 浅析特征提取网络与特征融合技术
浅析特征提取网络与特征融合技术
导读鉴于显著性目标和伪装目标研究的相似性,本文作者将显著性目标与伪装目标合在一起进行研究,文章重点是特征提取网络与特征融合技术,主要介绍了三种方法EGNet,PFANet和SINet。
在自然界中许多生物都具有“伪装”的本领,变色龙能够根据周遭的环境来调整自身颜色以达到其“伪装”的目的;狮子将身体“伪装”在草丛之中而伺机等待猎物的靠近;蝴蝶躺在与自身颜色相近的树干上一动不动以躲过天敌的伤害。生物学家将这类伪装方式称为背景匹配,即动物为避免被识别,会尝试改变其自身颜色以“完美”地融入周围环境。
如今,随着CV领域在深度学习方向上的发展,学者们把目光投向了目标检测这一领域。与通用目标检测以及显著性目标检测不一样,通用目标检测与显著性目标检测中目标与背景均有较为明显的差异性,这种差异通常情况下通过人眼也能较容易地分辨出来。但伪装目标检测中伪装目标与背景之间存在高度的相似性,因此关于伪装目标的检测显得更具挑战性。
在我看来,伪装目标的检测与通用目标检测有所区别,但和显著性目标检测有点类似,更多的是做语义分割,但不同于语义分割,伪装目标里的分割时一个二分类的问题(即前景和背景的分割)显著性目标检测把输入图像分为显著物体和背景,伪装目标是分割为伪装目标和背景。鉴于显著性目标和伪装目标研究的相似性,于是我将显著性目标与伪装目标合在一起进行研究。特征提取网络与特征融合技术是我研究的重点。
关于伪装目标研究可应用的领域十分广阔,除了其学术价值外,伪装物体检测还有助于推动诸如军事上伪装隐蔽目标的搜索探测、医学领域上病情的判断以及农业遥感中蝗虫的入侵等等。
目前,由于缺乏规模足够大的数据集,伪装物体检测的研究还不够深入,所以目前所有的研究都是基于由南开大学团队为COD任务专门构建出的COD10K数据集。
本次涉及三个方法,前两个是针对显著性目标检测所提出的,分别是EGNet和PFANet;而后面的是专门针对于伪装目标检测提出的SINet。
首先对EGNet进行介绍,EGNet,也称为边缘引导网络,顾名思义,我们知道他在保护边缘信息上做了功夫,整个方法可以分为三个步骤,第一步是提取边缘特征(PSFEM),第二步是将局部的边缘信息和全局的位置信息聚合(NLSEM),最后一步则是将特征进行平衡,得到我们想要的最后的特征(O2OGM)。
下面我们来详细看一下各个结构,首先是PSFEM。EGNet采用的结构是U-net的结构,将六个特征层,依次进行卷积的操作,然后再经过一个卷积层。从Conv3-3、Conv4-3、Conv5-3、Conv6-3四条路径分别提取目标不同层次的特征信息。其中从骨架最后一层的Conv6-3提取的特征卷积后与边缘信息结合用于O2OGM模块;Conv3-3、Conv4-3、Conv5-3、Conv6-3之间都一个从深层到上一浅层的连接(从Conv6-3开始,Conv3-3结束),用来丰富特征信息。
然后是NLSEM模块,采用骨架中的Conv-2-2提取目标的边缘特征。不使用Conv1-2是因为其太接近输入层(噪声多)并且其感受野较小,不使用Conv3-3及更深的层提取边缘特征是因为他们所得到的feature map包含的边缘信息较少,他们更多包含的是语义信息。
最后是O2OGM模块,将Conv6-3提取的显著性目标特征信息与Conv2-2提取的边缘特征结合后的特征分别与Conv3-3、Conv4-3、Conv5-3、Conv6-3每层提取的显著性目标特征进行融合,即图中FF模块的操作。FF操作很简单,就是将高层特征上采样然后进行拼接的操作,就可以达到融合的效果。
