 神经网络中词向量是怎么表示的?
神经网络中词向量是怎么表示的?
上一篇我们讲到了在神经网络出现以前的词向量表示方法:基于同义词词典的方法和基于计数统计的方法。想要回顾的可以看这里小白跟学系列之手把手搭建NLP经典模型-2(含代码)
这一篇我们要真正开始讲在神经网络中,词向量是怎么表示的,以及它又有什么优缺点呢?
目录
基于统计存在的问题
什么是推理?
神经网络中输入的单词怎么处理?
简单的word2vec
CBOW模型的推理
CBOW模型的学习
学习数据的准备
CBOW模型的实现
从概率角度看CBOW
总结
基于计数统计存在的问题
在海量数据的今天,基于计数统计的方法难以处理大规模的语料库,因为统计需要一次性统计整个语料库!实在是有点难顶。而SVD降维的复杂度又太大,于是将推出——基于推理的方法,也就是基于神经网络的方法。
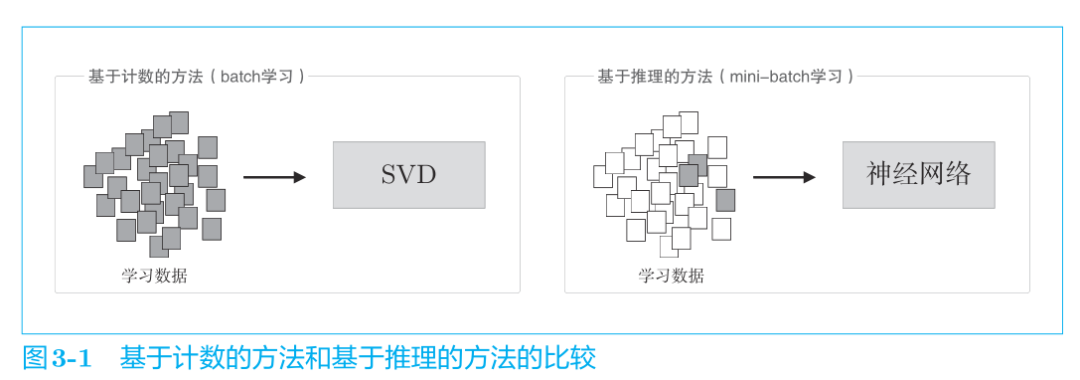
神经网络一次只需要处理一个mini-batch的数据进行学习,并且反复更新网络权重,使神经网络能够正确预测结果。
基于推理的方法以预测为目标,同时获得了作为副产品的单词分布式表示。也就是说,模型学习的最终目的是能够预测正确的结果,而在学习的过程中,我们意外的获得了单词的分布式表示。
如果看不懂也没有关系,这里只是摆出了最终的结论,接着往下看。
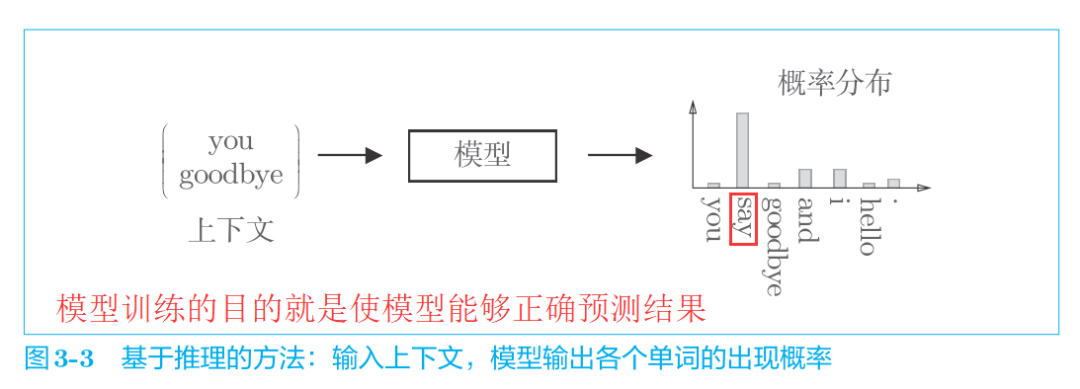
什么是推理?
当给出周围的单词(上下文)时,预测"?"处会出现什么单词。

也就是说,基于推理的方法和基于计数的方法一样,也是基于分布式假设的,即“单词含义由其周围的单词构成”。
输入单词的处理方法
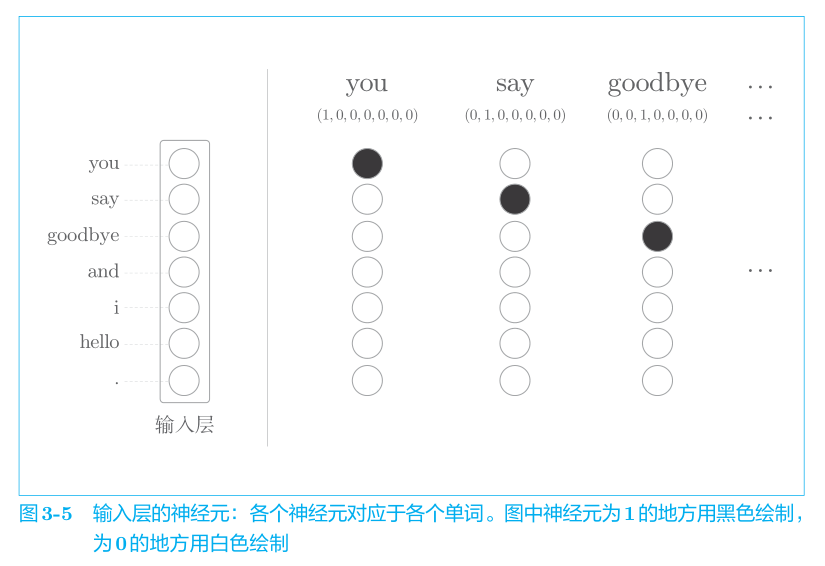
将输入文本写为one-hot向量
和之前的方法一样,不管什么模型都无法直接输入文本本身,模型只“看得懂”数字,因此我们需要先将单词转化为固定长度的向量。对此,一种方式是将单词转换为 one-hot向量。在 one-hot 表示中,只有一个元素是 1,其他元素都是 0。还是以“You say goodbye and I say hello.”这一语料作为例子,表示成one-hot向量即如下所示:

像这样,将单词转化为固定长度的向量,神经网络的输入层的神经元个数也就可以固定下来(图 3-5)。
能用向量表示单词啦,这样我们就可以把它们丢进神经网络进行处理了。比如,对于one-hot表示的某个单词,
使用全连接层的神经网络如图 3-6 所示。
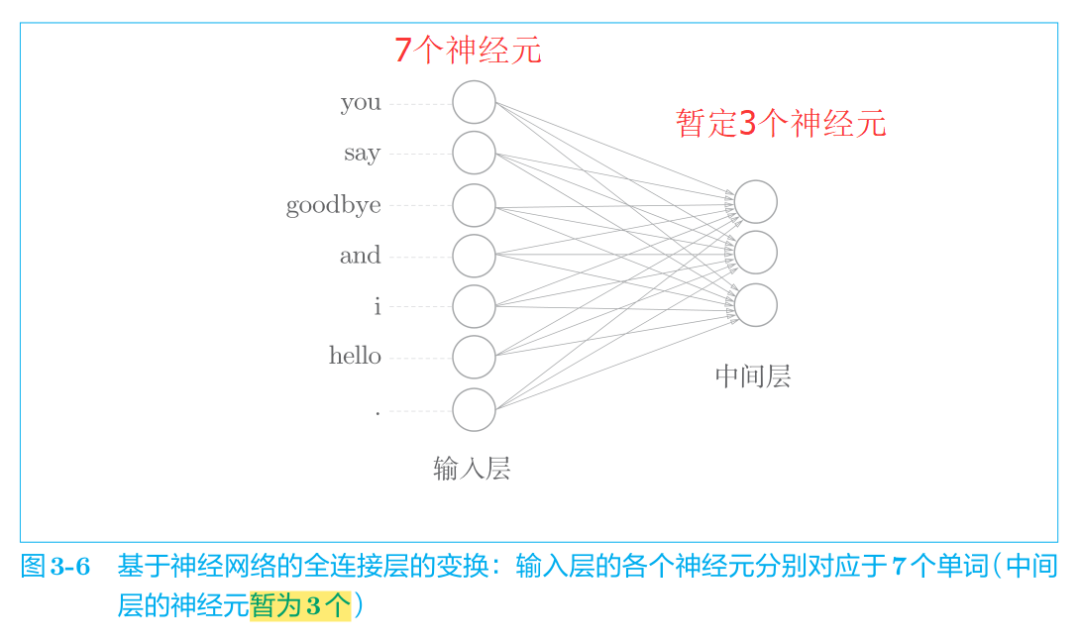
但是我们需要关注权重W的大小,因此我们将神经网络画成如下的形式:
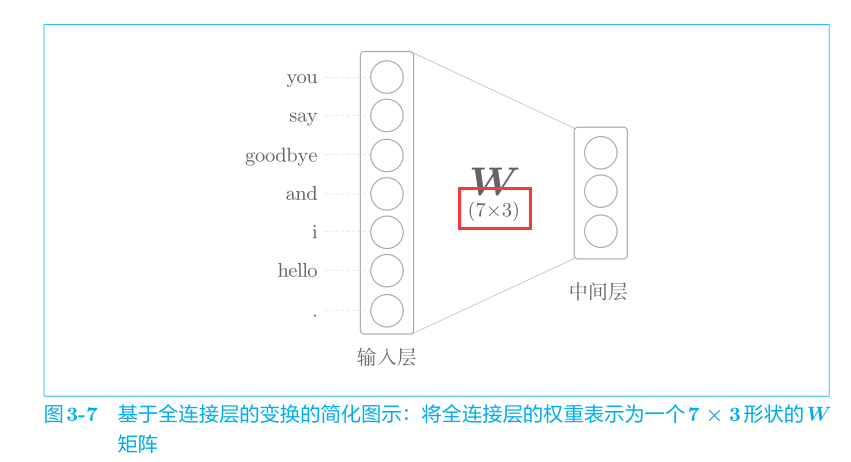
