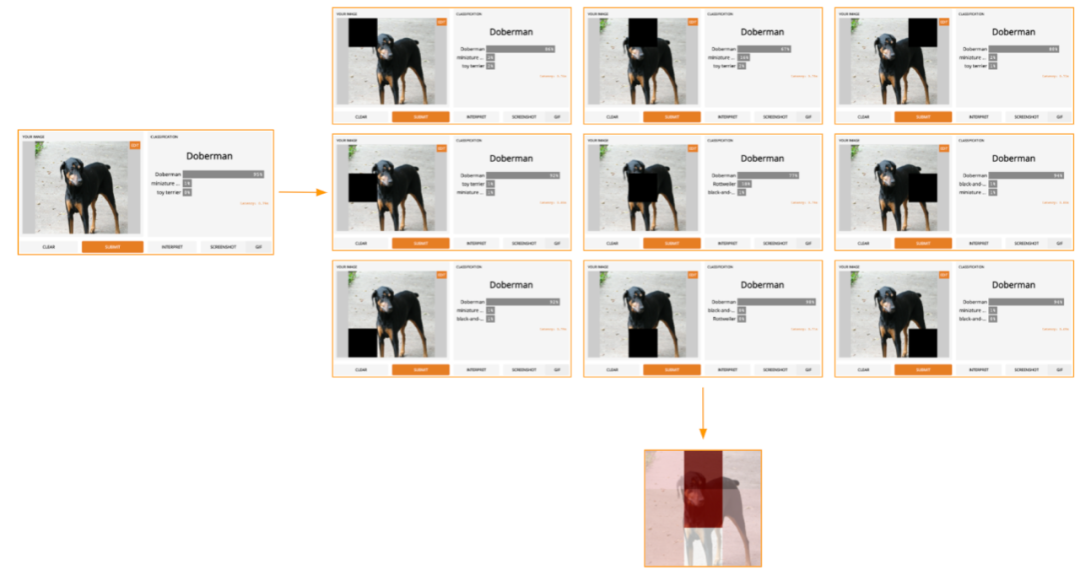
那些最暗的红色方块是影响输出最大的方块,而颜色最亮的方块对输出的影响最小。在这种情况下,当顶部中心区域被遮罩时,预测置信度下降幅度最大,从初始的95%下降到67%。
如果我们以更好的方式进行分割(例如,使用超像素而不是网格),我们将获得一个相当合理的显著图,该图突出了杜宾犬的脸,耳朵和尾巴。
LOO是一种简单而强大的方法。根据图像分辨率和分割方式,它可以产生非常准确和有用的结果。正如使用InceptionNet预测的那样,下面这张图就是LOO应用于1100 × 825像素的金毛寻回犬图像。
在实践中,LOO的一个巨大优势是它不需要任何访问模型内部的功能,甚至可以处理除识别之外的其他计算机视觉任务,从而使它成为一个灵活的通用工具。
那有什么缺点呢?首先,它很慢。每次一个区域被遮罩,我们就对图像进行推断。要获得一个具有合理分辨率的显著图,您的遮罩尺寸可能必须很小。因此,如果您将图像分割成100个区域,则将需要100倍的推理时间才能获得热度图。另一方面,如果您有太多的子区域,则对它们中的任何一个区域进行遮罩不一定会在预测中产生很大的差异。此LOO的第二个限制是,它没有考虑到区域之间的相互依赖性。
因此,让我们来看一个更快,更复杂的技术:梯度上升。
梯度上升 VANILLA GRADIENT ASECENT [2013]
梯度上升这一方法的提出,可以追溯到2013年发表的一篇名为Visualizing Image Classification Models and Saliency Maps [2013]的论文中找到。LOO和梯度上升这两个方法之间存在着概念上的关系。使用LOO时,我们考虑到当我们逐个遮盖图像中的每个区域时,输出是如何变化的。通过梯度上升,我们可以一次计算出每单个像素对输出的影响。我们如何做到这一点的呢?答案是使用反向传播的改进版本。
通过使用标准的反向传播,我们可以计算出模型损失相对于权值的梯度。梯度是一个包含每个权重值的向量,反映了该权重的微小变化将对输出产生了多大的影响,并从本质上告诉我们哪些权重对于损失最重要。通过取该梯度的负值,我们可以将训练过程中的损失降到最低。对于梯度上升,取而代之的是类分数相对于输入像素的梯度,并告诉我们哪些输入像素对图像分类最重要。通过网络的这一单个步骤为我们提供了每个像素的重要性值,我们以热图的形式显示该值,如下所示:
Simonyan等人用单一反向传播过程计算出显著性图示例
这是我们的杜宾犬的图像:
