 AMD Instinct MI200计算卡首曝:用上MCM多芯封装
AMD Instinct MI200计算卡首曝:用上MCM多芯封装
去年11月份,AMD发布了顶级加速计算卡Instinct MI100,首次采用针对HPC高性能计算、AI人工智能全新设计的CDNA架构,和游戏向的RDNA架构截然不同。现在,第二代的MI200也首次浮出了水面。
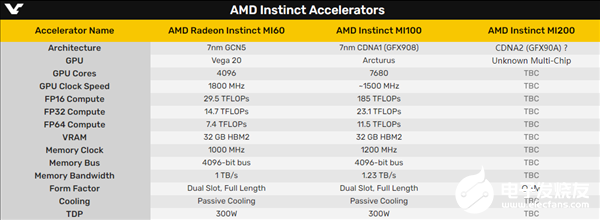
MI100采用台积电7nm工艺制造,集成120个计算单元、7680个流处理器,并专门加入Matrix Core(矩阵核心)用于加速HPC、AI运算,还整合了4096-bit 32GB HBM2显存,支持PCIe 4.0 x16和八卡并行,整卡功耗300W。
它的FP64双精度浮点性能首次突破10TFlops(也就是每秒1亿亿次),混合精度和FP16半精度的AI性能提升接近7倍。
根据最新消息,MI200将会采用下一代CNDA架构,并首次引入MCM多芯片封装,看这样子翻番到1.5万个流处理器问题不大。
本次曝光的MI200将用于HPE Cray EX超级计算机,执行加速计算,产品名被描述为“MCM Special FIO Accelerator”,其中FIO代表“Factory Installation Option”(厂商安装选项),此外还有OAM形态,代表开源加速卡。
不过,MI200的具体规格目前一无所知,除了猜测流处理器可能因为MCM封装而翻一番,还有望加入FullRate640ps指令集、支持全速率FP64浮点计算。

MI200预计今年晚些时候发布,未来将搭配代号“Trento”(特伦托)的霄龙处理器,共同用于AMD为美国国防部打造的百亿亿次超级计算机“Frontier”。
Trento并未出现在AMD霄龙演进路线图上,其实是即将发布的第三代“Milan”(米兰)的定制版,专为超算优化,可能会提前支持PCIe 5.0。
责任编辑:PSY
-
芯片
+关注
关注
455文章
50714浏览量
423138 -
amd
+关注
关注
25文章
5466浏览量
134087 -
计算卡
+关注
关注
0文章
14浏览量
3152
发布评论请先 登录
相关推荐
AMD最强AI芯片,性能强过英伟达H200,但市场仍不买账,生态是最大短板?

《CST Studio Suite 2024 GPU加速计算指南》
IBM与AMD携手部署MI300X加速器,强化AI与HPC能力
IBM与AMD携手将在IBM云上部署AMD Instinct MI300X加速器
AMD发布新版Instinct MI325X
AMD发布新一代AI芯片MI325X
三星首度引入AMD MI300X,缓解AI GPU短缺
AMD发布全新AI芯片Instinct MI325X
AMD发布AI芯片MI325X 预计2024年第四季度上市
人工智能市场风向转变,AMD Instinct MI300X GPU更受欢迎
AMD Instinct MI300新版将采用HBM3e内存,竞争英伟达B100
AMD首批Instinct MI300X已开始交付
AMD Instinct MI300X已向LaminiAI批量供货
英伟达、AMD AI芯片今年将生产150万颗,先进封装设备商受惠
AMD Instinct MI300A获得德国订单






 工商网监
工商网监
评论