全连接层变换可以写成如下的 Python代码。
import numpy as np c = np.array([[1, 0, 0, 0, 0, 0, 0]]) # 输入youW = np.random.randn(7, 3) # 权重初始值为7行3列的矩阵随机数,且具有标准正态分布h = np.dot(c, W) # 中间隐藏层节点print(h)# [[-0.70012195 0.25204755 -0.79774592]]
这里需要注意的是因为输入 c 是 one-hot 表示,单词 ID 对应的元素是 1,其他地方都是 0。因此,上述代码中的 c × W 的矩阵乘积相当于“提取”权重的对应行向量。
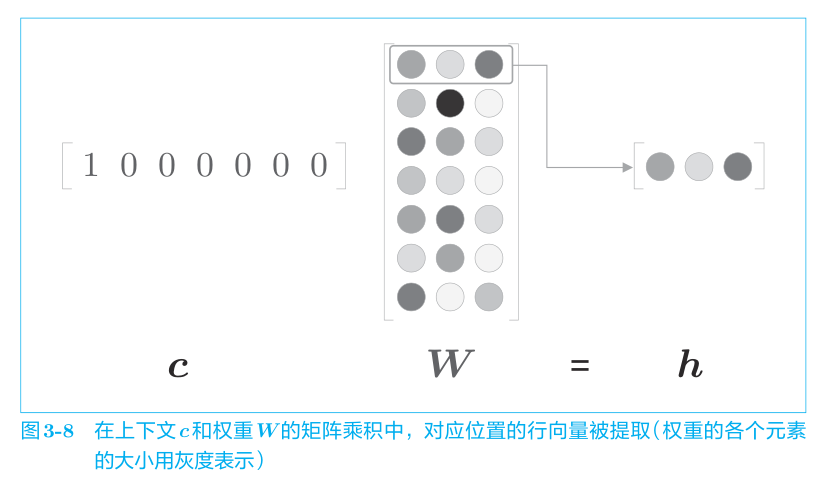
这里,仅为了提取权重的行向量而进行矩阵乘积计算好像不是很有效率。关于这一点,我们会在后续进行改进。而且乘积也可以用MatMul层(专门做矩阵乘积的层)来实现。
学习了基于推理的方法,并用代码实现了神经网络中单词的处理方法,至此准备工作就完成了,现在是时候实现word2vec了。
在基于推理(神经网络)的方法中,最著名的就是Word2Vec。接下来我们将详细的探讨word2vec的结构和如何用代码把这个结构搭建起来。
简单的word2vec
word2vec有两种模型:
CBOW模型
Skip-gram模型
两种模型的区别如下:
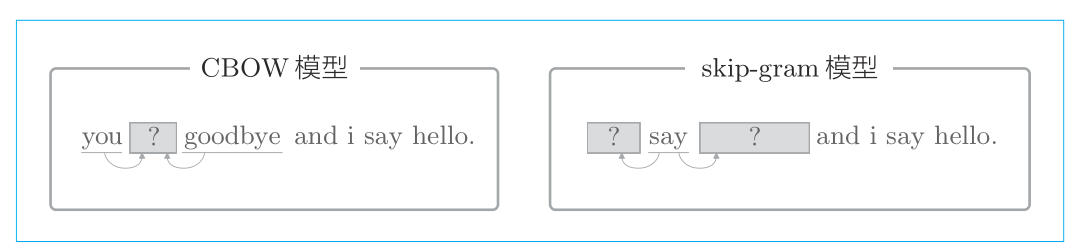
CBOW 模型是从上下文的多个单词预测中间的单词(目标词),而 skip-gram 模型则从中间的单词(目标词)预测上下文的多个单词。
本节我们将主要讨论CBOW模型。
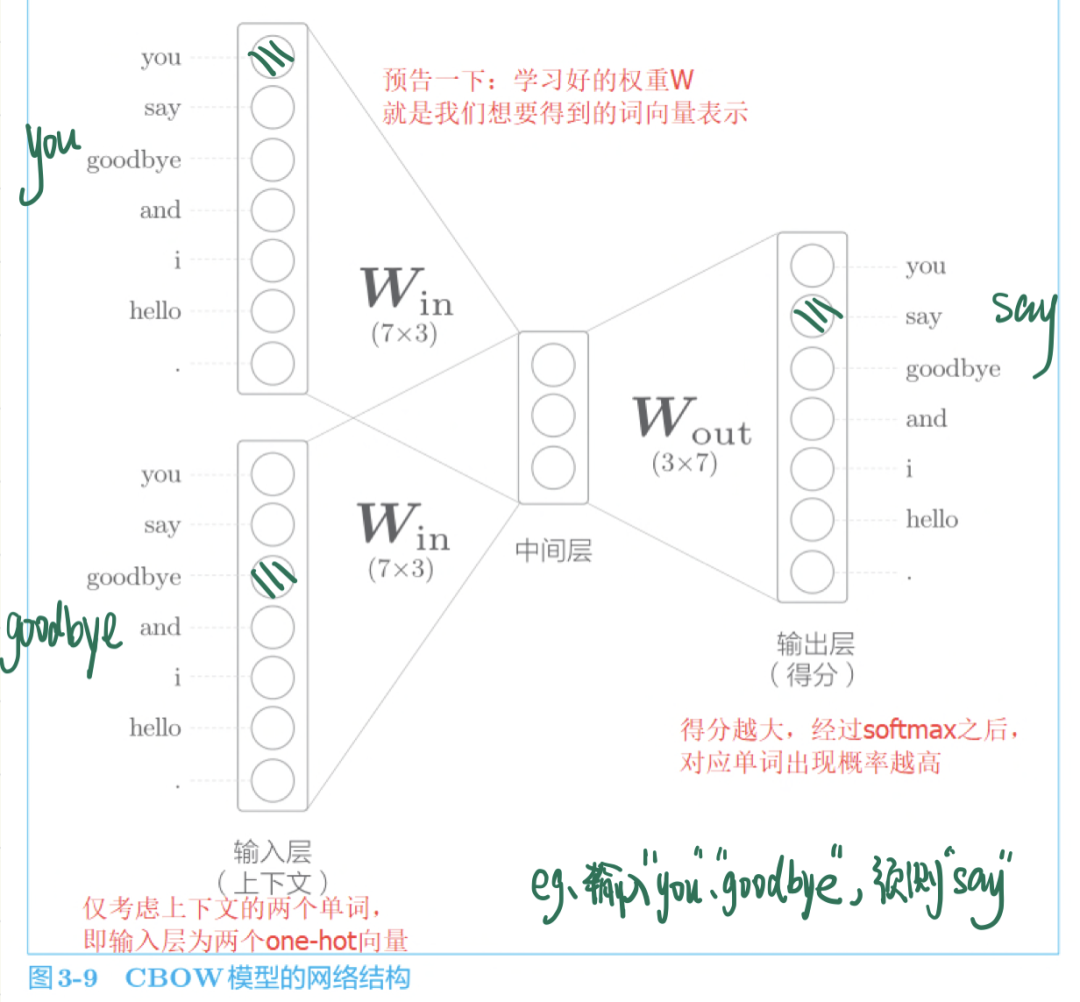
CBOW模型的推理
CBOW 模型是根据上下文预测目标词的神经网络(“目标词”是指中间的单词,它周围的单词是“上下文”)。通过训练这个 CBOW 模型,使其能尽可能地进行正确的预测目标词,我们就可以获得中间产物——单词的分布式表示。
提前剧透一下,这个学习好的、能正确预测结果的权重就是我们想要的单词分布式表示。
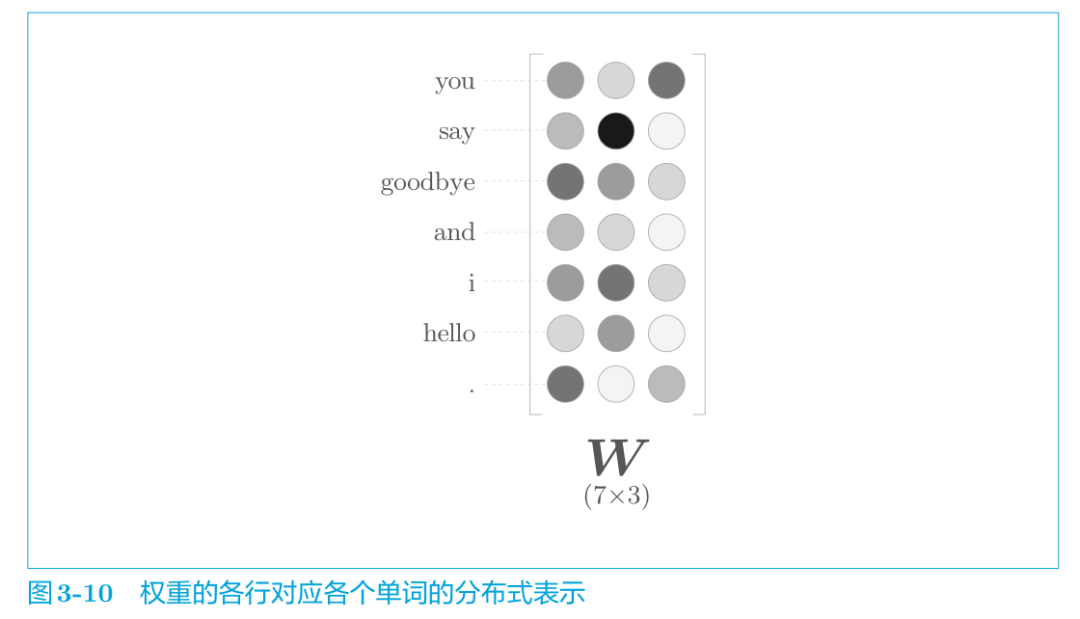
中间层的神经元数量比输入层少这一点很重要。中间层需要将预测单词所需的信息压缩保存,从而产生密集的向量表示。这时,中间层被写入了我们人类无法解读的代码,相当于 “编码” 工作。而从中间层的信息获得期望结果的过程则称为 “解码” 。这一过程将被编码的信息复原为我们可以理解的形式。
我们从层的角度来看看这个CBOW模型:
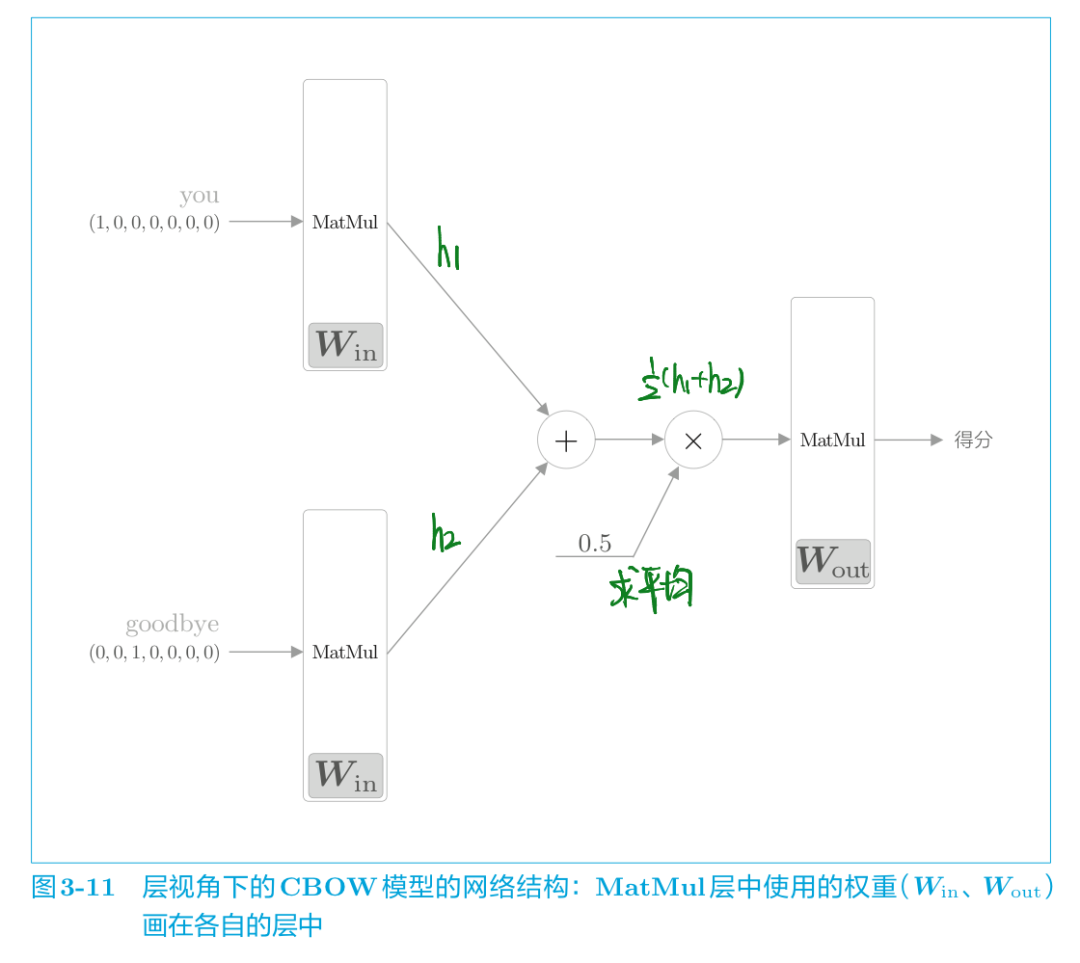
