 图神经网络的知识蒸馏框架介绍
图神经网络的知识蒸馏框架介绍

随着深度学习的成功,基于图神经网络(GNN)的方法[8,12,30]已经证明了它们在分类节点标签方面的有效性。大多数GNN模型采用消息传递策略[7]:每个节点从其邻域聚合特征,然后将具有非线性激活的分层映射函数应用于聚合信息。这样,GNN可以在其模型中利用图结构和节点特征信息。然而,这些神经模型的预测缺乏透明性,人们难以理解[36],而这对于与安全和道德相关的关键决策应用至关重要[5]。此外,图拓扑、节点特征和映射矩阵的耦合导致复杂的预测机制,无法充分利用数据中的先验知识。
例如,已有研究表明,标签传播法采用上述同质性假设来表示的基于结构的先验,在图卷积网络(GCN)[12]中没有充分使用[15,31]。作为证据,最近的研究提出通过添加正则化[31]或操纵图过滤器[15,25]将标签传播机制纳入GCN。他们的实验结果表明,通过强调这种基于结构的先验知识可以改善GCN。然而,这些方法具有三个主要缺点:
(1)其模型的主体仍然是GNN,并阻止它们进行更可解释的预测;
(2)它们是单一模型而不是框架,因此与其他高级GNN架构不兼容;
(3)他们忽略了另一个重要的先验知识,即基于特征的先验知识,这意味着节点的标签完全由其自身的特征确定。为了解决这些问题,我们提出了一个有效的知识蒸馏框架,以将任意预训练的GNN教师模型的知识注入精心设计的学生模型中。学生模型是通过两个简单的预测机制构建的,即标签传播和特征转换,它们自然分别保留了基于结构和基于特征的先验知识。具体来说,我们将学生模型设计为参数化标签传播和基于特征的2层感知机(MLP)的可训练组合。另一方面,已有研究表明,教师模型的知识在于其软预测[9]。通过模拟教师模型预测的软标签,我们的学生模型能够进一步利用预训练的GNN中的知识。
因此,学习的学生模型具有更可解释的预测过程,并且可以利用GNN和基于结构/特征的先验知识。我们的框架概述如图1所示。
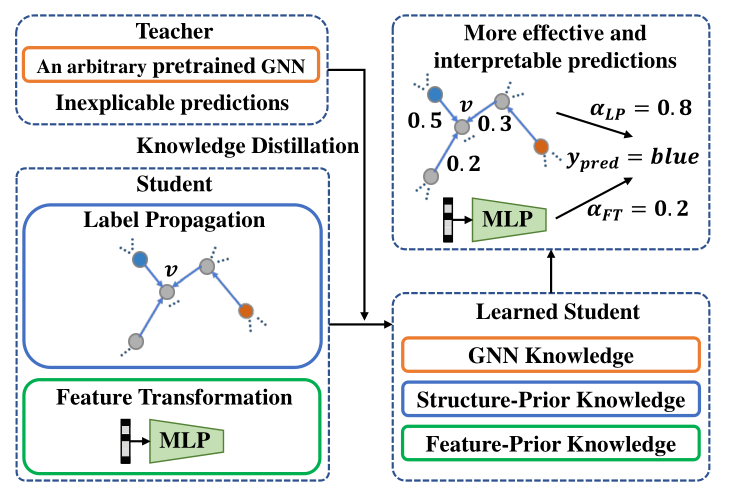
图1:我们的知识蒸馏框架的示意图。学生模型的两种简单预测机制可确保充分利用基于结构/功能的先验知识。
在知识蒸馏过程中,将提取GNN教师中的知识并将其注入学生。因此,学生可以超越其相应的老师,得到更有效和可解释的预测。我们在五个公共基准数据集上进行了实验,并采用了几种流行的GNN模型,包括GCN[12]、GAT[30]、SAGE[8]、APPNP[13]、SGC[33]和最新的深层GCN模型GCNII[4]作为教师模型。实验结果表明,就分类精度而言,学生模型的表现优于其相应的教师模型1.4%-4.7%。
