 谷歌深度学习如何处理人类语言?
谷歌深度学习如何处理人类语言?

具有语言能力的深度学习系统已经广泛应用于人们的生活当中。其中一些系统使用了 Google 发布的特定深度学习模型 —— 多语言 BERT(Multilingual BERT,简称 mBERT)。mBERT 模型可以同时接受大约 100 种语言的训练,这种多语言的训练使模型可以完成各种语言任务,例如,将文本内容从一种语言翻译成另一种语言。
虽然已经发现 mBERT 模型在许多语言任务中表现良好,但是
人们对 mBERT 模型 “如何创建文本并如何做出预测” 的相关信息并不清楚。
为此,来自斯坦福大学、加州大学欧文分校和加州大学圣巴巴拉分校的研究人员联合开展了一项新的研究,研究目的是为了更好地理解基于 mBERT 模型的技术是如何运行的,以及它是如何创建语法特征的。
相关研究结果以 “Deep Subjecthood: Higher-Order Grammatical Features in Multilingual BERT” 为题,已发表在论文预印本网站 arXiv 上。该论文为这些常用模型的基础以及它们在完成各种任务时如何分析语言提供了宝贵的线索。
神秘莫测的 mBERT 模型
在过去的几十年中,研究人员开发了基于深度神经网络的模型,它们可以完成各种各样的任务。其中一些技术专门设计用于处理和生成多种语言的连贯文本、翻译文本,并可以回答有关文本的问题,以及创建新闻文章或其他在线内容的摘要。
比较典型的代表是 Siri、Alexa、Bixby、Google Assistant 和 Cortana 等应用程序,这些程序为实时翻译、分析文本提供了极大的便利。
而这些应用程序大部分采用了 Google 发布的 mBERT 模型,用户可以使用多种语言(比如英语、西班牙语、法语、巴斯克语和印尼语等)与基于 mBERT 的系统进行交互。
虽然像 mBERT 这样的模型非常强大,但是与经过预先训练的深度学习模型不同,它们实际上包含的信息并不明显,甚至对它们的创造者来说也是如此。
这是由于这些模型是经过训练的,而不是经过编程得到的。因此,探究 mBERT 模型的工作原理,成为了许多使用者关心的问题 。理解 mBERT 模型如何对语言进行编码与尝试理解人类如何处理语言并没有太大不同。
此次研究的主要目的是,确定 mBERT 矢量模型是否包含关于人类语言及其结构的一些更深层次的信息。更具体地说,他们想确定这些模型,是否能够自动地揭示几十年来语言学研究已经确定的概括,这些概括信息对语言分析来讲是十分有用的。
致力于理解 mBERT 模型
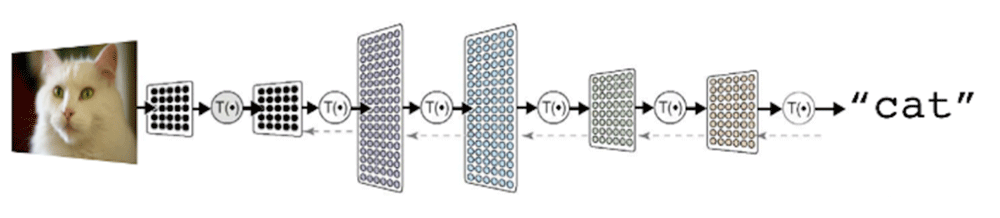
本质上,mBERT 模型将文本表示为一系列矢量,每个矢量包含数千个数字。每个矢量都对应一个单词,而单词之间的关系则被编码为高维空间的几何关系。
加州大学圣巴巴拉分校的语言学家、指导这项研究的高级研究员之一 Kyle Mahowald 表示:“由于这些模型在处理人类语言方面做得很好,因此我们知道这些数字向量一定代表了语言知识。但是它们是如何编码这些信息的,这与人类大脑中知识的表达方式有什么相似之处?我们的工作是努力理解语言的深层神经模型表示和使用语言信息的方式的一部分。”
加州大学欧文分校的语言科学家、该项目的另一位高级顾问 Richard Futrell 说:“这是研究计算语言学特别令人兴奋的时刻。多年来,语言学家一直在谈论诸如‘语义空间(semantic space)’之类的概念,认为单词和短语的意义是某个空间中的点,但这都显得有点模糊和印象主义。如今,这些理论已经变得非常精确:我们实际上有一个模型,其中一个单词的含义是空间中的某一个点,并且这个模型确实以一种暗示其理解某些人类语言的方式表现。”
为了处理人类语言,在深入分析人类语言之后,mBERT 模型和其他基于深度学习的语言分析框架,实际上可能已经重新发现了语言学研究者在深入分析人类语言之后所设计的理论。或者,它们可能基于全新的语言理论或规则进行预测。
对此,Mahowald 和他的同事们希望进一步探索这两种可能性,因为理解这些计算技术如何对语言进行编码可能对计算机科学和语言学的研究具有重要的意义。
Futrell 说:“了解这些模型的工作原理,即它们学到了什么信息以及如何使用这些信息,不仅在科学上很有趣,而且也对于我们想要开发可以使用和信任的 AI 系统至关重要。如果我们不知道语言模型知道什么,那么我们就不能相信它会做正确的事。也就是说,我们不相信它的翻译是正确的或者它的总结是准确的,我们也不能相信它没有学到种族或性别偏见等不良信息。”