如图 3-11 所示,CBOW 模型一开始有两个 MatMul 层,这两个层的输出被加在一起。然后,对这个相加后得到的值乘以 0.5 求平均,可以得到中间层的神经元。最后,将另一个 MatMul 层应用于中间层的神经元,输出得分。
MatMul 层的正向传播,在内部会计算矩阵乘积。
接下来用代码实现 CBOW 模型的推理(即求得分的过程) ,具体实现如下所示( ch03/cbow_predict.py ) 。
import syssys.path.append('..')import numpy as npfrom common.layers import MatMul # 样本的上下文数据c0 = np.array([[1, 0, 0, 0, 0, 0, 0]]) # youc1 = np.array([[0, 0, 1, 0, 0, 0, 0]]) # goodbye # 权重的初始值W_in = np.random.randn(7, 3)W_out = np.random.randn(3, 7) # 生成层in_layer0 = MatMul(W_in)in_layer1 = MatMul(W_in)out_layer = MatMul(W_out) # 正向传播h0 = in_layer0.forward(c0)h1 = in_layer1.forward(c1)h = 0.5 * (h0 + h1)s = out_layer.forward(h)print(s) # [[ 0.30916255 0.45060817 -0.77308656 0.22054131 0.15037278# -0.93659277 -0.59612048]]
输出侧的MatMul层共享权重W_in。
以上是没有使用激活函数的简单网络结构,接下来看看CBOW模型的学习(也就是添加激活函数后得到概率)。
CBOW模型的学习
推理完了得到得分,加上激活函数就得到结果的概率,这个概率就表示哪个单词会出现在给定的上下文(周围单词)中间。
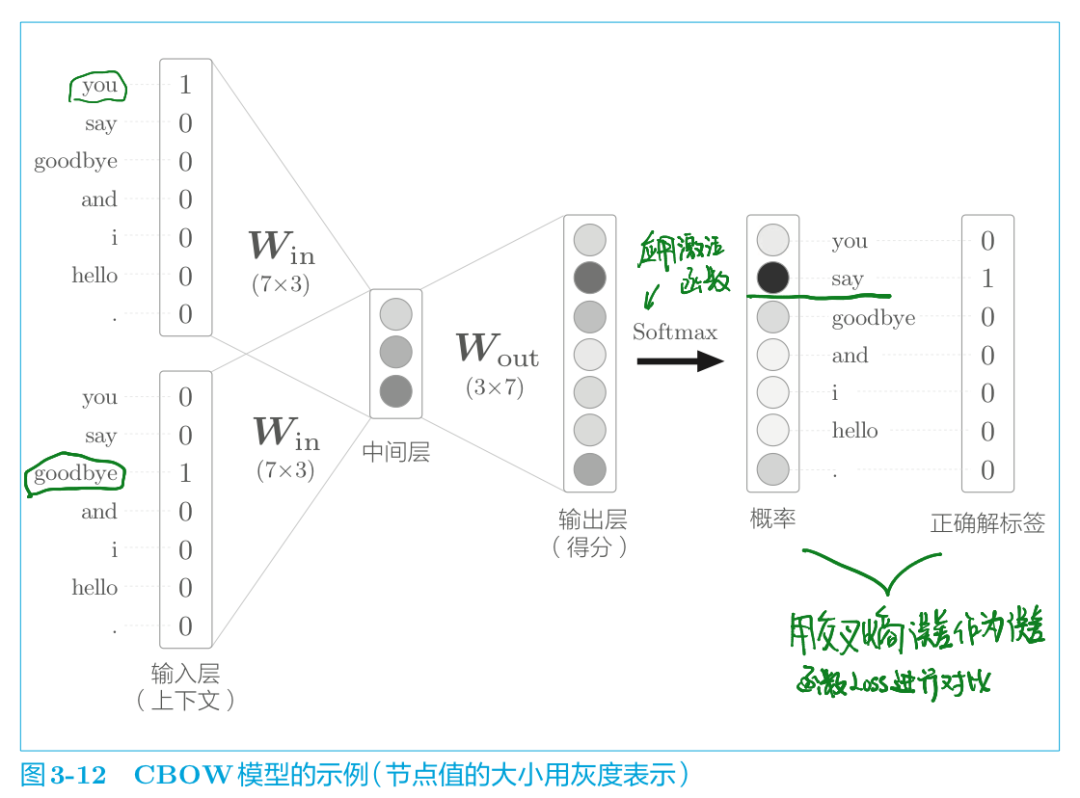
说白了,CBOW模型的学习就是调整权重参数,以使预测结果更加准确。评估预测是否准确的一大指标就是预测的结果和正确的结果之间进行对比,用什么指标去比对呢?用交叉熵误差量化对比模型预测的概率和正确结果之间的差距(也就是loss值),并且反馈给前面的权重参数W并进行参数W的调整,从而不断的减小与正确结果之间的距离,这就是模型训练、学习的过程。
从层的角度表示如下:
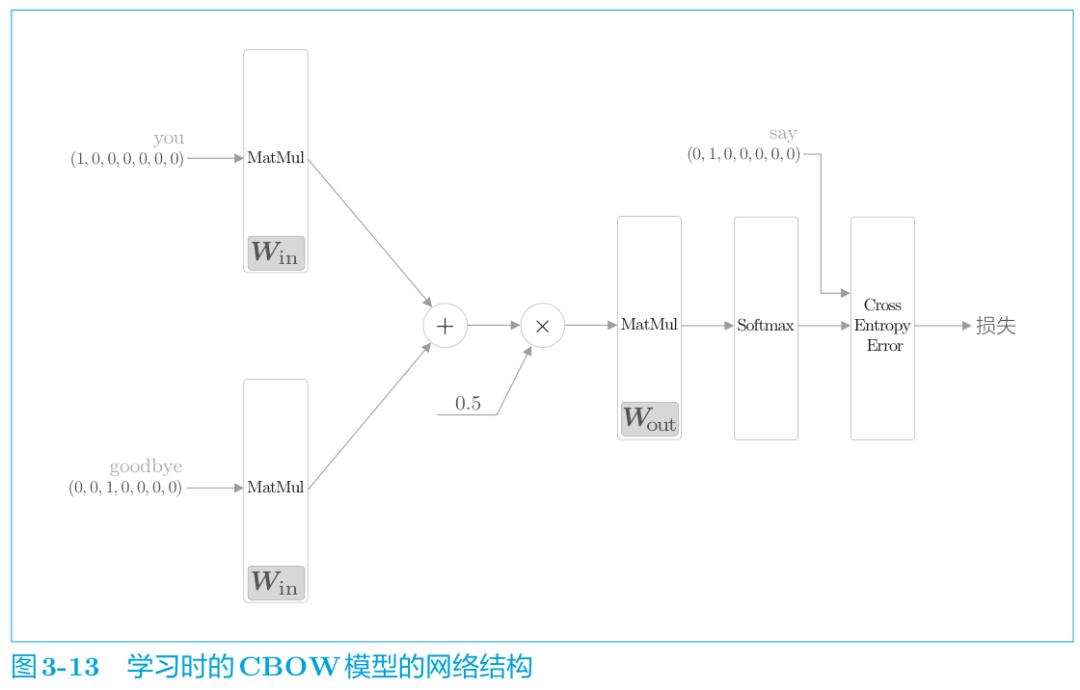
CBOW模型的学习,只需在 CBOW 模型的推理上加上Softmax 层和 Cross Entropy Error 层,就可以得到损失。这就是 CBOW模型的正向传播。
