 浅谈 声音人机交互技术
浅谈 声音人机交互技术
如果你同时保留着看电视和听广播这两个习惯——或者,看视频网站的同时会去找些播客节目听听,那么你一定会注意到一个显著的区别:视频节目的丰富程度和制作上的复杂度远高于音频节目。例如,《新闻联播》的片头20多年换了四五次,体现了电视技术的最新进步,但片头音乐一直不变,人们也能接受。电视节目的摄影棚几年就得来一次大翻新,但现在的广播电台依然可以使用十几年前的音频制作系统来播出节目,直播间里的时光仿佛停滞一般。
人类在同一时刻用眼睛可以接收的信息量远高于用耳朵能接收到的,视觉可以判别空间位置、形状和颜色叠加起来的丰富信息,比听觉高了不止一个维度。在看到人说话的时候,我们接收到的不只是话语内容,还包括人的面部特征和表情的细微变动,这都对氛围和情绪有着潜移默化的影响。相应的,听觉接收到的话语内容可以用手语或者字幕替代,但视觉附加的更多信息却难以转化回音频。
历史上,图书和报纸已经给了人们在视觉信息接收方面的训练,人们将排版经验延伸到电影和电视上。尽管留声机和电影技术几乎处于同一时代,但人们却宁愿忍受很多年没有同期声的无声电影时代,宁愿用随便什么音乐放一下做背景了事。可见,人们习惯上对图像比对声音重视得多。
同样,信息时代的到来也毫不例外的优先偏爱图像。90年代电脑同时具备独立的显卡和声卡,技术进步之后,人们对声卡抱着无所谓的态度,却追求独立显卡和屏幕的画质,以至于追求手机摄像头的精度。在交互方面,大家非常注重GUI(图形用户界面),而对于声音的设计处理一般比较马虎,还停留在很多年前的水平。
随着智能手机带来的趋势,一块巨大的触屏成为人们交互的全部载体,跑在上面的应用也随着一股奇怪的扁平化风潮而变得越来越样式单一,设计师为了与众不同又好用的界面而绞尽脑汁。对于音频而言,它终于迎来了走出冷宫的机会。人机交互的下一波趋势,将很可能在声音——而不是图像——方面迎来突破。
声音不重要,还是人们没发现它的重要?
“在汽车出现之前,人们都以为自己想要一台更快的马车。”这句话大家也许都很熟悉。在iOS 7和微软Metro界面出现之后,一夜之间各种UI设计都趋向于扁平,而流行多年的拟物化设计很快就退潮了。这表明,人们的审美态度是可以因为外界的强力驱动而受到很大的改变的,并不是一成不变。所以对音频交互也是如此:并不是说声音相对于图像而言不重要,而是需求没有得到很好的引导。
声音有什么好处?它是否有足够潜力成为不可替代的载体呢(为什么我们获得的是相反的信号,比如交通广播电台即将被打车软件的抢单声埋葬)?
首先,习惯声音交互可以让我们的感觉器官均衡利用,换句话说就是保护眼睛。长期使用手机,比如在地铁盯着屏幕或者睡觉之前刷屏,会出现很多健康问题,其实不仅限于眼睛,手持阅读介质的姿势不同,全身都可能受影响。