PFANet的结构相对简单,采用VGG网络作为特征提取网络,然后将前两层特征称为低层特征,后三层特征称为高层特征,对他们采用了不同的方式进行特征增强,以增强检测效果。
首先是对于高层特征,先是采用了一个CPFE来增大感受野,然后再接一个通道注意力模块,即完成了对高层特征的特征增强(这里的这个CPFE,其实就是ASPP)。
然后再对经过了CPFE后的高层特征使用通道注意力(CA)。
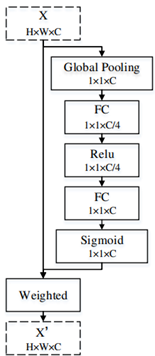
以上即是高层特征的增强方法,而对于低层特征,处理得则更为简单,只需要使用空间注意力模块(SA),即可完成。
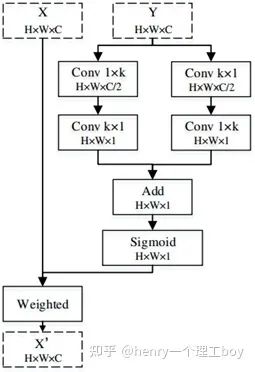
整个PFANet的网络结构很清晰,如下图所示。
介绍完EGNet和PFANet两种方法以后,就剩下SINet了。SINet的思路来自于19年的一篇CVPR的文章《.Cascaded partial decoder for fast and accurate salient object detection》。这篇文章里提出了CPD的这样一个结构,具体的可以取搜索一下这篇论文,详细了解一下。
接下来我将介绍一个用于伪装目标检测的网络SINet。假设你是一头饥肠辘辘的雄狮,此刻你扫视着周围,视线突然里出现了两匹斑马,他们就是你今天的猎物,美食。确定好了目标之后,那么就开始你的猎杀时刻。所以整个过程是你先扫视周围,我们称之为搜索,然后,就是确认目标,开始猎杀,我们称之为确认。我们的SINet就是这样的一个结构,他分为搜索和确认两个模块,前者用于搜索伪装目标,后者用于精确定位去检测他。
我们现在就具体来看看我们的SINet到底是怎么一回事。首先,我们都知道低层特征有着较多的空间细节,而我们的高层特征,却有着较多的语义信息。所以低层的特征我们可以用来构建目标区域,而高层特征我们则可以用来进行目标定位。我们将这样一张图片,经过一个ResNet的特征提取器。按照我们刚才的说法,于是我们将前两层称为低层特征,最后两层称之为高层特征,而第三层我们称之为中层特征。那么有了这样的五层特征图,东西已经给我们了?我们该怎么去利用好这些东西呢?
首先是我们的搜索模块,通过特征提取,我们得到了这么一些特征,我们希望能够从这些特征中搜索到我们想要的东西。那我们想要的是什么呢?自然就是我们的伪装线索了。所以我们需要对我们的特征们做一些增强的处理,来帮助我们完成搜索的这样一个任务。而我们用到的方法就是RF。我们来看一下具体是怎么样实现的。首先我们把整个模块分为5个分支,这五个分支都进行了1×1的卷积降维,我们都知道,空洞卷积的提出,其目的就是为了增大感受野,所以我们对第一个分支进行空洞数为3的空洞卷积,对第二个分支进行空洞数为5的空洞卷积,对第3个分支进行空洞数为7的空洞卷积,然后将前四个分支的特征图拼接起来,这时候,我们再采用一个1×1卷积降维的操作,与第五个分支进行相加的操作,最后输出增强后的特征图。
这个RF的结构来自于ECCV2018的一篇论文《 Receptive field block net for accurate and fast object detection》,其作用就是帮助我们获得足够的感受野。