值得注意的是,我们也将框架应用于GLP[15],它通过操纵图过滤器来统一GCN和标签传播。结果,我们仍然可以获得1.5%-2.3%的相对改进,这表明了我们框架的潜在兼容性。此外,我们通过探究参数化标签传播与特征转换之间的可学习平衡参数以及标签传播中每个节点的可学习置信度得分,来研究学生模型的可解释性。总而言之,改进是一致,并且更重要的是,它具有更好的可解释性。本文的贡献总结如下:
我们提出了一个有效的知识蒸馏框架,以提取任意预训练的GNN模型的知识,并将其注入学生模型,以实现更有效和可解释的预测。
我们将学生模型设计为参数化标签传播和基于特征的两层MLP的可训练组合。因此,学生模型有一个更可解释的预测过程,并自然地保留了基于结构/特征的先验。因此,学习的学生模型可以同时利用GNN和先验知识。
五个基准数据集和七个GNN教师模型上的实验结果表明了我们的框架有效性。对学生模型中学习权重的广泛研究也说明了我们方法的可解释性。
2 方法
在本节中,我们将从形式化半监督节点分类问题开始,并介绍符号。然后,我们将展示我们的知识蒸馏框架,以提取GNN的知识。然后,我们将提出学生模型的体系结构,该模型是参数化标签传播和基于特征的两层MLP的可训练组合。最后,我们将讨论学生模型的可解释性和框架的计算复杂性。
2.1 半监督节点分类
我们首先概述节点分类问题。给定一个连通图和一个标记点集,其中师节点集,是边集,节点分类的目标是为每个节点无标记点集中的节点预测标签。每个节点拥有标签,其中是所有可能的标签集合。此外,图数据通常拥有节点特征,并且可以利用特征来提升分类准确率。每行矩阵的每行表示节点的维特征向量。
2.2 知识蒸馏框架
基于GNN的节点分类方法往往是一个黑盒,输入图结构、标记点集和节点特征,输出分类器。分类器将预测无标记点的标签为的概率,其中。对于标记节点,如果的标签为,那么,其余标签。简化起见,我们使用表示所有标签的概率分布。在本文中,我们框架里的教师模型可以使用任意GNN,例如GCN[12]或GAT[30]。我们称教师模型里的预训练分类器为。另一方面,我们使用表示学生模型,是参数,表示学生模型对节点v的预测概率分布。在知识蒸馏[9]的框架中,训练学生模型使其最小化与预训练教师模型的软标签预测,使得教师模型里的潜在知识被提取并注入学生模型中。因此,优化目标是对齐学生模型和与训练教师模型的输出,可以形式化为:
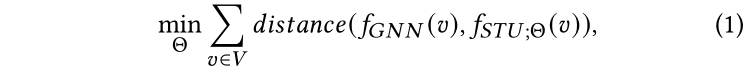
其中度量两个预测概率分布之间的距离。特别地,本文使用欧氏距离。(注:我们还尝试最小化KL散度或最大化交叉熵。但是我们发现欧几里得距离的效果最好,并且在数值上更稳定。)
2.3 学生模型架构
我们假设节点的标签预测遵循两种简单的机制:(1)从其相邻节点传播标签;(2)从其自身特征进行转换。因此,如图2所示,我们将学生模型设计为这两种机制的组合,即参数化标签传播(PLP)模块和特征转换(FT)模块,它们可以自然地分别保留基于结构的先验知识和基于特征的先验知识。蒸馏后,学生将通过更易于解释的预测机制从GNN和先验知识中受益。
