 Linux中awk命令的格式和匹配模式
Linux中awk命令的格式和匹配模式
1.命令简介
AWK 是文本处理语言,是一个强大的文本分析工具,是 Unix/Linux 环境中功能强大的数据处理引擎之一。数据可以来自标准输入(stdin)、一个或多个文件或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是 Unix/Linux 下一个强大的编程工具。
AWK 有很多内建的功能,比如数组、函数等,这是它和 C 语言的相同之处,灵活性是 AWK 最大的优势。简单来说 AWK 就是把文件逐行的读入,以空格和 Tab 为默认分隔符将每行切片,切开的部分再进行各种分析处理。
AWK 名称来自于它的三位创始人 Alfred Aho、Peter Jay Weinberger 和 Brian Kernighan 姓氏的首个字母。AWK 有多个版本:awk, nawk, mawk 和 gawk,未作特别说明,一般指 gawk。gawk 是 AWK 的 GNU 版本。
2.命令格式
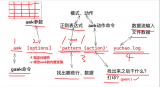
awk [OPTIONS]
awk [OPTIONS] ‘PATTERN{ACTION}’ FILE.。.
其中 PATTERN 一般为正则表达式,用斜杠括起来,用来查找匹配的行。ACTION 是在找到匹配的行时所执行的一系列命令。花括号 {} 对一系列指令进行功能分组,不需要始终出现。
尽管操作可能会很复杂,但语法总是这样。awk 通常用来格式化文本文件中的信息,是以文件的行为处理单位,每接收文件的一行,然后执行相应的命令来处理文本。
注意:
(1)PATTERN 缺省为 1,表示永真,ACTION 缺省为 print。
(2)PATTERN + {ACTION} 可以同时存在多个,每个 PATTERN 之间的关系是或,只要当前行匹配 PATTERN,则执行 PATTERN 后大括号中的 action。
3.awk 的匹配模式
awk 的 PATTERN 可能是以下情况之一:
BEGIN
END
BEGINFILE
ENDFILE
/regular expression/
relational expression
pattern && pattern
pattern || pattern
! pattern
pattern ? pattern : pattern
(pattern)
pattern1, pattern2
BEGIN 和 END 是两个特殊的模式,不会对输入的内容进行测试。BEGIN 后的 action 在 awk 读取文本前执行,END 后的 action 在 awk 结束前执行。模式表达式中的 BEGIN 和 END 模式不能与其他模式组合。
BEGINFILE 和 ENDFILE 是额外的两个特殊模式,BEGINFILE 的 action 在读取每个命令行输入文件的第一条记录之前执行,ENDFILE 的 action 在读取每个文件的最后一条记录之后执行。与 BEGIN 和 END 的区别是,如果给定多个文件,BEGINFILE 和 ENDFILE 的 action 将被执行多次,而 BEGIN 和 END 不管是否给定文件,其 action 只会执行一次。
/regular expression/ 表示正则表达式,用于选择符合指定 pattern 的行。
relational expression 表示正则表达式的关系式,即多个正则表达式通过运算符进行组合。常见组合有:
pattern && pattern
逻辑与式,两个 pattern 同时满足才算满足
pattern || pattern
逻辑或式,只要有一个 pattern 满足即满足
! pattern
逻辑非式,不符合 pattern 则为 true
pattern ? pattern : pattern
条件运算符式,第一个 pattern 满足则判断第二个 pattern,否则判断第三个 pattern
(pattern)
括号用于改变 pattern 运算的优先级
pattern1, pattern2
表示一个范围,用于选择所有记录行中第一个符合 pattern1 的记录到下一个符合 pattern2 的记录之间的记录
4.选项说明
-C, --copyright