而且,作为必须全神贯注进行的活动,阅读(包括观看视频)需要完全沉浸进去,和外界隔离,引发的心理问题也不容忽视。不管是阅读长文还是碎片化消息,眼睛接受的信息量通常过大,人们接受了过量的信息,以至于形成信息过载而不自觉。
使用声音可以让人们强制减少信息摄入量,并更自如的利用碎片时间。对孩子而言,声音(不使用耳机)也是一种亲切自然的交互方式,有助于让孩子早期就接触电脑,而不用担心用眼,孤独等副作用。
此外,随着我们使用智能设备的“户外场景”增多,就像这个年头智能手表终于迎来了春天一样,为短信息和免提式交互量身定制的声音也会派上更大用场。户外场景其实主要就是开车或者是提着东西走路。在这种情况下,显然眼睛就只是拿来看路才更合适。
一个例子是,交通电台提交路况信息,从原来的短信平台改为用微信公众号发送语音,电台会直接播出上传的语音。这样,司机可以不停车,用蓝牙耳机播报路况,让整个交流过程更像是真正的无线电台一样。
最后,声音可以极大的帮助视障人士走入信息化。如果不是亲身接触,你根本无法想象视觉在如今的交互中占有如何举足轻重的地位。完全不用眼睛的网页浏览,必须忍受读屏软件以飞快到基本听不清的速度给你播报每一个文字和图片信息,而很多图片都没有妥当的文本标签,在没有充分无障碍化的页面,比如淘宝店铺,使用者就会完全陷入迷茫。
在帮助文本信息转语音,方便视障人士方面,腾讯可能是国内公司中尝试时间最长的公司,QQ2010正式支持读屏软件并延续至今,其他应用如QQ音乐也增加了支持。随着语音命令可用范围进一步扩大,电脑之门将会更广阔地对盲人朋友敞开。
让基于声音的人机交互变得更自然
拟人的声音交互现在来到一个艰难的瓶颈期。著名的“恐怖谷理论”认为,当机器人与人类相像超过一定程度的时候,哪怕与人类有一点点的差别,都会显得非常显眼刺目,让整个机器人显得非常僵硬恐怖,让人有面对行尸走肉的感觉。
在厂商跟风推进语音助手成为所有手机、手表的标准配置之后,它正逐步降低人们的心理障碍,培养使用习惯。如上所述,对待机器我们很自然的操作方式是“动手不动口”,对着机器说话会感觉很奇怪。但是调戏Siri或者小娜,已经一定程度上在帮我们克服这种障碍。
这就给语音助手进一步提升智能程度赢得了宝贵的时间。等到一个真正如人类一般智能的声音出现时,人们对于对着电脑倾诉,侃侃而谈,就不会太排斥,电影《Her》当中出现的恋上机器声音的情节,也会获得更多用户的共鸣。
如果一个虚拟的人类声音始终会让人心生抗拒,那最理想的办法是机器直接执行人类短促简单的语音命令。比如说你走到家门说开门,那么就只是把门打开,不会有什么多余的回应说“好的,我这就把门打开”。