我们用RF对感受野增大来进行搜索,那么搜索过后,我们得到了增强后的候选特征。我们要从候选特征得到我们最后要的伪装目标的检测结果,这里我们用到的方法是PDC模块(即是部分解码组件)。
具体操作是这样的,所以接下来就应该是对它们进行处理了逐元素相乘方式来减少相邻特征之间的差距。我们把RF增强后的特征图作为输入,输入到网络里面。首先对低层的进行一个上采样,然后进行3×3的卷积操作(这里面包含了卷积层,BN层还有Relu层),然后与更高一层的特征图进行乘法的这样一个操作,我们为什么使用逐元素相乘呢?因为逐元素相乘方式能减少相邻特征之间的差距。然后我们再与输入的低层特征进行拼接。
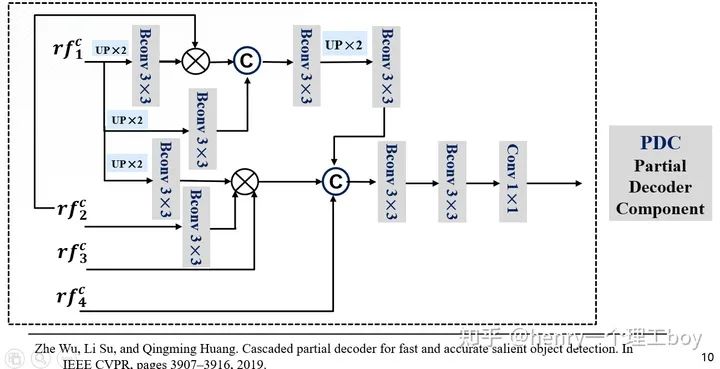
我们前面提到了,我们利用增强后的特征通过PDC得到了我们想要得到的检测结果,但这样的一个结果足够精细吗?其实,这样得到的检测结果是比较粗略的。这是为什么呢?这是因为我们的特征之间并不是有和伪装检测不相关的特征?对于这样的多余的特征,我们要消灭掉。我们将前面得到的检测图称之为 ,而我们要得到精细的结果图 ,就得使用我们的注意力机制了。这里我们引入了搜索注意力,具体是怎么实现的呢?大家想一想我们前面把特征分成了低层特征、高层特征还有中层特征。我们平时一般都叫低层特征和高层特征,很少有提到中层特征的。其实我们这里这样叫,是有打算的,我们认为中层特征他既不像低层特征那么浅显,也不像高层特征那样抽象,所以我们对他进行一个卷积操作(但是我们的卷积核用的是高斯核函数方差取32,核的尺寸我们取为4,我们学过数字图像处理,都知道这样的一个操作能起到一个滤波的作用,我们的不相关特征能被过滤掉)但是有同学就会问了,那你这样一过滤,有用的特征不也过滤掉了吗?基于这样的考虑,我们把过滤后的特征图与刚才的这个 再来做一个函数,什么函数呢?就是一个最大化函数,这样我们不就能来突出伪装图 初始的伪装区域了吗?
SINet整体的框架如图所示:
讲了这么多,我们最后来看看实验的效果,通过对这三篇文章的复现,我得到了下面的这样一些结果。
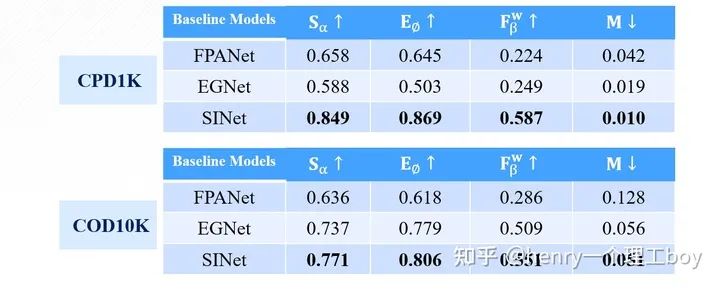
可以看出,在精度指标的评价方面,SINet相比于其他两种方法都有很大提升,而PFANet模型结构虽然很简单,但他的效果也是最差的。
下面我们再看看可视化的效果:
编辑:lyn
-
特征提取
+关注
关注
1文章
29浏览量
9875 -
深度学习
+关注
关注
73文章
5527浏览量
121879 -
特征融合
+关注
关注
0文章
3浏览量
1916
原文标题:详解基于深度学习的伪装目标检测
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用机器学习改善库特征提取的质量和运行时间
数据准备指南:10种基础特征工程方法的实战教程

特征工程实施步骤
图像识别算法的核心技术是什么
卷积神经网络通常包括哪几层
BP神经网络在语言特征信号分类中的应用
人脸识别技术的原理介绍
如何设计人脸识别的神经网络
特征工程与数据预处理全解析:基础技术和代码示例
基于深度学习的鸟类声音识别系统
基于毫米波雷达的手势识别神经网络
咳嗽检测深度神经网络算法
如何提取、匹配图像特征点
基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法





 工商网监
工商网监
评论