显示版权信息并退出
-c, --traditional
是 awk 运行在兼容模式下,gawk 的任何扩展都不会生效
-d, --dump-variables[=FILE]
将 awk 排序后的全局变量的类型和值打印到指定的文件中,如果没有指定 FILE,则在当前目录默认生成一个 awkvars.out
-E, --exec FILE
功能类似于选项 -f,但脚本文件需要以 #! 开头;另外命令行的变量将不再生效
-e, --source PROGRAM_TEXT
指定 awk 的源码文件
-F, --field-separator FS
使用字符或字符串 FS 作为域分隔符。可以同时指定多个域分隔符,此时需要使用一对中括号括起来。例如使用-和|可写作 -F ‘[-|]’。如果用[]作为分隔符,可写作-F ‘[][]’。不指定分隔符,默认为空格和 Tab。注意,使用 -F‘ ’显示指定空格时,Tab 也会被作为分隔符。使用 [] 指定多个分隔符时,又想使多个分隔符组成的字符串也作为分隔符,在 [] 后添加一个 +,如 -F“[ab]+”,那么分隔符有三个,a,b 和 ab
-f, --file PROGRAM_FILE
从指定的 awk 脚本文件 PROGRAM_FILE 读取 awk 指令
-g, --gen-pot
解析 awk 程序,产生 .po(Portable Object Template) 格式的文件到标准输出,来标明程序中每一个可本地化的字符串位置
-h, --help
显示简要的帮助信息并退出
-L, --lint[=VALUE]
打印有关在其它版本 awk 中出现可疑的或不可移植结构的警告。该选项提供了一个可选的参数 fatal,即将警告视为致命的错误
-m{f|r} VAL
-mf 将最大字段数设为 VAL;-mr 将最大记录数设为 VAL。这两个功能是 Bell 实验室版awk 的扩展功能,在标准 awk 中不适用
-N, --use-lc-numeric
使用本地小数点解析输入的数据
-n, --non-decimal-data
识别输入数据中八进制和十六进制数
-O, --optimize
在程序的内部表示上启用优化。目前,这只包括简单的常量折叠。gawk 维护者希望随着时间的推移增加额外的优化
-P, --posix
打开兼容模式,会出现以下限制:
不识别 x;
当域分隔符 FS 是一个空格时,只有空格和 Tab 能作为域分隔符,换行符将不能作为一个域分隔符;
在 ? 和 : 之后,不能继续当前行;
函数关键字 func 将不能被识别;
操作符 ** 和 **= 不能代替 ^ 和 ^=;
fflush 函数无效。
-R, --command FILE
只限于 Dgawk。从文件中读取调试器命令
-r, --re-interval
允许间隔正则表达式的使用。为默认选项
-S, --sandbox
在沙盒模式下运行gawk,禁用 system() 函数,使用 getline 进行输入重定向,使用 print 和 printf 进行输出重定向,以及加载动态扩展。命令执行也被禁用,这有效地阻止了脚本访问本地资源
-t, --lint-old
打印关于不能向传统 Unix awk 移植的构造的警告
--profile[=FILE]
输出性能分析报告至指定的文件,默认输出到 awkprof.out
-V, --version
打印版本信息并退出
-v, --assign VAR=VAL
定义一个 awk 变量并赋值,可以将外部变量传递给 awk
--
标识命令选项结束
5.awk 调用方式
有三种方式调用 awk。
(1)命令行方式。
awk [-F FS] ‘PATTERN + {ACTION}’ FILE.。.
在 awk 中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指明域分隔符的情况下,默认为空格和 Tab。
(2)Shell 脚本方式。
将所有的 awk 命令插入一个文件,脚本中在首行注明使用 awk 命令来解析执行,相当于将 Shell 脚本首行的#!/bin/sh换成#!/bin/awk,最后通过键入脚本名称来调用。
(3)将所有的 awk 命令插入到一个单独文件,然后使用 -f 选项调用。
awk -f awk-script-file FILE.。.
