 简单阐述一下计算机视觉的几大任务!
简单阐述一下计算机视觉的几大任务!
计算机视觉的几大任务:
目标跟踪、图像和视频的生成
这里有一些比较常见的计算机视觉的应用,平时我们也会用到,包括多重的人脸识别,现在有些比较流行的照片应用,不知道大家平时会不会用到,包括比如像 Google photos,基本上传一张照片上去,它就会对同样的照片同样的人物进行归类,这个也是目前非常常见的一个应用。
中间那个叫 OCR,就是对文本进行扫描和识别,这个技术目前已经比较成熟了。照片上这张是比较老的技术,当时我记得有公司做这个应用,有个扫描笔,扫描一下就变成文字,现在的话,基本上已经不需要这么近的去扫描了,大家只要拍一张照片,如果这张照片是比较清晰的,经过一两秒钟,一般我们现在算法就可以直接把它转换成文字,而且准确率相当高,所以图片上的这种 OCR 是一个过时的技术。
右下角是车牌检测,开车的时候不小心压到线了,闯红灯了,收到一张罚单,这个怎么做到呢?也是计算机视觉的功劳,它们可以很容易的就去识别这个照片里的车牌,甚至车牌有一定的污损,经过计算机视觉的增强都是可以把它给可以优化回来的,所以这个技术也是比较实用的。
01. 图像识别
车牌识别、人脸识别
02. 目标检测
行人检测、车辆检测
03. 图像分割
图像语义分割、个体分割=检测+分割
视频分割:
04. 目标跟踪
下面聊几个比较有挑战性的计算机视觉的任务。首先是目标跟踪,目标跟踪就是我们在连续的图片或者视频流里面,想要去追踪某一个指定的对象,这个听起来对人来说是一个非常容易的任务,大家只要目不转睛盯着一个东西,没有人能逃脱我们的视野。
实际上对机器来说,这是一个很有挑战性的任务,为什么呢?因为机器在追踪对象的时候,大部分会使用最原始的一些方法,采取一些对目标图片进行形变的匹配,就是比较早期的计算机识别的方法,而这个方法在实际应用中间是非常难以实现的,为什么?因为需要跟踪的对象,它由于角度、光照、遮挡的原因包括运动的时候,它会变得模糊,还有相似背景的干扰,所以我们很难利用模板匹配这种方法去追踪这个对象。
一个人他面对你、背对你、侧对你,可能景象完全不一样,这种情况下,同样一个模板是无法匹配的,所以说,很有潜力但也很有挑战性,因为目前对象追踪的算法完全没有达到人脸识别的准确率,还有很多的人在不断的努力去寻找新的方法去提升。
右边也是一个例子,就是简单的一个对我们头部的追踪,也是非常有挑战性的,因为我们头可以旋转,尺度也可能发生变化,用手去遮挡,这都给匹配造成很大的难度。
05. 多模态问题
后面还有一些比较有挑战性的计算机视觉任务,我们归类把它们叫做多模态问题,其中包括 VQA,这是什么意思?这个就是说给定一张图片,我们可以任意的去问它一些问题,一般是比较直接的一些问题,Who、Where、How,类似这些问题,或者这个多模态的模型,要能够根据图片的真实信息去回答我们的问题。
举个例子,比如底下图片中间有两张是小朋友的,计算机视觉看到这张图片的时候它要把其中所有的对象全部分割出来,要了解每个对象是什么,知道它们其中的联系。比如左边的小朋友在喝奶,如果把他的奶瓶分出来以后,它必须要知道这个小朋友在喝奶,这个关系也是很重要的。
屏幕上的问题是“Where is the child sitting?”,这个问题的复杂度就比单纯的只是解析图像要复杂的多。他需要把里面所有信息的全部解析出来,并且能准确的去关联他们的关系,同时这个模型还要能够理解我们问这个问题到底是个什么用意,他要知道问的是位置,而且这个对象是这个小孩,所以这个是包含着计算机视觉加上自然语言识别,两种这种技术的相结合,所以才叫多模态问题,模态指的是像语音,文字,图像,语音,这种几种模态放在一起就叫多模态问题。
右边一个例子是 Caption Generation,现在非常流行的研究的领域,给定一张图片,然后对图片里面的东西进行描述。
编辑:jq
-
人脸识别
+关注
关注
76文章
4012浏览量
81957 -
OCR
+关注
关注
0文章
144浏览量
16382
发布评论请先 登录
相关推荐
计算机视觉的五大技术
计算机视觉的工作原理和应用
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
计算机视觉怎么给图像分类
计算机视觉的主要研究方向

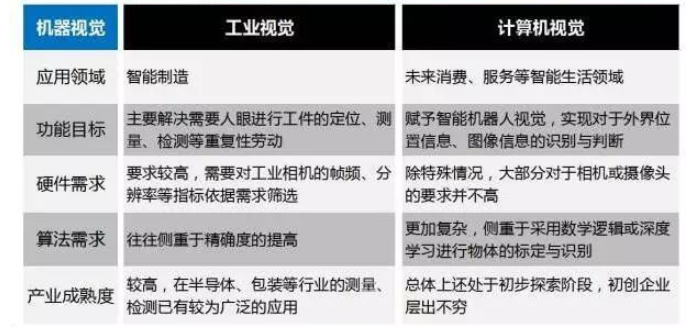
工业视觉与计算机视觉的区别





 工商网监
工商网监
评论