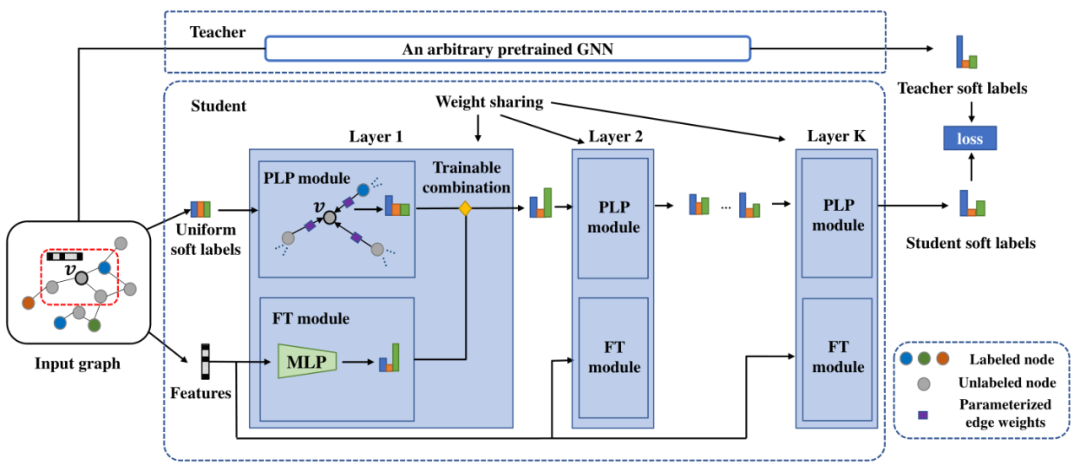
图2:我们建议的学生模型的架构图。以中心节点为例,学生模型从节点的原始特征和统一的标签分布作为软标签开始,然后在每一层,将的软标签预测更新为来自的邻居的参数化标签传播(PLP)和的特征变换(FT)的可训练组合。最终,将使学生与经过训练的教师的软标签预测之间的距离最小化。在本小节中,我们将首先简要回顾传统的标签传播算法。然后,我们将介绍我们的PLP和FT模块及其可训练的组合。
2.3.1 标签传播
标签传播(LP)[40]是基于图的经典半监督学习模型。该模型仅遵循以下假设:由边连接(或占据相同流形)的节点极有可能共享相同的标签。基于此假设,标签将从标记的节点传播到未标记的节点以进行预测。正式地,我们使用表示LP的最终预测,使用表示k轮迭代后的LP预测。在这个工作中,如果是标记节点,我们将对节点的预测初始化为一个独热编码向量。否则,我们将为每个未标记的节点设置均匀分布,这表明所有类的概率在开始时都是相同的。初始化可以形式化为:
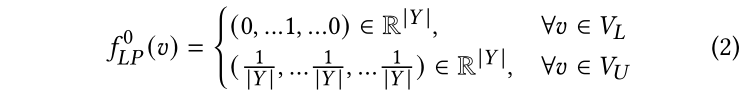
其中,是节点在第次迭代中的预测概率分布。在第k+1次迭代时,LP将按照如下方式更新无标记节点的预测:
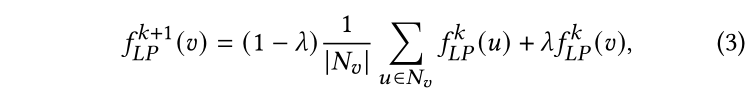
其中,时节点的邻居集合,是控制节点更新平滑度的超参。注意LP没有需要训练的参数,因此以端到端的方式不能拟合教师模型的输出。因此,我们通过引入更多参数来提升LP的表达能力。
2.3.2 参数化标签传播模块
现在,我们将通过在LP中进一步参数化边缘权重来介绍我们的参数化标签传播(PLP)模块。如等式3所示,LP模型在传播过程中平等对待节点的所有邻居。但是,我们假设不同邻居对一个节点的重要性应该不同,这决定了节点之间的传播强度。更具体地说,我们假设某些节点的标签预测比其他节点更“自信”。例如,一个节点的预测标签与其大多数邻居相似。这样的节点将更有可能将其标签传播给邻居,并使它们保持不变。形式化来说,我们将给每个节点v设置一个置信度分数。在传播过程中,所有节点的邻居和自身将把他们的标签传播给。基于置信值越大,边缘权值越大的直觉,我们为重写了等式3中的预测更新函数如下:
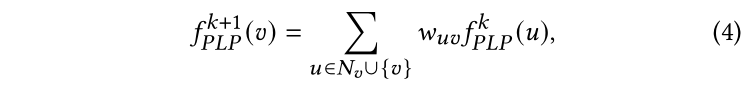
其中是节点和节点的边权,通过下面的函数计算:
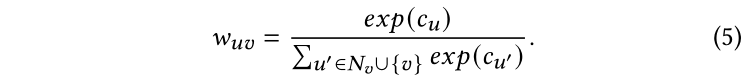
与LP相似,按照等式2初始化,在传播过程中,每个标记点的仍然保持独热真实编码向量。注意,作为可选项,我们可以进一步参数化置信度分数用于归纳设置:
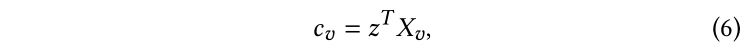
其中,是一个可学习参数,将节点的特征映射为置信度分数。
2.3.3 特征转换模块
注意,通过边缘传播标签的PLP模块强调了基于结构的先验知识。因此,我们还引入了特征变换(FT)模块作为补充预测机制。FT模块仅通过查看节点的原始特征来预测标签。形式化来说,用表示FT模块的预测,我们使用两层MLP后接一个softmax函数来将特征转换为软标签预测:
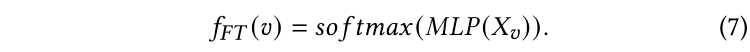
注:虽然单层逻辑回归更具可解释性,但我们发现两层逻辑回归对于提高学生的模型能力是必要的。
2.3.4 可训练组合
现在我们将结合PLP和FT模块作为我们的完整学生模型。细节上,我们将为每个节点学习一个可训练参数,来平衡PLP和FT之间的预测。换句话说,FT和PLP的预测将在每个传播步骤合并。我们将合并后的完整模型命名为CPF,等式4中的每个无标记节点的预测更新公式可以重新写做:
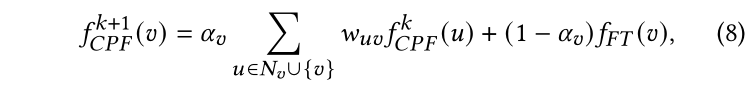
其中边权和初始化与PLP模块一致。根据是否按照等式6参数化置信度分数,模型有两个变体,分别是归纳模型CPF-ind和转导模型CPF-tra。
2.4 整体算法与细节
假设我们的学生模型一共有K层,等式1中的蒸馏目标可以进一步写为:
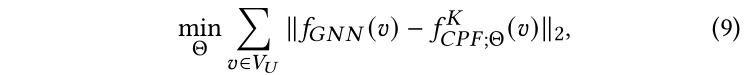
其中,是范数,参数集合包括PLP和FT之间的平衡参数,PLP模块内部的置信度参数(或归纳设置下的参数),以及FT模块中MLP的参数。还有一个重要的超参数:传播层数。
2.5 对模型可解释性与计算复杂性的讨论
在本小节中,我们将讨论学习的学生模型的可解释性和算法的复杂性。经过知识蒸馏后,我们的学生模型CPF会将特定节点的标签作为标签传播和基于特征的MLP的预测之间的加权平均值进行预测。平衡参数指示基于结构的LP还是基于特征的MLP对于节点的预测更重要。LP机制几乎是透明的,我们可以轻松地找出节点在每个迭代中受哪个邻居影响的程度。另一方面,对基于特征的MLP的理解可以通过现有工作[21]或直接查看不同特征的梯度来获得。因此,学习过的学生模型比GNN教师具有更好的解释性。算法每次迭代(算法1的第3行到第13行)的时间复杂度和空间复杂度都是,这和数据集的规模线性相关。事实上,操作可以简单写成矩阵形式,对于真实数据集的训练过程,使用单GPU可以在几秒内完成。因此,我们提出的知识蒸馏框架的时间、空间效率都很高。
3 实验
在本节中,我们将从介绍实验中使用的数据集和教师模型开始。然后,我们将详细介绍教师模型和学生变体的实验设置。之后,我们将给出评估半监督节点分类的定量结果。我们还在不同数量的传播层和训练比率下进行实验,以说明算法的鲁棒性。最后,我们将提供定性案例研究和可视化效果,以更好地理解我们的学生模型CPF中的学习参数。
