 智源联合清华发布首个支持PyTorch框架的高性能MoE系统
智源联合清华发布首个支持PyTorch框架的高性能MoE系统
北京智源人工智能研究院(以下简称“智源研究院”)和清华大学联合发布首个支持 PyTorch 框架的高性能 MoE 系统:FastMoE 。
FastMoE 系统具有易用性强、灵活性好、训练速度快的优势,打破行业限制,可在不同规模的计算机或集群上支持研究者探索不同的 MoE 模型在不同领域的应用。相比直接使用 PyTorch 实现的版本,提速 47 倍。FastMoE 是智源研究院于 2020 年发起的新型超大规模预训练模型研发项目“悟道”的最新成果,由“悟道文汇”(面向认知的超大规模新型预训练模型)和“悟道文溯”(超大规模蛋白质序列预训练模型)两个研究小组联合完成。
MoE 是什么?万亿模型的核心技术,推动预训练模型跨越式发展,却令 GPU 与 PyTorch 用户望而却步。
MoE(Mixture of Experts)是一个在神经网络中引入若干专家网络(Expert Network)的技术,也是 Google 最近发布的 1.5 万亿参数预训练模型 Switch Transformer 的核心技术。它对于预训练模型经从亿级参数到万亿级参数的跨越,起了重要推动作用。然而由于其对 Google 分布式训练框架 mesh-tensorflow 和 Google 定制硬件 TPU 的依赖,给学术界和开源社区的使用与研究带来了不便。
MoE 设计:显著增加模型参数量
在 ICLR 2017 上,Google 研究者提出了 MoE(Mixture of Experts)层。该层包含一个门网络(Gating Network)和 n 个专家网络(Expert Network)。对于每一个输入,动态地由门网络选择 k 个专家网络进行激活。在图 1 的例子中,门网络决定激活第 2 个专家网络和第 n-1 个专家网络。
图 1:MoE 层的设计(图片来源 https://arxiv.org/pdf/1701.06538.pdfFigure 1)
在具体设计中,每个输入 x 激活的专家网络数量 k 往往是一个非常小的数字。比如在 MoE 论文的一些实验中,作者采用了 n=512,k=2 的设定,也就是每次只会从 512 个专家网络中挑选两个来激活。在模型运算量(FLOPs)基本不变的情况下,可以显著增加模型的参数量。
GShard 和 Switch Transformer,达到惊人的 1.5 万亿参数量级
在 ICLR 2021 上,Google 的进一步将 MoE 应用到了基于 Transformer 的神经机器翻译的任务上。GShard 将 Transformer 中的 Feedforward Network(FFN)层替换成了 MoE 层,并且将 MoE 层和数据并行巧妙地结合起来。在数据并行训练时,模型在训练集群中已经被复制了若干份。GShard 通过将每路数据并行的 FFN 看成 MoE 中的一个专家来实现 MoE 层,这样的设计通过在多路数据并行中引入 All-to-All 通信来实现 MoE 的功能。在论文中,Google 使用 2048 个 TPU v3 cores 花 4 天时间训练了一个 6 千亿参数的模型。
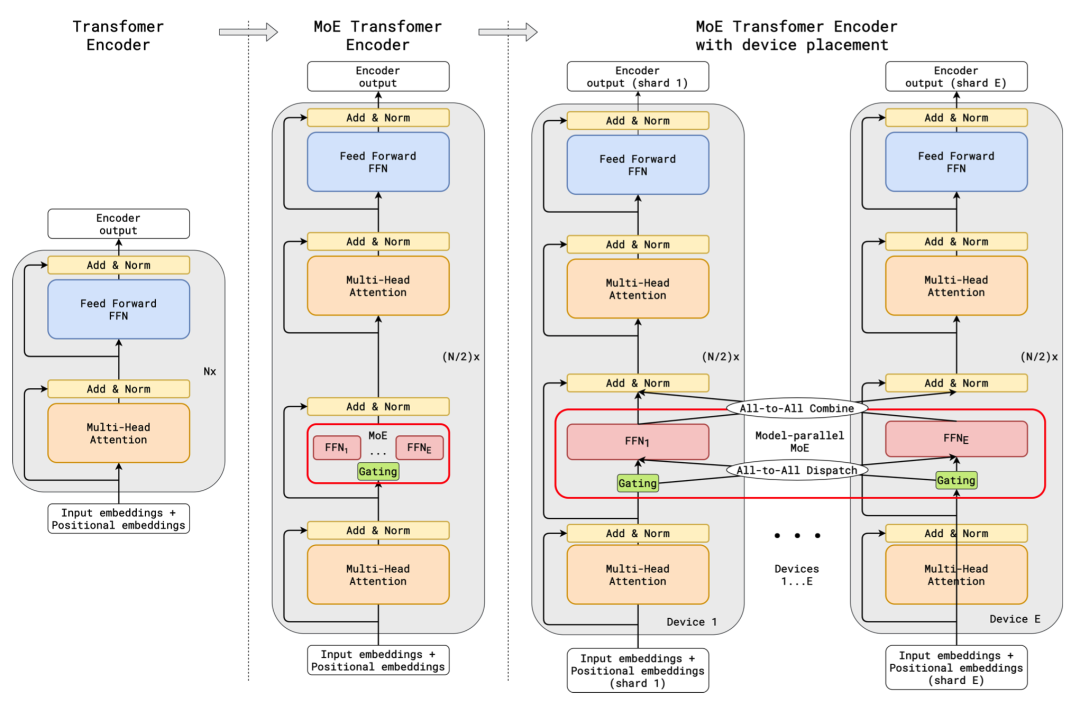
图 2:GShard 的设计(图片来源 https://arxiv.org/pdf/2006.16668.pdfFigure 3)
在 2021 年 1 月,Google 进一步发布了万亿规模的基于 MoE 的大规模预训练模型 Switch Transformer。Switch Transformer 用 MoE 改进了 Google 已有的 T5 预训练模型,其中最大的模型 Switch-C 已经达到了 1.5 万亿参数。
MMoE:MoE 的推荐系统应用