这里的主要优势是——速度;因为我们只需要通过网络一次可以得到热图,所以梯度上升的方法比LOO快得多,尽管最终得到的热图有点粗糙。
在杜宾犬的图像上,LOO(左)与梯度上升(右)方法进行了比较。这里的模型是InceptionNet。
尽管梯度上升是十分可行的,但人们发现这种被称为Vanilla梯度上升的原始公式有一个明显的缺点:它传播负梯度,最终会导致干扰和噪声的输出。为解决这些问题,我们提出了一种新方法——“引导反向传播”。
引导反向传播 guided back-propogation [2014]
引导式反向传播一开始是发表在了Striving for Simplicity: The All Convolutional Net [2014]上,其中,作者提出在反向传播的常规步骤中增加一个来自更高层的额外引导信号。从本质上讲,当输出为负时,该方法就会阻止来自神经元的梯度反向流动,仅保留那些导致输出增加的梯度,从而最终减少噪声。
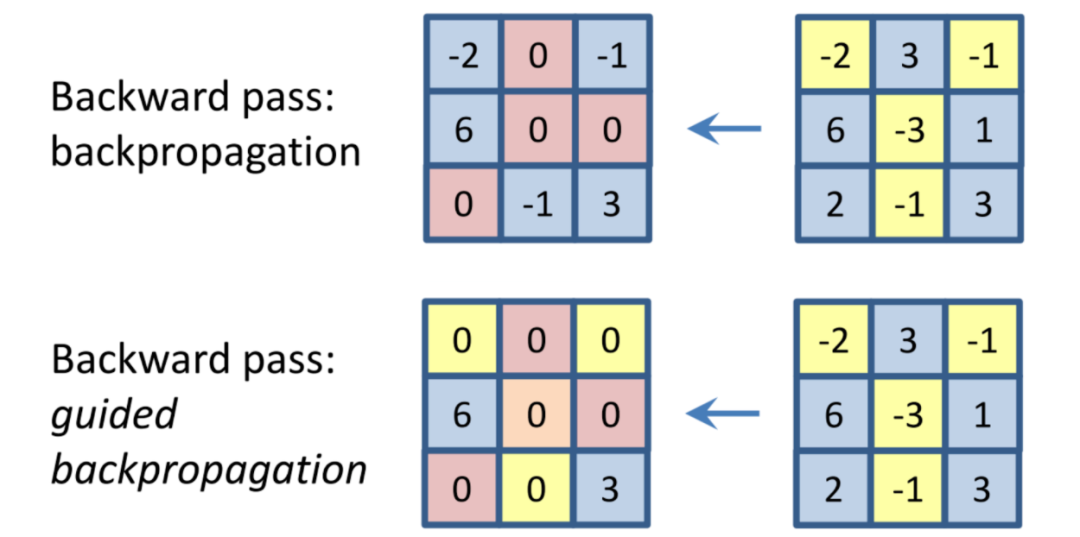
在此图像中,我们显示了一个给定图层的反向传播梯度(左),其输出显示在右侧。在顶层,我们展示了整齐的梯度。在底层,我们展示了引导反向传播,每当输出为负时,它将零梯度化。(图来自Springenberg等人)
引导式反向传播的工作速度几乎与梯度上升一样快,因为它只需要通过网络一次,但通常会产生更清晰的输出,尤其是在物体边缘附近。该方法相对于没有最大池化层的神经体系结构中的其他方法来说特别有效。
在杜宾犬的图像上,梯度上升(左)与“引导式反向传播”(右)进行了比较。这里的模型是InceptionNet。
但是,人们发现,梯度上升和引导式反向传播仍然存在一个主要问题:当图像中存在两个或更多类别时,它们通常无法正常工作,这通常发生在自然图像中。
梯度类别响应图 grad-cam [2016]
现在来到了Grad-CAM,或者梯度加权类别激活映射,该方法在: Visual Explanations from Deep Networks via Gradient-based Localization [2016]文章中有着相关的介绍。在这里,作者发现,当在最后一个卷基层的每个滤波器处而不是在类分数上(但仍相对于输入像素)提取梯度时,其解释的质量得到了改善。为了得到特定于类的解释,Grad-CAM对这些梯度进行加权平均,其权重基于过滤器对类分数的贡献。结果如下所示,这远远好于单独的引导反向传播。
具有两个类别(“猫”和“狗”)的原始图像使用了引导反向传播的方式,但是生成的热量图突出显示了这两个类。一旦将Grad-CAM用作过滤器,引导式Grad-CAM便会生成高分辨率,区分类别的热图。(图片来自Selvaraju等人)
