 一套高性能高灵活性的硬编解码推理技术方案
一套高性能高灵活性的硬编解码推理技术方案
在基于NVIDIA平台上推理时,通常会遇到读取视频进行解码然后输入到GPU进行推理的需求。视频一般以RTMP/RTSP的流媒体,文件等形式出现。解码通常有VideoCapture/FFmpeg/GStreamer等选择,推理一般选择TensorRT。
NVIDIA已经为用户提供了基于GStreamer插件拼装的DeepStream Toolkit来解决上述需求,实现RTMP/RTSP/FileSystem到GStreamer再到TensorRT,从视频数据的输入到高性能解码推理,再到渲染编码,直到最终结果输出。端到端的屏蔽了细节,易于上手使用,用户只需要开发对应GStreamer插件即可轻易实现高性能解码推理。这个方案涵盖了服务端GPU、边缘端嵌入式设备的高性能支持。 由于项目的缘故,面临了大规模(96路)视频文件的同时处理,同时推理的模型种类有6种(Object Detection[Anchor base/Anchor free]、Instance Segmentation、Semantic Segmentation、Keypoint Detection、Classification),处理的模型约96个(分类器36个,检测分割60个)。项目需要极高的灵活度(模型种类和数量增加变化)、稳定性和高性能,考察DeepStream后发现其灵活度无法满足需求,因此针对该需求,使用FFMPEG、NVDEC(CUVID)、CUDA、TensorRT、ThreadPool、Lua等技术实现了一套高性能高灵活性的硬编解码推理技术方案,高扩展性,灵活的性能自动调整,任务调度。
解码器
VideoCapture/FFMPEG/NVDEC
VideoCapture基于FFMPEG,如果单独使用FFMPEG则可以做到更细粒度的性能控制,如果配合NVDEC则需要修改FFMPEG。
其中尤为重要的部分是:
a. 谨慎使用cvtColor,在OpenCV底层,cvtColor函数是一个多线程运行加速的函数,即使仅仅是CV_BGR2RGB这个通道交换的操作也如此。他是一个非常消耗CPU的操作。
通过上面可以观察到,具有64线程的服务器,也只能实时处理3路带有cvtColor的视频文件。没有cvtColor时,指标约为12路。也侧面反映了CPU解码效率其实很感人。 而cvtColor在CPU上运行的替代方案是sws_scale,具有灵活的性能配置选择。不过也仅仅是比cvtColor稍好一点,问题并没有得到解决。 颜色空间转换,第一个使用场景为H264解码后得到的是YUV格式图像,需要转换为BGR(这个过程在VideoCapture中默认存在sws_scale,输出图像为BGR格式)。第二个使用场景是神经网络推理所需要的转换(训练时指定为RGB格式)。 解决方案是: 1) 使用BGR进行训练,尽量避免颜色空间转换; 2) 使用FFMPEG解码,并输出YUV格式,使用CUDA把YUV格式转换为BGR,同时还进行进行标准化、BGRBGRBGR转为BBBGGGRRR等推理常有操作。实现多个步骤合并为一个cuda核,降低数据流转,提升吞吐量。例如yolov5,则可以把Focus也合并到一个cuda核中。如果需要中心对齐等操作,依旧可以把仿射变换矩阵传入到cuda核中,一次完成整个预处理流程。 下图为同时实现归一化、focus、bgr到rgb、bgrbgrbgr转bbbgggrrr共4个操作。