3.1 数据集
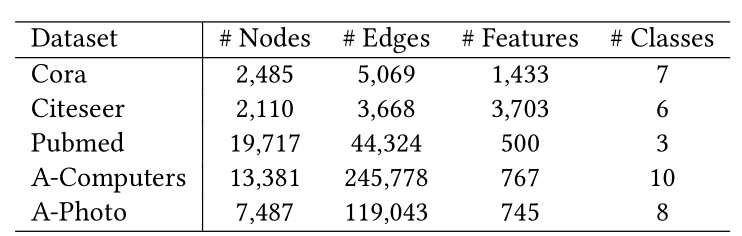
表1:数据集统计信息我们使用五个公共基准数据集进行实验,数据集的统计数据如表1所示。如以前的文献[14,24,27]所做的那样,我们仅考虑最大的连通分量,并将边视为无向边。根据先前工作[24]中的实验设置,我们从每个类别中随机抽取20个节点作为标记节点,30个用于验证节点,所有其他节点用于测试。
3.2 教师模型及其设置
为了进行全面比较,我们在我们的知识蒸馏框架中考虑了七个GNN模型作为教师模型;对于每个数据集和教师模型,我们测试下列学生变体:
PLP: 只考虑参数化标签传播机制的学生变体;
FT:只考虑特征转换机制的学生变体;
CPF-ind:归纳设置下的完整模型;
CPF-tra:转导设置下的完整模型。
3.3 分类结果分析

表2:GCN[12]和GAT[30]作为教师模型的分类准确率

表3:APPNP[13]和SGAE[8]作为教师模型的分类准确率

表4:SGC[33]和GCNII[4]作为教师模型的分类准确率
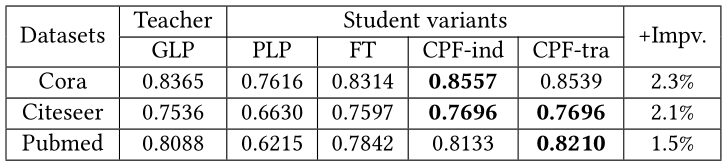
表5:GLP[15]作为教师模型的分类准确率五个数据集、七个GNN教师模型、四个学生变体模型上的实验结果在表格2,3,4,5中展示。
3.4 不同传播层数的分析
在本小节中,我们将研究关键超参数对学生模型CPF的体系结构(即传播层数)的影响。实际上,流行的GNN模型(例如GCN和GAT)对层数非常敏感。较大数量的层将导致过平滑的问题,并严重损害模型性能。因此,我们在Cora数据集上进行了实验,以进一步分析该超参数。
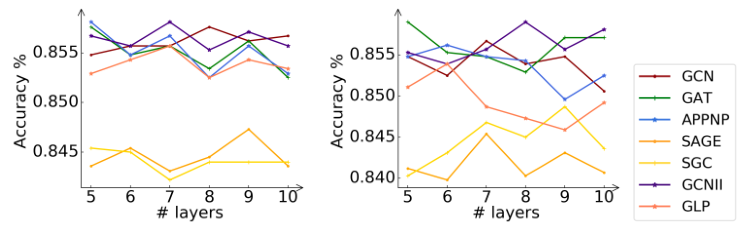
图3:Cora数据集上具有不同数量传播层的CPF-ind和CPF-tra的分类精度。图例表示指导学生的老师模式。
3.5 不同训练比例的分析
为了进一步证明该框架的有效性,我们在不同的训练比例下进行了额外的实验。具体来说,我们以Cora数据集为例,将每个类的标记节点数量从5个变化到50个。实验结果如图4所示。
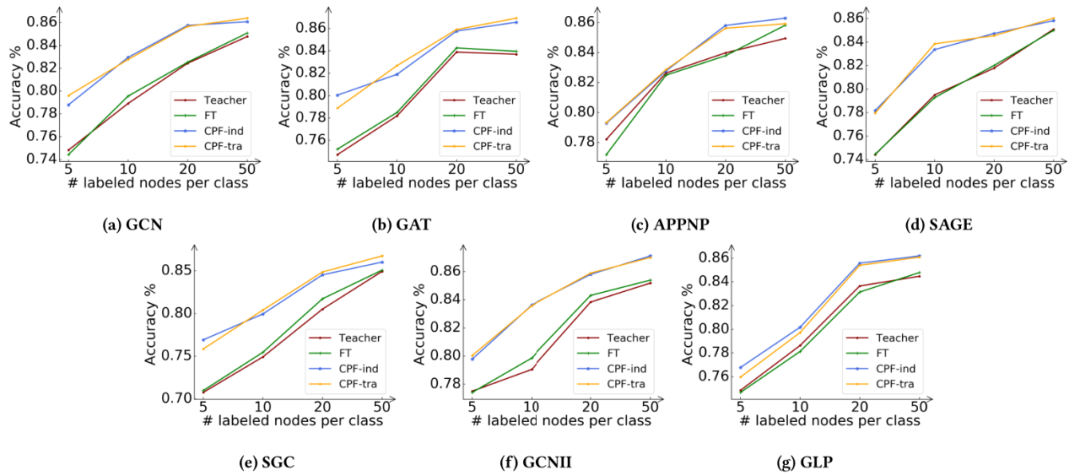
图4:Cora数据集上不同数量的标记节点下的分类精度。子标题指示相应的教师模型。
3.6 可解释性分析
现在,我们将分析学习的学生模型CPF的可解释性。具体来说,我们将探究PLP和FT之间的学习平衡参数以及每个节点的置信度得分。我们的目标是找出哪种节点具有最大或最小的和。在本小节中,我们将使用由GCN和GAT教师模型指导的CPF-ind学生模型在Cora数据集上进行展示。