那么学习好的模型最终获得的权重参数是什么样的呢?
word2vec 中使用的网络有两个权重,分别是输入侧的权重(Win)和输出侧的权重(Wout) 。一般而言,输入侧的权重 Win 的每一行对应于各个单词的分布式表示。或者输出侧的每一列也同样对应各个单词的分布式表示。
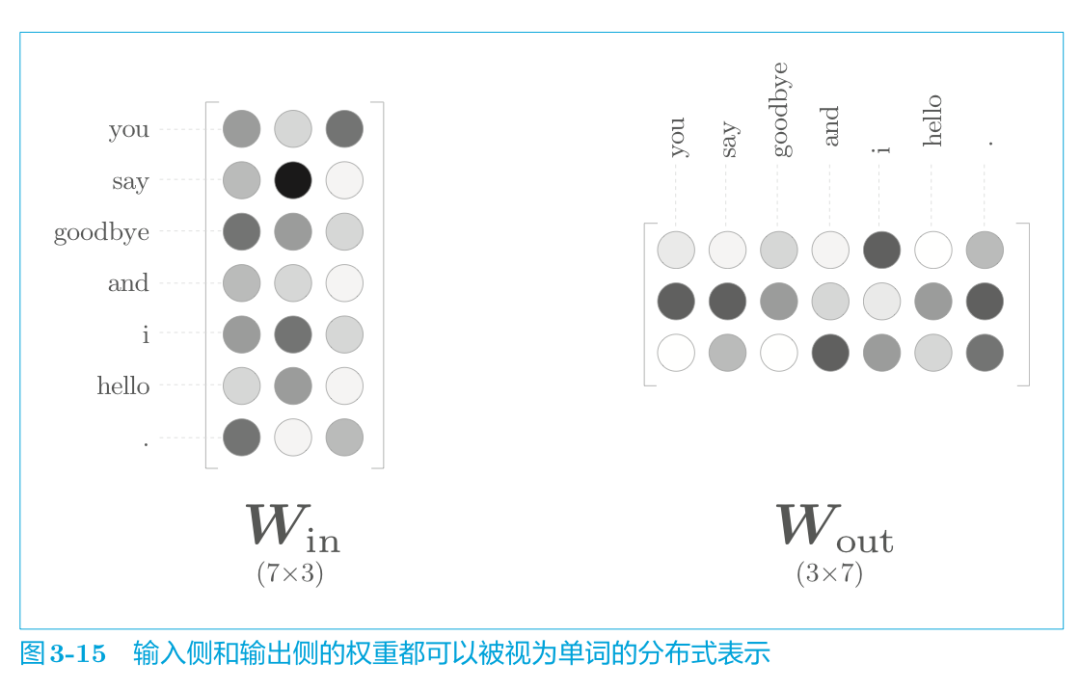
那么,我们最终应该使用哪个权重作为单词的分布式表示呢?这里有三个选项。
A. 只使用输入侧的权重
B. 只使用输出侧的权重
C. 同时使用两个权重
就 word2vec(特别是 skip-gram 模型)而言,最受欢迎的是方案 A。在这里我们也使用Win作为词向量。而在与 word2vec 相似的 GloVe[27]词向量表示方法中,使用C方案将两个权重相加,也获得了良好的结果。
模型搭建好了,我们还要对输入数据进行预处理。
学习数据的准备
我们上面有说过,模型没法直接"认识"文本,而只认识数字,所以我们首先需要将输入数据转化为one-hot向量表示。这里仍以“You say goodbye and I say hello.”为例。
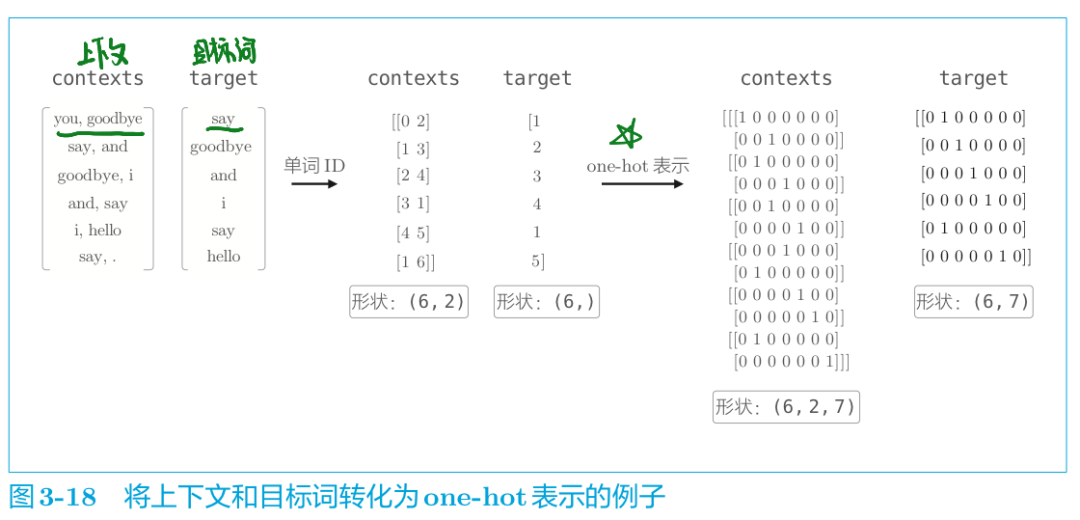
代码实现数据预处理如下:
import syssys.path.append('..')from common.util import preprocess, create_contexts_target,convert_one_hot text = 'You say goodbye and I say hello.' corpus, word_to_id, id_to_word = preprocess(text) contexts, target = create_contexts_target(corpus, window_size=1) vocab_size = len(word_to_id)target = convert_one_hot(target, vocab_size)contexts = convert_one_hot(contexts, vocab_size)
convert_one_hot() 函数实现了将单词 ID 转化为 one-hot 表示,内容很简单,代码在 common/util.py 中。
至此,学习数据的准备就完成了,下面我们来讨论最重要的 CBOW 模型的实现。
CBOW模型的实现
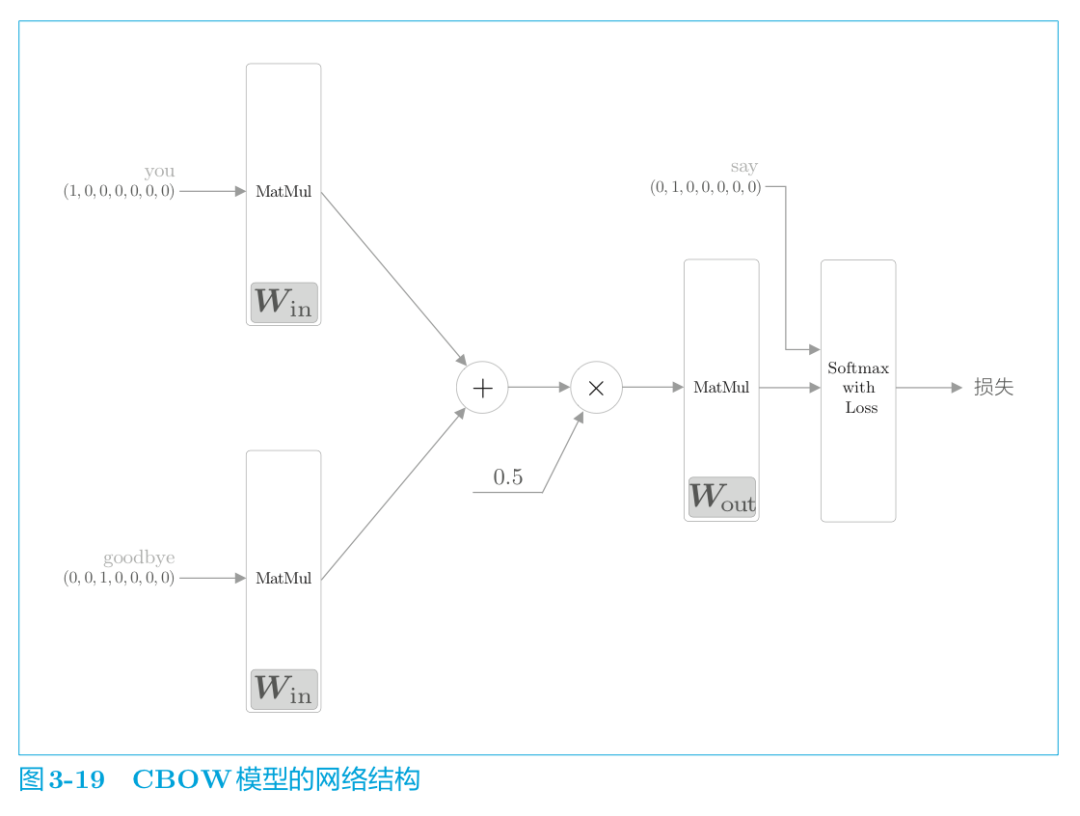