其中,-f 选项加载 awk-script-file 中的 awk 脚本,FILE… 跟上面的是一样的。
6.awk 内置变量
gawk 有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出常见的内置变量说明。
$0 当前处理行
$n 当前记录的第 n 个字段,n 从 1 开始,字段间由 FS 分隔
ARGC 命令行参数个数
ARGIND 当前处理命令行中的第几个文件,文件下标从 0 开始
ARGV 命令行参数数组
CONVFMT 数字转换格式,默认值为%.6g
ENVIRON 支持队列中系统环境变量的使用
ERRNO 最后一个系统错误的描述
FIELDWIDTHS 字段宽度列表(用空格键分隔)
FILENAME awk浏览的文件名
FNR 当前被处理文件的记录数
FS 设置输入域分隔符,等价于命令行-F选项
IGNORECASE 如果为真,则进行忽略大小写的匹配
LINT 动态控制--lint选项是否生效,为false不生效,为true则生效;
NF 浏览记录的域的个数
NR 已读的记录数
OFMT 数字的输出格式,默认值是%.6g
OFS 输出域分隔符
ORS 输出记录分隔符
RS The input record separator,输入记录的分隔符,默认为换行符
RT The record terminator,输入记录的结束符
RSTART 由 match 函数所匹配的字符串的第一个位置
RLENGTH 由 match 函数所匹配的字符串的长度
SUBSEP 数组下标分隔符(默认值是 34)
TEXTDOMAIN awk 程序所使用的文本所处的地域
7.awk 编程示例
7.1 基础打印输出
(1)假设 last -n 5 的输出如下:
root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
如果只是显示最近登录的5个帐号:
last -n 5 | awk ‘{print $1}’
root
root
root
dmtsai
root
awk 工作流程是这样的:读入有换行符分隔的一条记录,然后将记录按指定的域分隔符划分,$0则表示所有域,$1表示第一个域,$n表示第 n 个域。默认域分隔符是空格或 Tab 符,所以$1表示登录用户,$3表示登录用户 ip,以此类推。
(2)如果想显示 /etc/passwd 配置文件中的账户以及账户对应的 Shell,而账户与 Shell 之间以Tab符分隔。
cat /etc/passwd |awk -F ‘:’ ‘{print $1“ ”$7}’
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
注意,这里使用了 -F 指定域分隔符为冒号 :。
(3)如果只是显示 /etc/passwd 的账户和账户对应的 Shell,而账户与 Shell 之间以逗号分隔,而且在所有行添加列名 name,shell,在最后一行添加 blue,/bin/nosh。
cat /etc/passwd |awk -F ‘:’ ‘BEGIN {print “name,shell”} {print $1“,”$7} END {print “blue,/bin/nosh”}’
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
。..。
blue,/bin/nosh
awk 工作流程是这样的:先执行 BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第 n 个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
(4)搜索 /etc/passwd 有 root 关键字的所有行。
awk -F: ‘/root/’ /etc/passwd
root0root:/root:/bin/bash
上面三种是 awk 的 action 的使用示例,而这种是 pattern 的使用示例,匹配了 pattern(这里是root)的行才会执行 action(没有指定 action,默认输出每行的内容)。
搜索支持正则表达式,例如找 root 开头的所有行。
awk -F: ‘/^root/’ /etc/passwd
(5)搜索/etc/passwd有 root 关键字的所有行,并显示对应的 Shell。
awk -F: ‘/root/{print $7}’ /etc/passwd
/bin/bash
这里是 awk 的 pattern+action 示例用法,同时指明了 action 是 {print $7}。
(6)打印 /etc/passwd 第三行的第一列和第二列。
awk -F: ‘NR==3{print $1,$2;}’ /etc/passwd
#输出结果:
daemon x
7.2 awk 在每一列后添加字符串后输出
设定变量内容:
a=“/test.html /dir1 /abc.txt”
希望得到
echo $a