作者进一步推广了Grad-CAM,使其不仅适用于目标类,而且适用于任何目标“概念”。这意味着可以使用Grad-CAM来解释为什么图像字幕模型可以预测特定的字幕,甚至可以处理多个输入的模型,例如可视化问答模型。由于这种灵活性,Grad-CAM已变得非常流行。以下是其架构的概述。
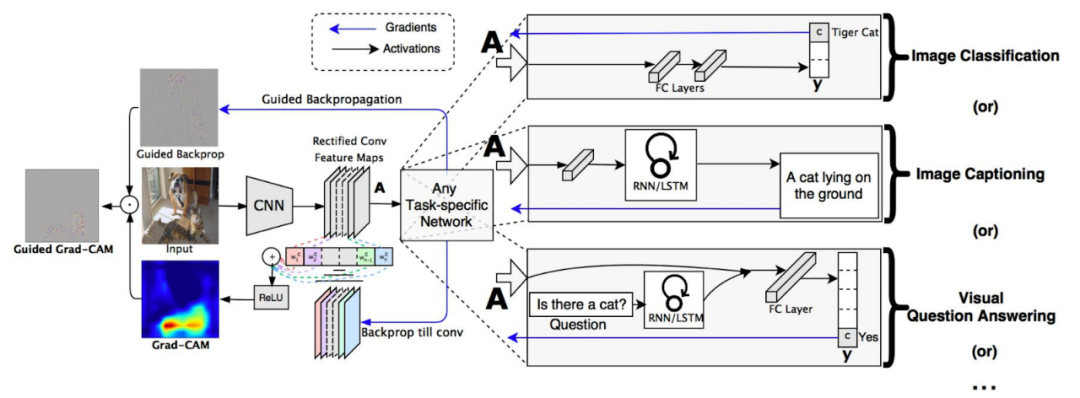
Grad-CAM概述:首先,我们向前传播图像。对于除所需类别(tiger cat)之外的所有类别梯度设置为0,其余设置为1。然后将该信号反向传播到所关注的整流卷积特征图,我们结合这些特征图来计算粗糙Grad-CAM定位(蓝色热图),它表示模型在做出特定决策时必须寻找的位置。最后,我们将热图与引导反向传播逐点相乘,得到高分辨率和概念特定的Guided Grad-CAM可视化。(图片和描述来自Selvaraju等人)
平滑梯度 smoothgrad [2017]
然而,您可能已经注意到,就算使用所有先前所介绍的方法,结果仍然不是很清晰。SmoothGrad, presented in SmoothGrad: removing noise by adding noise [2017], 这篇文章是对先前方法的修改版本。这个想法很简单:作者指出,如果输入图像首先受到噪声干扰,则可以为每个版本的干扰输入计算一次梯度,然后将灵敏度图平均化。尽管运行时间更长,但这会得到更清晰的结果。
以下是引导式反向传播和平滑梯度图像的对比:
杜宾犬图像上的标准制引导反向传播(左)与平滑梯度(右)。这里的模型是InceptionNet。
当您面对所有的方法时,会选择哪一种?或者,当方法之间发生冲突时,是否有一种方法在理论上可以证明比其他方法更好?让我们看一下集成梯度的方法。
集成梯度 integrated gradients [2017]
与此前的论文不同,Axiomatic Attribution for Deep Networks [2017]的作者从解释的理论基础开始。他们专注于两个公理:灵敏度和实现不变性,为此,他们提出了一个好的解释方法应该满足这两项。
灵敏度公理意味着,如果两个图像的有一个像素恰好不同(但所有其他像素都相同),并且产生不同的预测,则解释算法应为该不同像素提供非零的属性。而实现不变性公理意味着算法的底层实现不应影响解释方法的结果。他们使用这些原则来指导一种新的归因方法的设计,该归因方法称为“集成梯度(IG)”。