根据CBOW模型的网络结构图,将该神经网络实现为 SimpleCBOW 类(下一节将对其进行改进为 CBOW 类) 。首先,让我们看一下 SimpleCBOW 类的初始化方法( ch03/simple_cbow.py ) 。
模型的初始化代码
import syssys.path.append('..')import numpy as npfrom common.layers import MatMul, SoftmaxWithLoss class SimpleCBOW: def __init__(self, vocab_size, hidden_size): # 词汇数:vocab_size ;中间层神经元个数:hidden_size V, H = vocab_size, hidden_size # 初始化权重,用一些小的随机值初始化 W_in = 0.01 * np.random.randn(V, H).astype('f') W_out = 0.01 * np.random.randn(H, V).astype('f') # 生成层 self.in_layer0 = MatMul(W_in) self.in_layer1 = MatMul(W_in) self.out_layer = MatMul(W_out) self.loss_layer = SoftmaxWithLoss() # 将所有的权重和梯度整理到列表中 layers = [self.in_layer0, self.in_layer1, self.out_layer] self.params, self.grads = [], [] for layer in layers: self.params += layer.params self.grads += layer.grads # 将单词的分布式表示设置为成员变量 self.word_vecs = W_in
指定 NumPy 数组的数据类型为 astype('f'),初始化将使用 32 位的浮点数。
实现神经网络的正向传播 forward() 函数代码。该函数接收参数 contexts 和 target,并返回损失(loss)。
def forward(self, contexts, target): # 接收参数 contexts 和 target,并返回损失(loss) h0 = self.in_layer0.forward(contexts[:, 0]) h1 = self.in_layer1.forward(contexts[:, 1]) h = (h0 + h1) * 0.5 score = self.out_layer.forward(h) loss = self.loss_layer.forward(score, target) return loss