b. 仅考虑CPU解码,使用FFMPEG可以配合nasm编译(--enable_asm)支持CPU的SIMD流指令集(SSE、AVX、MMX),比默认VideoCapture配置的ffmpeg性能更好。同时还可以根据需要配置解码所使用的线程数,控制sws_scale、decode的消耗。
编码而言,ffmpeg可以使用preset=veryfast实现更高的速度提升于VideoWriter,设置合理的gop_size、bit_rate可以实现更加高效的编码速度、更小的编码后文件、以及更快的解码速度。
c. NVDEC是一个基于CUDA的GPU硬件解码器库,CUVID(NVENC)是编码库。
地址是:https://developer.nvidia.com/nvidia-video-codec-sdk
对于ffmpeg配合NVDEC时,需要修改libavutil/hwcontext_cuda.c:356 对于hwctx->cuda_ctx 的创建不能放到ffmpeg内部进行管理。这对于大规模(例如超过32路同时创建解码器时)是个灾难。硬件解码的一个核心就是CUcontext的管理,CUcontext应该在线程池的一个线程上下文中全局存在一个,而不是重复创建。TensorRT的模型加载时(cudaStreamCreate时),会在上下文中创建CUcontext,直接与其公用一个context即可。
对于没有合理管理CUcontext的,异步获取ffmpeg的输出数据会存在异常并且难以排查。如果大规模同时创建32个解码器,则同时执行的程序,其前后最大时长差为32秒。并且由于占用GPU显存,导致程序稳定性差,极其容易出现OOM。
frames_ctx->format指定为AV_PIX_FMT_CUDA后,解码出的图像数据直接在GPU显存上,格式是YUV_NV12,可以直接在显卡上对接后续的pipline。
在ffmpeg解码流程中,配合硬件解码,需要在avcodec_send_packet/avcodec_decode_video2之前,将codec_ctx_->pix_fmt设置为AV_PIX_FMT_CUDA,该操作每次执行都需要存在,并不是全局设置一次。
基于以上的结论为:
a) CPU编解码,使用配置了nasm的ffmpeg进行,避免使用VideoCapture/VideoWriter;
b) GPU编解码,服务器使用配置了NVDEC的ffmpeg进行,嵌入式使用DeepStream(不支持NVDEC);
c) 避免使用cvtColor,尽量合并为一个cuda kernel减少数据扭转实现多重功能。
CUDA/TensorRT
关于推理的一些优化
a. 对于图像预处理部分,通常有居中对齐操作:把图像等比缩放后,图像中心移动到目标中心。通常可以使用resize+ROI复制实现,也可以使用copyMakeBorder等CPU操作。
在这里推荐采用GPU的warpAffine来替代resize+坐标运算。原因是warpAffine可以达到一样效果,并且代码逻辑简单,而且更加容易实现框坐标反算回图像尺度。对于反变换,计算warpAffine矩阵的逆矩阵即可(使用invertAffineTransform)。GPU的warpAffine实现,也仅仅只需要实现双线性插值即可。
b. 注意计算的密集性问题。
cudaStream的使用,将图像预处理、模型推理、后处理全部加入到同一个cudaStream中,使得计算密集性增加。实现更好的计算效率,统一的流进行管理。所有的GPU操作均采用Async异步,并尽可能减少主机到显存复制的情况发生。方案是定义MemoryManager类型,实现自动内存管理,在需要GPU内存时检查GPU是否是最新来决定是否发生复制操作。取自caffe的blob类。
c. 检测器通常遇到的sigmoid操作,是一个可以加速的地方。
例如通常onnx导出后会增加一个sigmoid节点,对数据进行sigmoid变为概率后进行后处理得到结果。Yolov5为例,我们有BxHxWx [(num_classes + 5) * num_anchor]个通道需要做sigmoid,假设B=8,H=80,W=80,num_classes=80,num_anchor=3,则我们有8x80x80x255个数字需要进行sigmoid。而真实情况是,我们仅仅只需要保留confidence > threshold的框需要保留。而大于threshold的框一般是很小的比例,例如200个以内。真正需要计算sigmoid的其实只有最多200个。这之间相差65280倍。这个问题适用全部存在类似需求的检测器后处理上。 解决对策为,实现cuda核时,使用desigmoid threshold为阈值过滤掉绝大部分不满足条件的框,仅对满足的少量框进行后续计算。
d. 在cuda核中,避免使用例如1.0,应该使用1.0f。
因为1.0是双精度浮点数,这会导致这个核的计算使用了双精度计算。众所周知,双精度性能远低于单精度,更低于半精度。
线程池Thread Pool
主要利用了c++11提供的condition_variable、promise、 future、mutex、queue、thread实现。线程池是整个系统的基本单元,由于线程池的存在,轻易实现模型推理的高度并行化异步化。
使用线程池后,任务通过 commit提交,推理时序图为:
当线程池配合硬件解码后,时序图为:
此时实现了GPU运算的连续化,异步化。GPU与CPU之间没有等待。
资源管理的RAII机制
Resource Acquisition Is Initialization
在C++中,使用RAII机制封装后,具有头文件干净,依赖简单,管理容易等好处。
其要点在于:第一,资源创建即初始化,创建失败返回空指针;第二,使用shared_ptr自动内存管理,避免丑陋的create、release,new、delete等操作;第三,使用接口模式,hpp声明,cpp实现,隐藏细节。外界只需要看到必要的部分,不需要知道细节。
头文件:interface.hpp
实现文件:interface.cpp
责任编辑:lq
-
gpu
+关注
关注
28文章
4743浏览量
128998 -
编解码器
+关注
关注
0文章
259浏览量
24242 -
流媒体
+关注
关注
1文章
194浏览量
16662
原文标题:实战 | 硬编解码技术的AI应用
文章出处:【微信号:kmdian,微信公众号:深兰科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
面对快速迭代的技术,怎能忽视设备升级的高效与灵活性?

NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案


OPSL 优势1:波长灵活性
8芯M16公头如何提升灵活性

英特尔锐炫A系列显卡为客户提供了强大的性能和灵活性

意法半导体推出一款兼备智能功能和设计灵活性的八路高边开关
编解码一体机相对于传统的编解码设备有哪些优势?

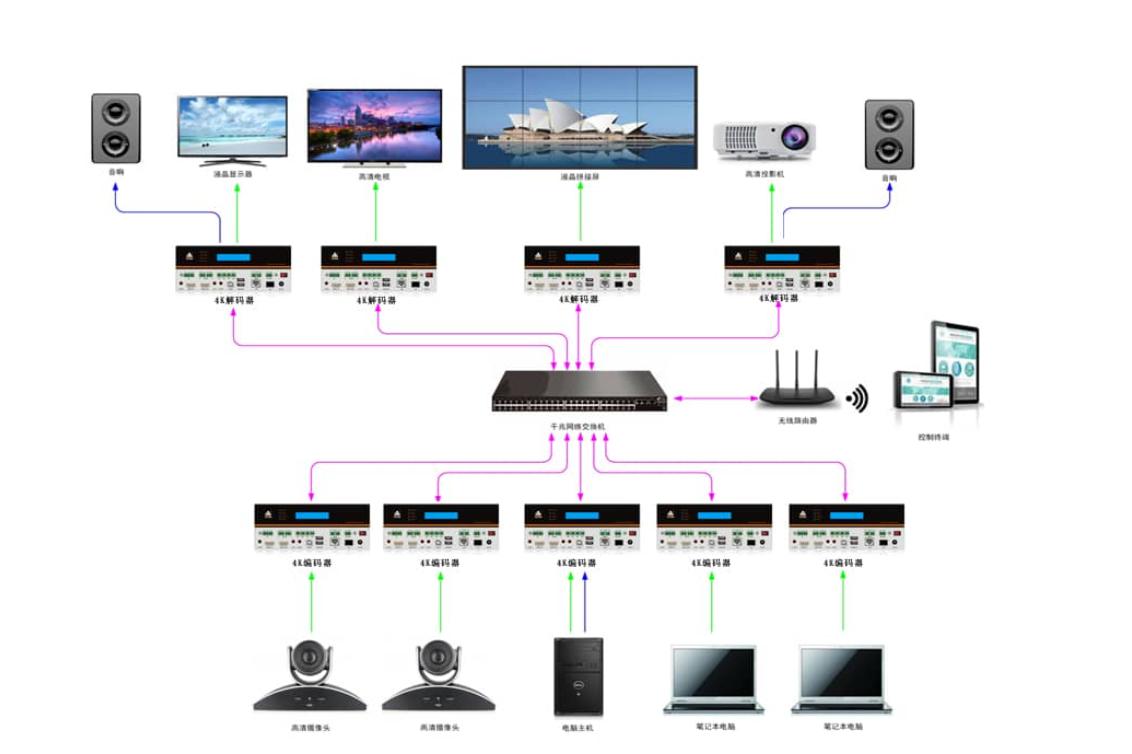
从编解码一体机看视频处理技术的未来








 工商网监
工商网监
评论