IG从基线图像(通常是输入图像的完全变暗的版本)开始,并增加亮度,直到恢复原始图像为止。针对每幅图像计算类别分数相对于输入像素的梯度,并对其进行平均以获得每个像素的全局重要性值。IG除了理论特性外,还解决了普通梯度上升的另一个问题:饱和梯度。由于梯度是局部的,因此它们不能捕获像素的全局重要性,而只能捕获特定输入点的灵敏度。通过改变图像的亮度并计算不同点的梯度,IG可以获得更完整的图片,包含了每个像素的重要性。
在杜宾犬图像上的标准引导反向传播(左)与集成梯度(右),均使用了平滑梯度进行了平滑处理。这里的模型是InceptionNet。
尽管这通常可以产生更准确的灵敏度图,但是该方法速度较慢,并且引入了两个新的附加超参数:基线图像的选择以及生成集成梯度的步骤数。那么,我们可以不用这些么?
模糊集成梯度 blur integratedgradients [2020]
这就是我们最终的解释方法,即模糊集成梯度。该方法在Attribution in Scale and Space [2020],中提出,旨在解决具有集成梯度的特定问题,包括消除“基线”参数,并消除某些易于在解释中出现的视觉伪像。
模糊集成梯度方法通过测量一系列原始输入图像逐渐模糊的版本梯度(而不是像集成梯度那样变暗的图像)。尽管这看起来似乎是微小的差异,但作者认为这种选择在理论上更为合理,因为模糊图像不会像选择基线图像那样在解释中引入新的伪影。
杜宾犬图像上的标准集成梯度(左)与模糊集成梯度(右),均使用平滑梯度进行了平滑。这里的模型是InceptionNet。
写在最后
从2010年开始到现在,是机器学习在解释方法方面硕果累累的十年,并且现在有大量用于解释神经网络行为的方法。我们已经在本篇文章中对它们进行了比较,我们非常感谢几个很棒的图书馆,尤其是Gradio,来创建您在GIF和PAIR代码的TensorFlow实现中看到的接口。用于所有接口的模型都是Inception Net图像分类器。
原文标题:图像识别解释方法的视觉演变
文章出处:【微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
图像识别
+关注
关注
9文章
519浏览量
38239 -
机器学习
+关注
关注
66文章
8377浏览量
132409 -
深度学习
+关注
关注
73文章
5492浏览量
120977
原文标题:图像识别解释方法的视觉演变
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI图像识别摄像机






 工商网监
工商网监
评论