这里,假定参数 contexts 是一个三维 NumPy 数组,即图3-18 的例子中 (6,2,7) 的形状,其中第 0 维是 mini-batch 的数量,第 1 维是上下文的窗口大小,第 2 维表示 one-hot 向量。此外, target 是 (6,7)这样的二维形状。
实现反向传播 backward()
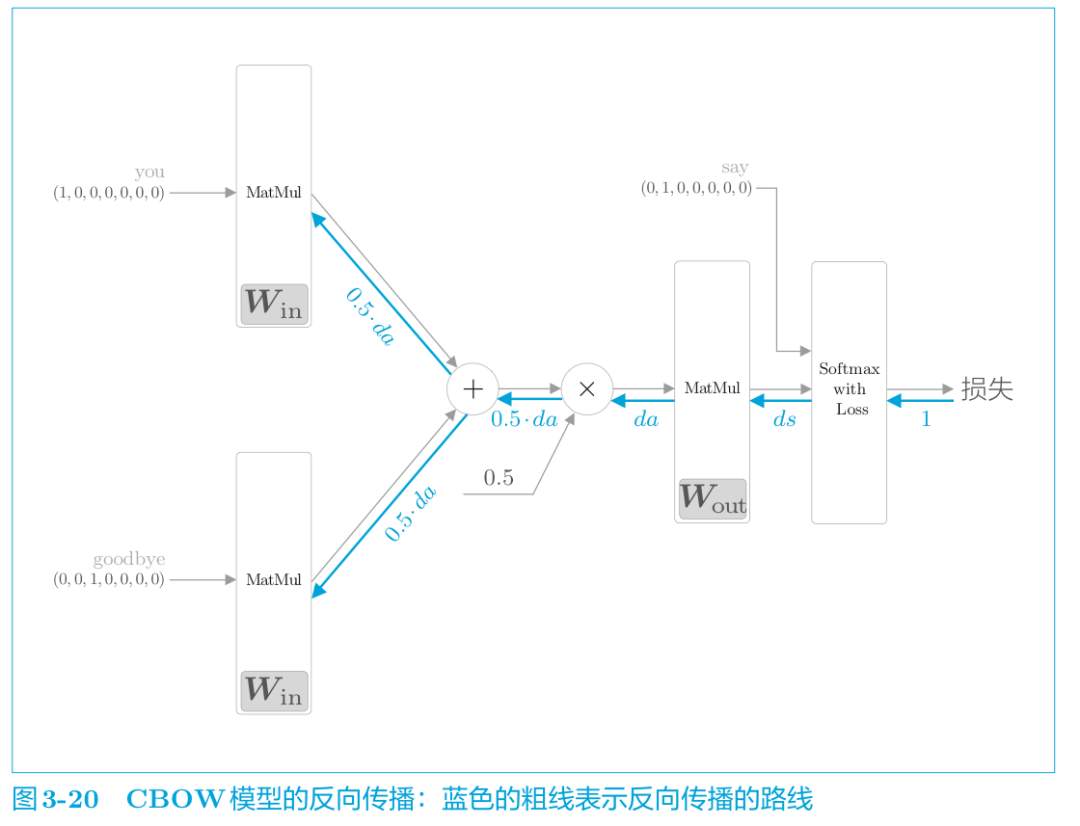
反向传播代码如下:
def backward(self, dout=1): ds = self.loss_layer.backward(dout) da = self.out_layer.backward(ds) da *= 0.5 self.in_layer1.backward(da) self.in_layer0.backward(da) return None
“×”的反向传播将正向传播时的输入值“交换”后乘以梯度。“+”的反向传播则将梯度“原样”传播。
此处正向、反向传播已实现,通过先调用 forward() 函 数, 再调用 backward() 函数,grads 列表中的梯度被更新。
模型学习的实现
CBOW 模型的学习和一般的神经网络的学习完全相同。
首先,给神经网络准备好学习数据。
然后,求梯度,并逐步更新权重参数。
这里,我们使用神经网络中的 Trainer 类来执行学习过程,学习的源代码如下所示( ch03/train.py ) 。
模型学习的实现代码:
import syssys.path.append('..')from common.trainer import Trainerfrom common.optimizer import Adamfrom simple_cbow import SimpleCBOWfrom common.util import preprocess, create_contexts_target,convert_one_hot window_size = 1hidden_size = 5batch_size = 3max_epoch = 1000 text = 'You say goodbye and I say hello.'corpus, word_to_id, id_to_word = preprocess(text) vocab_size = len(word_to_id)contexts, target = create_contexts_target(corpus, window_size)target = convert_one_hot(target, vocab_size)contexts = convert_one_hot(contexts, vocab_size) model = SimpleCBOW(vocab_size, hidden_size)optimizer = Adam()trainer = Trainer(model, optimizer)trainer.fit(contexts, target, max_epoch, batch_size)trainer.plot()