由于 mBERT 模型通常是在人类编译的数据集中进行训练的,因此它们可能会发现一些人类在处理与语言相关的问题时常犯的一些错误。这项由多学科团队进行的研究可能有助于发现 AI 工具在分析语言时所犯的一些错误和其他错误。
识别不同语言的主语和宾语
为了更加深入地理解 mBERT 模型,研究人员着手研究 mBERT 模型如何代表不同语言中主语和宾语之间的差异。
Mahowald 说:“当在 mBERT 中输入一个句子时,每个单词都会得到一个矢量表示。我们建立了一个新模型,这个模型比 mBERT 要小得多,然后我们问:如果我们从 mBERT 得到一个单词矢量,这个模型能告诉我们它是一个主语还是宾语吗?也就是说,该模型能否告诉我们,‘狗’这个字用法是不是句子的主语,就像‘狗追猫’中那样,或句子的宾语,如‘猫追狗’。”
人们可能会假设所有语言都描述了主语和宾语的关系,并且它们以相似的方式表示。但是,在不同的语言中,主语和宾语的构成实际上存在巨大的差异。
该论文的作者之一、斯坦福大学计算机科学专业的研究生 Isabel Papadimitriou 和她的同事们试图利用这些差异来更好地理解 mBERT 模型是如何处理句子。
Papadimitriou 说:“如果人们使用英语,那么‘狗追猫’中的‘狗’字似乎与‘狗跑了’中的‘狗’字扮演相同的成分。在第一种情况下,动词有宾语‘猫’,在第二种情况下,它没有宾语。但在两种情况下,‘狗’是主语、主体、行为者,而在第一句中,‘猫’是宾语,是正在做的事情。但是,并非所有语言都如此。”
图 | 研究过程说明
英语和欧洲人所说的大多数语言,都有一种被称为主格对齐的结构,这种结构清楚地描述了句子中的主语和宾语。
但是,包括巴斯克语,北印度语和格鲁吉亚语在内的语言,使用的是一种代名词对齐。在代名词对齐中,在没有宾语的句子中,主语在某种意义上被视为宾语,因为它遵循用于宾语的语法结构。例如,句子 “狗在奔跑” 中的 “狗” 字某种程度上即是主语也是宾语。
Papadimitriou 说:“我们工作的主要目标是测试 mBERT 是否理解这种对齐、代名词或主语的概念。换句话说,我们问:mBERT 能否深入理解动词的主语和宾语是什么构成的,以及不同的语言如何将空间分割成主语和宾语?事实证明,同时接受大约 100 种语言培训的 mBERT 会以有趣的语言方式意识到这些区别。”
机器可以理解人类语言
这些发现为 mBERT 模型以及其他用于语言分析的计算模型如何表示语法信息提供了新的有趣见解。有趣的是,研究人员研究的基于 mBERT 向量表示的检验模型也发现会产生一致的错误,这些错误可能与处理语言的人类所犯的错误一致。
Papadimitriou 说:“在不同的语言中,当一个主语是一个无生命的名词时,我们的模型更有可能错误地将该主体称为主语,这意味着该名词不是人类或动物。这是因为句子中的大多数行为者往往是有生命的名词:人类或动物。实际上,一些语言学家认为主观性实际上是一个范围。与人类相比,作为人类的受试者比作为动物的受试者更‘主观’,作为动物的受试者比既不是人类也不是动物的受试者更‘主观’,这正是我们在 mBERT 模型中发现的。”
总体而言,研究表明 mBERT 模型可以识别句子中的主语和宾语,并以与现有语言学文献一致的方式表示两者之间的关系。
在未来,这一重要发现可以帮助计算机科学家更好地理解深度学习技术是如何处理人类语言的,从而帮助他们进一步提高性能。
Mahowald 表示:“我们现在希望继续探索语言的深层神经模型,在它们的连续向量空间中表示语言类别(如主语和宾语)的方式。具体来说,我们认为语言学的工作可以告诉我们如何看待这些模型以及它们在做什么,语言学的工作试图将主语和宾语等角色描述为一组特征,而不是离散的类别。”
参考资料:https://arxiv.org/abs/2101.11043v1
责编AJX
-
谷歌
+关注
关注
27文章
6264浏览量
112155 -
模型
+关注
关注
1文章
3861浏览量
52322 -
深度学习
+关注
关注
73文章
5613浏览量
124723
发布评论请先 登录
深度学习为什么还是无法处理边缘场景?

stm32cubeide 编译报错如何处理?


大语言模型如何处理上下文窗口中的输入

如何深度学习机器视觉的应用场景
Stduio使用wifi模块出错如何处理?

深度学习对工业物联网有哪些帮助
静力水准仪在测量过程中遇到误差如何处理?

自动驾驶中Transformer大模型会取代深度学习吗?

当深度学习遇上嵌入式资源困境,特征空间如何破局?
深度操作系统deepin 25全面支持凹语言



评论