除了在自然语言处理中大放异彩之外,MoE 还在推荐系统中找到了一席之地。在 KDD 2018 中,Google 的研究人员提出了 MMoE(Multi-gate Mixture-of-Experts),并将其应用到了 Google 的推荐系统的多任务分类问题中,取得了十分好的效果。随后,Google 在 RecSys 2019 介绍了 MMoE 在 YouTube 视频推荐中的应用。类似的 MMoE 模型也被快手的研究员应用到了快手推荐系统的 1.9 万亿参数的大规模精排模型中。
FastMoE 是首个支持 PyTorch 框架的 MoE 系统,简单,灵活,高性能,支持大规模并行训练
MoE 潜力巨大,但因为绑定 Google 软硬件,无法直接应用于 PyTorch 框架。FastMoE 是首个基于当前最流行的 PyTorch 框架的 MoE 开源系统,使得普通的用户可以使用常见的 GPU 资源来尝试和研究自己的 MoE 模型。与朴素版本相比,实现了 47 倍的提速优化,更加简单、灵活、高效。
特色一:简单易用,一行代码即可 MoE
FastMoE 系统既可以作为 PyTorch 网络中的一个模块使用,也可用于“改造”现有网络中某个层:将其复制多份,并引入 Gate,变为 MoE 层。
例如,对于当前流行的 Megatron-LM 训练系统,仅需要对代码进行如下改动,就可以将 Transformer 模型中的前馈网络(Feed Forward Network)全部替换为 MoE 网络。
特色二:灵活性,支持多种扩展方式
除了传统的两层 MLP 网络,FastMoE 也支持将任意神经网络模块作为专家网络,而进行这样的操作仅需通过修改 MoE 层构造函数中的一个参数即可实现。
此外,专家选择模块 Gate 也有较高的研究价值。FastMoE 系统目前仅提供了基于单层全连接网络的基础版本,但是通过给定接口,研究者可以方便地使用自己编写的深度神经网络模块作为 Gate,从而探索出更好的专家选择方案。
特色三:运行高效,专有性能优化
FastMoE 中包含了一些专门优化的 CUDA 代码。在单块 GPU 上,相对于一个朴素的 PyTorch 实现,FastMoE 的算子更加充分地利用了 GPU 大规模并行计算的能力,从而实现多达 47 倍的加速,从而使得模型研究者可以在更短的时间内验证他们的想法。
FastMoE 支持在同一个 worker 上运行多个 experts,从而减少模型研究者在探索更多 experts 数量时所需的硬件资源。当 experts 数量较多时,FastMoE 针对传统的两层 MLP 全连接网络(即 Transformer 中的 FFN 网络)使用了更精细的并行策略,从而使得 Transformer 模型中 MLP 部分的运算速度相比朴素的实现较大的加速。
图 3:单 GPU 多 experts 情况下,FastMoE 相比普通 PyTorch 实现的加速比。性能的提升主要来自 FastMoE 针对传统的两层 MLP 全连接网络(即 Transformer 中的 FFN 网络)使用了更精细的并行策略。
单 GPU 的 FastMoE 优化配合 PyTorch 的数据并行,已经可以支持少量专家的 MoE 分布式训练,这种训练模式被称为 FastMoE 的数据并行模式。图 4 展示了一个在 2 个 workers(GPU)上对一个由 3 个 experts 构成的 MoE 网络进行前向计算的例子。
图 4:FastMoE 数据并行模式,每个 worker 放置多个 experts,worker 之间数据并行。top-2 gate 指的是门网络会选择激活分数最高的 2 个专家网络。
FastMoE 的数据并行模式已经可以支持许多应用,开发者在著名的 Transformer-XL 模型上进行了实验。具体来说,Transformer-XL 模型中的每一个 FFN 层(两层的带 ReLU 激活函数的 MLP,隐层大小为 512->2048->512)都被一个 64 选 2 的专家网络替代(每个专家网络是两层的带 ReLU 激活函数的 MLP,隐层大小为 512->1024->512)。这样一来,改造后的 FastMoE-Transformer-XL 在模型计算量基本不变的情况下,可以获得原始 Transformer-XL 模型约 20 倍的参数。如图 5 所示,改造后的 FastMoE-Transformer-XL 收敛得比 Transformer-XL 更快。