之后,我们都会使用Train类进行网络的学习。使用 Trainer类, 可以理清容易变复杂的学习代码。
结果如图所示:
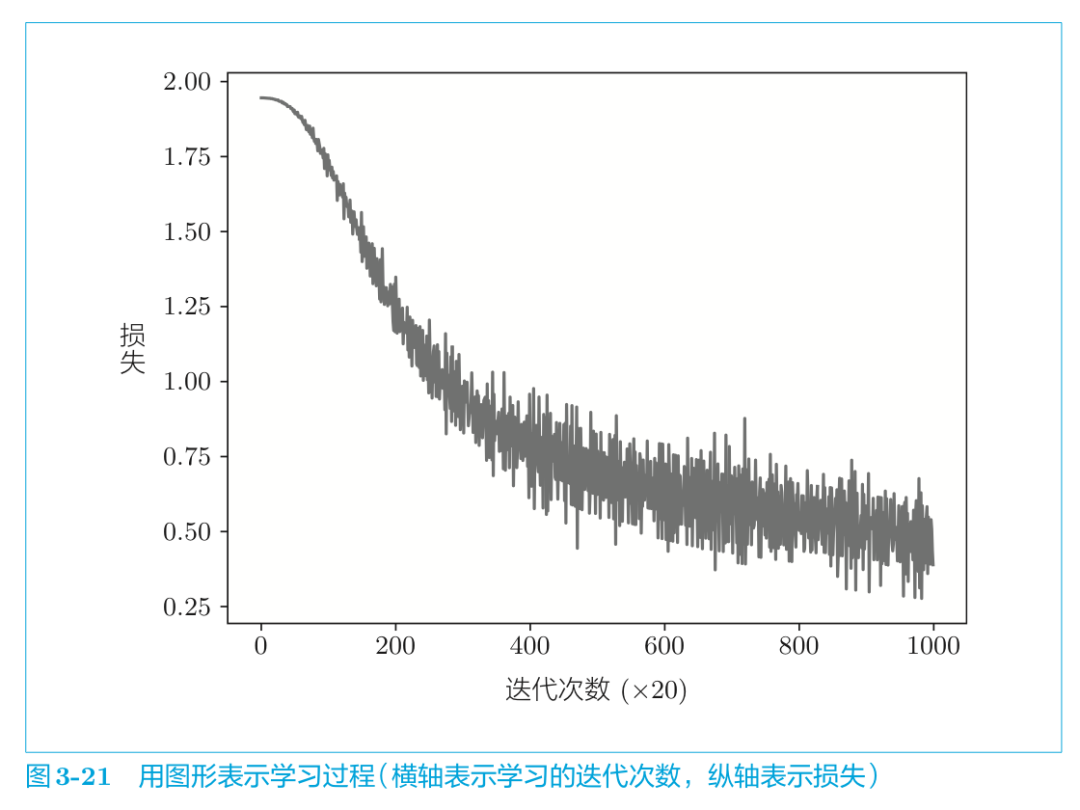
通过不断的学习,损失的确在减小!我们再来看看学习结束后的权重W。我们取出刚刚保存的输入侧的权重。
word_vecs = model.word_vecs for word_id, word in id_to_word.items(): print(word, word_vecs[word_id])
word_vecs 的各行保存了对应的单词 ID 的分布式表示。结果如下所示:
you [-0.9031807 -1.0374491 -1.4682057 -1.3216232 0.93127245]say [ 1.2172916 1.2620505 -0.07845993 0.07709391 -1.2389531 ]goodbye [-1.0834033 -0.8826921 -0.33428606 -0.5720131 1.0488235 ]and [ 1.0244362 1.0160093 -1.6284224 -1.6400533 -1.0564581]i [-1.0642933 -0.9162385 -0.31357735 -0.5730831 1.041875 ]hello [-0.9018145 -1.035476 -1.4629668 -1.3058501 0.9280102]. [ 1.0985303 1.1642815 1.4365371 1.3974973 -1.0714306]
我们终于将单词表示为了密集向量!这就是单词的分布式表示。
不过,由于这里使用的语料库因为太小了所以并没有给出很好的结果。如果换成更大的语料库,相信会获得更好的结果。但是,如果语料库太大,在处理速度方面又会出现新的问题,因为当前这个 CBOW 模型的实现在处理效率方面存在几个问题。下一节我们将改进这个简单的 CBOW 模型,实现一个“真正的”、更快的CBOW 模型。
从概率角度看CBOW
我们从概率角度再来看一下CBOW模型。首先说明几个概率的表示方法。
由概率统计所学,我们知道:
P(A):表示A发生的概率;
P(A,B):表示A,B同时发生的概率;(联合概率)
P(A|B):B发生时A发生的概率。(后验概率)
已知CBOW模型的原理是已知上下文而预测目标词。