--exclude=/test.html --exclude=/dir1 --exclude=/abc.txt
如何用 awk 实现。
解决办法:
echo $a|awk ‘{for(i=1;i《=NF-1;++i){printf “-execute=%s ”,$i}}{print “--exclude=”$NF“”}’
#或者
echo $a|awk ‘{for(i=1;i《=NF;i++){printf “--exclude=”$i“ ”}{print “”}}’
后者是网友给出的答案,和我上面的写法差不多,只是对 printf 在使用形式上有所差别而已。第二种方法print “”用于换行,print 每次输出后默认进行换行。
7.3 Shell 编程使用 awk 浮点运算保留两位小数
a=3
b=10
c=$(awk ‘BEGIN{printf “%.2f”,’$a‘*100/’$b‘}’)
echo c:$c%
或者:
c=$(awk -v n=$a -v m=$b ‘BEGIN{printf “%.2f”,n*100/m}’)
echo c:$c%
-v表示定义awk的变量!v是variable的首字母。输出:c:30.00%。
7.4 awk 访问 Shell 变量
awk 默认是无法访问shell变量的,我所知道的有三种方法。
方法一:awk -v 选项让awk 里使用shell变量。
var0=dablelv0
var1=dablelv1
awk -v tmpVar0=$var0 -v tmpVar1=$var1 ‘BEGIN{print tmpVar0“ ”tmpVar1}’
输出:dablelv0 dablelv1
注意:BEGIN 必须大写,awk 的 {action} 必须要使用单引号括起来。
方法二:‘“$var”’
这种写法是老外常用的写法。如:
var=“test”
awk ‘BEGIN{print “’$var‘”}’
这种写法其实际是双括号变为单括号的常量,传递给了awk。
如果var中含空格,为了shell不把空格作为分格符,应该如下使用:
var=“this is a test”
awk ‘BEGIN{print “’”$var“‘”}’
方法三:export 变量,将变量设置为临时会话环境变量,仅在当前shell会话中有效。在awk中使用ENVIRON[“var”]形式访问变量。
var=“this is a test”
export $var #或者 export var
#或者
export var=“this is a test”
awk ‘BEGIN{print ENVIRON[“var”]}’
7.5 awk 执行 Shell 命令
awk 执行 Shell 命令有两种方法。
方法一:使用awk的system()函数。
export var=dablelv
awk ‘BEGIN{system(“echo $var”)}’
输出:dablelv
注意:一定要使用export将变量设置为临时环境变量,因为awk的system()实际上是新建了一个shell进程来执行给定的shell命令,否则无法访问父进程的变量。
方法二:使用使用print cmd | “/bin/bash”
var=“this is a test”
awk ‘BEGIN{print “echo ”“’”$var“‘”|“sh”}’
#或者
var=“this is a test”
awk -v varTmp=“$var” ‘BEGIN{print “echo ”varTmp|“sh”}’
输出:
this is a test
注意:
(1)指定bash的时候需要双引号括起来;
(2)方法二与方法一的区别在于方法二是将变量在awk解析后再通过管道传给shell,所以无需将变量设置为临时环境变量,因为shell接收到的变量已经是变量的值。
8.awk 常见问题
(1)awk 默认以空格和 Tab 作为域分隔符,现在只以空格为分隔符,需要使用中括号的方式,不使用中括号,则仍然会将 Tab 作为域分隔符。
# 错误的写法
awk -F‘ ’ ‘{print $1;}’ test.txt
# 正确的写法
awk -F‘[ ]’ ‘{print $1;}’ test.txt
原文标题:每天一个 Linux 命令(132):awk 命令
文章出处:【微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
Linux
+关注
关注
87文章
11304浏览量
209462
原文标题:每天一个 Linux 命令(132):awk 命令
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Linux grep命令详解
嵌入式学习-飞凌嵌入式ElfBoard ELF 1板卡-shell编程入门之提取字符并设置rtc时间
飞凌嵌入式ElfBoard ELF 1板卡-shell编程入门之提取字符并设置rtc时间
Linux系统中shell命令解析

Linux lsof命令的基本用法





 工商网监
工商网监
评论