图 5:FastMoE-Transformer-XL (64 个 experts)在 enwik8 数据集上前 100K 步的 Training Loss,其收敛速度显著快于 Transformer-XL。
特色四:支持大规模并行训练
图 6:FastMoE 模型并行模式,每个 worker 放置多个 experts,worker 之间进行 experts 的模型并行。top-2 gate 指的是门网络会选择激活分数最高的 2 个专家网络。
FastMoE 还支持在多个 worker 间以模型并行的方式进行扩展(如图 6 所示),即不同的 worker 上放置不同的 experts,输入数据在计算前将被传输到所需的 worker 上,计算后会被传回原来的 worker 以进行后续计算。通过这种并行方式,模型规模可以以线性扩展,从而支持研究者探索更大规模的模型。这种模式被称为 FastMoE 的模型并行模式。
值得一提的是,FastMoE 已经和英伟达开发的超大规模预训练工具 Megatron-LM 进行了深度整合,从而使研究者对现有代码做尽量小的修改即可并行运行基于 MoE 的超大规模预训练模型。开发者在 Megatron-LM 的 GPT 模型上进行了测试。如图 7 所示,类似在 Transformer-XL 上观察到的现象,一个 96 个 experts 的 GPT 模型可以收敛得比 GPT 模型更快。
图 7:FastMoE-GPT (96 个 experts)在 GPT 上前 60K 步的 Training Loss,其收敛速度显著快于 GPT。
智源研究院
新型人工智能研究机构、支持科学家勇闯 AI「无人区」
智源研究院是在科技部和北京市委市政府的指导和支持下成立的新型研发机构,旨在聚焦原始创新和核心技术,建立自由探索与目标导向相结合的科研体制,支持科学家勇闯人工智能科技前沿“无人区”。
FastMoE 团队成员来自于智源研究院和清华大学计算机系 KEG 和 PACMAN 实验室,打通了算法、系统等不同背景的学术人才,由智源研究院学术副院长 - 清华大学计算机系唐杰教授、智源青年科学家 - 清华大学计算机系翟季冬副教授、智源青年科学家 - 循环智能创始人杨植麟博士领导,团队成员有清华大学计算机系博士研究生何家傲、裘捷中以及本科生曾奥涵。
原文标题:首个支持 PyTorch 框架的 MoE 系统来了!智源联合清华开源FastMoE,万亿AI模型基石
文章出处:【微信公众号:通信信号处理研究所】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
人工智能
+关注
关注
1792文章
47385浏览量
238889 -
pytorch
+关注
关注
2文章
808浏览量
13246
原文标题:首个支持 PyTorch 框架的 MoE 系统来了!智源联合清华开源FastMoE,万亿AI模型基石
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
鸿蒙原生页面高性能解决方案上线OpenHarmony社区 助力打造高性能原生应用
PyTorch 2.5.1: Bugs修复版发布

猎户星空发布Orion-MoE 8×7B大模型及AI数据宝AirDS
字节跳动与清华AIR成立联合研究中心
澎峰科技高性能大模型推理引擎PerfXLM解析

华发数智携手字节跳动共同发布AI数字人及大模型综合解决方案
pytorch环境搭建详细步骤
tensorflow和pytorch哪个更简单?
tensorflow和pytorch哪个好
TensorFlow与PyTorch深度学习框架的比较与选择
清华大学联合中交兴路发布《中国公路货运大数据碳排放报告》

Fedora 40发布,全方位升级并新增PyTorch支持
昆仑万维发布新版MoE大语言模型天工2.0
幻方量化发布了国内首个开源MoE大模型—DeepSeekMoE
对标OpenAI GPT-4,MiniMax国内首个MoE大语言模型全量上线





 工商网监
工商网监
评论