我们用数学式来表示当给定上下文 wt−1和 wt+1时目标词为 wt 的概率。即使用后验概率,有式 (3.1):

式 (3.1) 表示“在 wt−1和 wt+1发生后,wt发生的概率” 。也就是说,CBOW 模型可以建模为式 (3.1)。
而且使用式 (3.1)可以简洁地表示CBOW 模型的损失函数。
将原交叉熵误差函数式以概率的形式来表示就是:
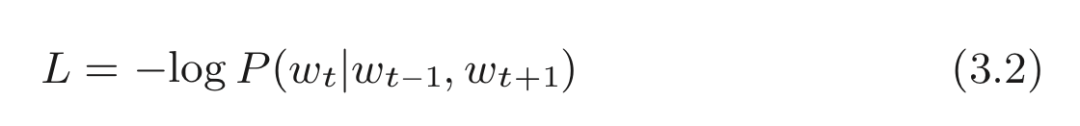
CBOW 模型的损失函数只是对式 (3.1) 的概率取 log,并加上负号,这也称为负对数似然(negative log likelihood) 。式 (3.2) 是一笔样本数据的损失函数。如果将其扩展到整个语料库,则损失函数可以写为:
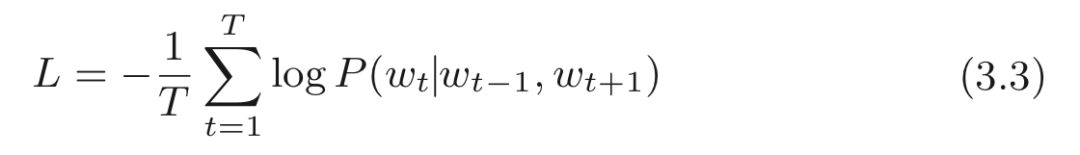
CBOW 模型学习的任务就是让式 (3.3) 表示的损失函数尽可能地小。学习好的权重参数就是我们想要的单词的分布式表示。这里,我们只考虑了窗口大小为 1 的情况,不过其他的窗口大小(或者窗口大小为 m 的一般情况) 也很容易用数学式表示。
理解了 CBOW 模型的实现,在实现 skip-gram 模型时也就不存在什么难点了。这里就不再介绍 skip-gram 模型的实现。详细代码可以参考 ch03/simple_skip_gram.py 。
总结
到目前为止,我们已经了解了基于计数的方法和基于神经网络的方法(特别是 word2vec) 。基于计数的方法通过对整个语料库的统计数据进行一次学习来获得单词的分布式表示,而基于推理的方法则通过反复观察语料库的一部分数据进行学习(mini-batch 学习) 。
如果需要向词汇表添加新词汇并更新词向量。
基于计数的方法:需要从头开始计算,重新生成共现矩阵、进行SVD降维等操作。
而基于神经网络的方法:允许参数的增量学习。可以将之前学习好的权重参数作为初始值继续学习更新权重参数。
但是现阶段的CBOW模型在学习效率上还存在一些问题。下一节我们将改进这个CBOW模型,使其更加高效的学习词向量表示。
原文标题:师妹问我:如何在7分钟内彻底搞懂word2vec?
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4762浏览量
100522 -
机器学习
+关注
关注
66文章
8375浏览量
132397 -
nlp
+关注
关注
1文章
487浏览量
22006
原文标题:师妹问我:如何在7分钟内彻底搞懂word2vec?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络与传统神经网络的比较
递归神经网络和循环神经网络的模型结构





 工商网监
工商网监
评论