另一种可行的办法是让机器用“显然不是普通人类”的声音与人交互,比如现在还有点“单字蹦”的Siri和谷歌娘,或者故意用萌化的声音说“主人回家了喵”,类似这样的方法其实就是在智能不到位的时候用装傻卖萌来补充。既然不像真人,也就没有必要感到不舒服了。
技术进步和概念创新可以互相驱动
当我们站在现在回顾iPhone出现之前的手机市场,我们会发现,现在的应用形态有很多是当年不可想象的。这当中很多更新都基于硬件交互方式的改进,比如多点触摸,GPS、NFC/RFID和各种感应器的协同作用。所以我们有同样的信心认为,只要用心去开发语音的交互功能,就会出现更多我们现在无法想象的新的交互方式。
有时候,当新的交互到来的时候,我们才会惊奇的发现为其铺垫的技术因素已经成熟;而只要出现一个合理的产品,它起到的标志性作用就会引导业界进行自主革新,提升性能和降低成本。
在声音交互方面,Siri就是一个很好的例子。它需要输入和输出技术——语音识别和文字转语音共同配合。而Siri出现的时候,这两种技术都已经到了接近能用的程度——就中文而言,语音播报不再那么“单字蹦”了,而多种第三方语音引擎的识别率更可以在安静环境下达到90%以上,并顺理成章成为众多山寨Siri的选择。它的结果就是厂商跟风推进语音助手成为所有手机、手表的标准配置。
不管是可穿戴设备,还是普通的电脑,是家庭游戏机或客厅的机顶盒,以至于智能家居和汽车,声音交互都是非常有用的。但是截至目前,人们对于它的探索还是非常被动。比如说,只有当智能手表在输入上出现障碍的时候才想到用语音输入,而并非主动的探索用语音作为屏幕显示的替代方案。所以,如果进一步整合现有技术,能够给我们带来一个具有示范作用的应用,就会显著加速业界对声音交互场景的研究。
编辑:jq
-
RFID
+关注
关注
387文章
6109浏览量
237417 -
gps
+关注
关注
22文章
2886浏览量
166053 -
nfc
+关注
关注
59文章
1617浏览量
180409
发布评论请先 登录
相关推荐
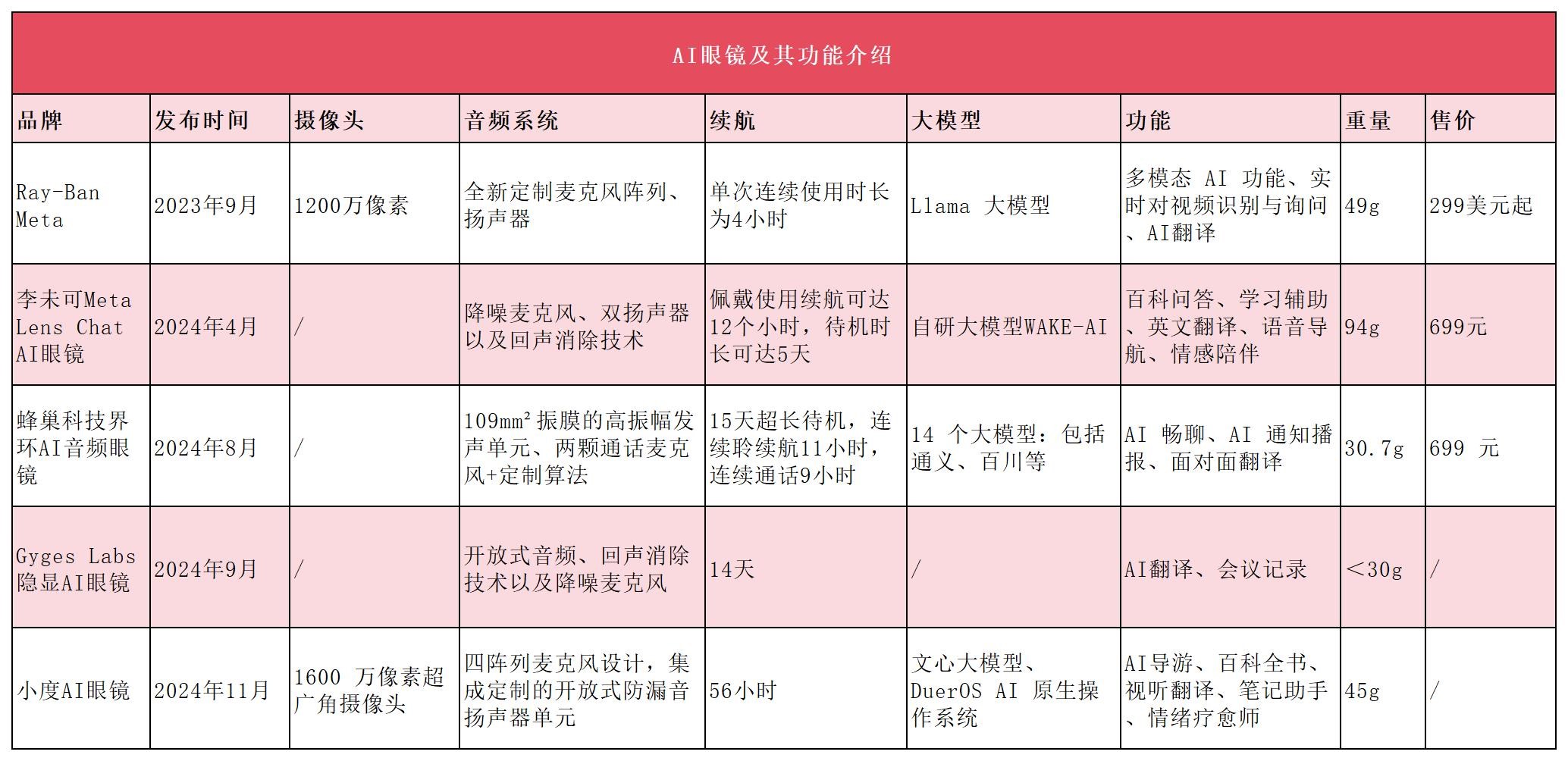
新的人机交互入口?大模型加持、AI眼镜赛道开启百镜大战
具身智能对人机交互的影响
DJN人机交互解决方案
基于传感器的人机交互技术
人机界面交互方式的介绍
人机交互界面是什么_人机交互界面的功能
工业平板电脑在人机交互中的应用
人机交互与人机界面的区别与联系
高精度 多通道 低功耗|芯海科技“压容二合一SoC”打造极致人机交互体验
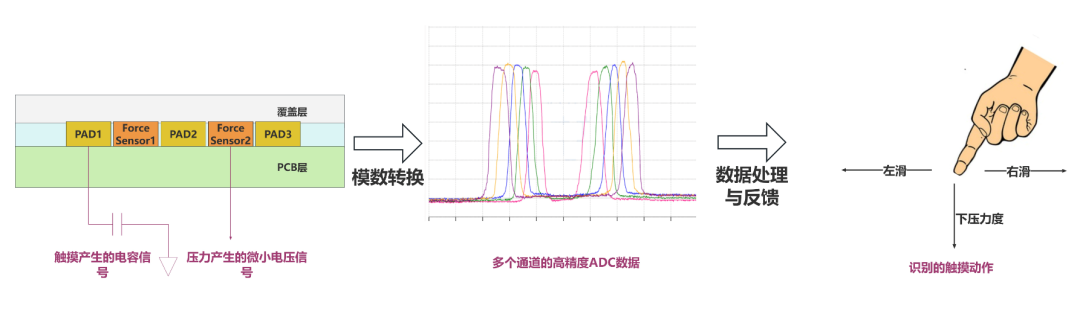
芯海科技“压容二合一SoC”系列芯片打造极致人机交互体验

人机交互系统的发展史及过程步骤





 工商网监
工商网监
评论