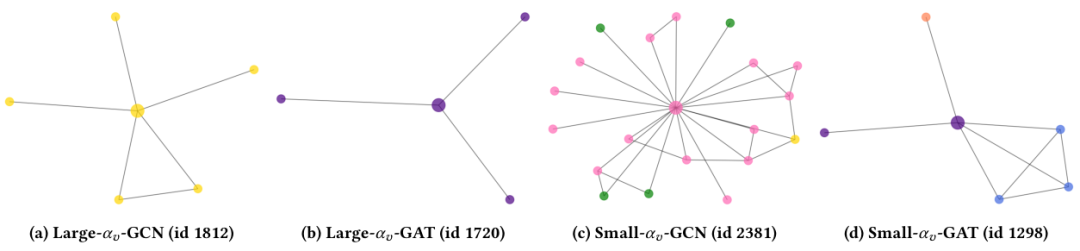
图5:用于可解释性分析的平衡参数案例研究。此处的子标题表示该节点是按GCN/GAT作为教师模型,按大或小值选择的。
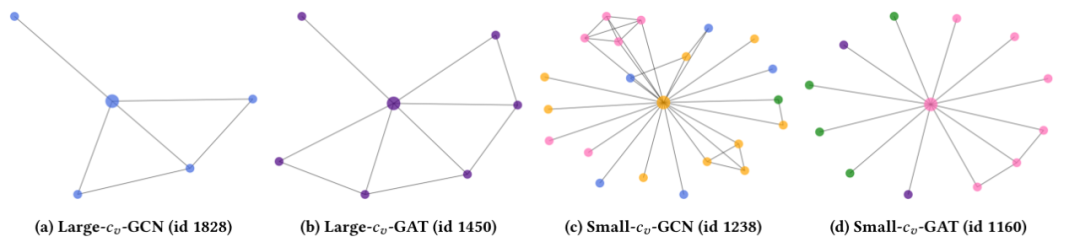
图6:用于可解释性分析的置信度得分案例研究。此处的子标题表示该节点是按GCN/GAT作为教师模型,按大或小值选择的。
4 结论
在本文中,我们提出了一种有效的知识蒸馏框架,可以提取任意预训练的GNN(教师模型)的知识并将其注入精心设计的学生模型中。学生模型CPF被建立为两个简单预测机制的可训练组合:标签传播和特征转换,二者分别强调基于结构的先验知识和基于特征的先验知识。蒸馏后,学习的学生可以利用先验知识和GNN知识,从而超越GNN老师。在五个基准数据集上的实验结果表明,我们的框架可以通过更可解释的预测过程来一致,显着地改善所有七个GNN教师模型的分类精度。
在不同数量的训练比率和传播层数上进行的附加实验证明了我们算法的鲁棒性。我们还提供了案例研究,以了解学生架构中学习到的平衡参数和置信度得分。在未来的工作中,除了半监督节点分类之外,我们还将探索将我们的框架用于其他基于图的应用。例如,无监督节点聚类任务会很有趣,因为标签传播模式在没有标签的情况下不能应用。另一个方向是改进我们的框架,鼓励教师和学生模型互相学习,以取得更好的成绩。
原文标题:【WWW2021】图神经网络的知识提取与超越:一个有效的知识蒸馏框架
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4845浏览量
108326 -
深度学习
+关注
关注
73文章
5613浏览量
124723
原文标题:【WWW2021】图神经网络的知识提取与超越:一个有效的知识蒸馏框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于神经网络的负载机械速度估计器实现方案

为什么 VisionFive V1 板上的 JH7100 中并存 NVDLA 引擎和神经网络引擎?
神经网络的初步认识

CNN卷积神经网络设计原理及在MCU200T上仿真测试
NMSIS神经网络库使用介绍
在Ubuntu20.04系统中训练神经网络模型的一些经验
CICC2033神经网络部署相关操作
人工智能工程师高频面试题汇总:循环神经网络篇(题目+答案)
液态神经网络(LNN):时间连续性与动态适应性的神经网络
神经网络的并行计算与加速技术
无刷电机小波神经网络转子位置检测方法的研究
神经网络专家系统在电机故障诊断中的应用
神经网络RAS在异步电机转速估计中的仿真研究
基于FPGA搭建神经网络的步骤解析




评论